Ben je een leerkracht middelbaar of hoger onderwijs? Gebruik je dit handboek in je lessen (of als voorbereiding er op)? Graag krijg ik meer inzicht op wie je bent en hoe je dit boek gebruikt. Vul daarom even deze korte enquête in:
Hier zo!
Alvast bedankt!
PS Niet bang zijn, het boek blijft voor eeuwig en altijd gratis beschikbaar, ongeacht uw antwoorden :)
Je vraagt je misschien af waarom dit allemaal verteld wordt? Waarom wordt deze geschiedenisles gegeven? De reden is heel eenvoudig. Je gaat zeker geregeld zaken op het internet willen opzoeken tijdens het (leren) programmeren en zal dan ook vaker op artikels stuiten met de oude(re) naamgeving en dan mogelijks niet kunnen volgen.
Zo, je hebt besloten om C# te leren? Je bent hier aan het juiste adres. Dit boek is ontstaan als handboek voor de opleidingen professionele bachelor elektronica-ict en toegepaste informatica van de AP Hogeschool. Ondertussen wordt het ook in tal van andere hogescholen en middelbare scholen gebruikt. Ik ga je op een laagdrempelige manier leren programmeren in C#, waarbij geen voorkennis vereist is.
Eerst zullen we de fundering leggen en zaken behandelen zoals variabelen, loops methoden en arrays. Vervolgens zal de wonderlijke wereld van het object georiënteerd programmeren uit de doeken gedaan worden.
Je vraagt je misschien af hoe up-to-date dit boek is? Wel, het is origineel samengesteld tijdens de lockdowns in 2020... Mmm, het jaar 2020 als kwaliteitslabel gebruiken is een beetje zoals zeggen dat je wijn maakt met rioolwater. Toen eind 2021 een nieuwe versie van Visual Studio verscheen werd het tijd om dit boek grondig te updaten. De versie die je nu in handen hebt werd geüpdatet in de zomer van 2024, na reeds een grote herziening in 2022.
Net zoals spreektalen, evolueert ook de programmeertaal C# constant. Terwijl ik dit schrijf zijn we aan versie 10.0 van C# en staat versie 11 in de startblokken. Bij iedere nieuwe C#-versie worden bepaalde concepten plots veel eenvoudiger of zelfs gewoon overbodig. Een goed programmeur moet natuurlijk zowel met de oude als de nieuwe constructies kunnen werken.
Ik heb getracht een gezonde mix tussen oud en nieuw te zoeken, waarbij de nadruk ligt op maximale bruikbaarheid in je verdere professionele carrière. Je zal hier dus geen stoere, state-of-the-art C# innovaties terugvinden die enkel in heel specifieke projecten bruikbaar zijn. Integendeel. Ik hoop dat als je aan het laatste hoofdstuk bent, je een zodanige basis hebt, dat je ook zonder problemen in andere 'zustertalen' durft te duiken (zoals Java, C en C++, maar ook zelfs Python of JavaScript).
Dit boek ambieert niet om de volledige C#-taal en alles dat daar rond hangt aan te leren. Het boek daarentegen is gericht op eender wie die interesse heeft in de wondere wereld van programmeren, maar mogelijk nog nooit één letter code effectief heeft geprogrammeerd. Bepaalde concepten die ik te ingewikkeld acht voor een beginnende programmeur werden dan ook weg gelaten. Beschouw wat je gaat lezen dus maar als een gateway drug naar meer C#, meer programmeertalen en vooral meer programmeerplezier! U weze gewaarschuwd.
Voor we verder gaan wil ik je wel even waarschuwen. Dit boek gaat uit van geen enkele kennis van programmeren, laat staan C#. Daarom beginnen we bij het prille begin. Verwacht echter niet dat je aan het einde van dit boek supercoole grafische applicaties of games kunt maken. Het is zelfs zo dat we hoegenaamd geen woord gaan reppen over "windows applicaties", met knoppen en menu's enz.
Alles dat in dit boek gemaakt wordt zal uitgevoerd "in de console". Die oeroude DOS-schermen - ook wel een shell genoemd - die je nu nog vaak in films ziet wanneer hackers proberen in een erg beveiligd systeem in te breken. Deze aanpak helpt je te focussen op de essentie van het probleem, zonder afgeleid te worden door visuele elementen.
Dit boek is het resultaat van bijna een decennium C# doceren aan de AP Hogeschool (eerst nog Hogeschool Antwerpen, dan Artesis Hogeschool, dan Artesis Plantijn Hogeschool, enz.). De eerste schrijfsels verschenen op een eigen gehoste blog ("Code van 1001 Nacht", die ondertussen ter ziele is gegaan) en vervolgens kreeg deze een iets strakkere, eenduidige vorm als gitbook cursus.
Deze cursus, alsook een hele resem oefeningen en andere nuttige extra's kan je terugvinden op ziescherp.be. De inhoud van die cursus loopt integraal gelijk aan die van dit boek. Uiteraard is de kans bestaande dat er in de online versie ondertussen weer wat minder schrijffoutjes staan.
Waarom deze korte historiek? Wel, de kans is bestaande dat er hier en daar flarden tekst, code voorbeelden, of oefeningen niet origineel de mijne zijn. Ik heb getracht zo goed mogelijk aan te geven wat van waar komt, maar als ik toch iets vergeten ben, aarzel dan niet om me er op te wijzen.
Alle codevoorbeelden in deze cursus kan je zelf (na)maken met de gratis Visual Studio 2022 Community editie die je kan downloaden op visualstudio.microsoft.com.
Aardig wat mensen - grotendeels mijn eerstejaars studenten van de professionele bachelor Elektronica-ICT en Toegepaste Informatica van de AP Hogeschool - hebben me met deze cursus geholpen. Hen allemaal afzonderlijk bedanken zou me een extra pagina kosten, en ik heb de meeste al nadrukkelijk bedankt in de vorige editie van dit boek.
Een speciale dank nogmaals aan Maarten Wachters die de originele pixel-art van me maakte waar ik vervolgens enkele varianten op heb gemaakt.
Ook een bos bloemen voor collega's Olga Coutrin en Walter Van Hoof om de ondankbare taak op zich te nemen mijn vele dt-fouten uit de vorige editie te halen op nog geen week voor de deadline. Bedankt!
De trainers van Multimedi BV. die dit handboek ook gebruiken wil ik expliciet bedanken voor hun nuttige feedback op de eerste versie van dit boek, alsook om mij een extra reden te geven om dit boek in de eerste plaats uit te brengen.
Als laatste, in deze 2024 editie, een shoutout naar de leerkrachten van het middelbaar die sinds de laatste onderwijshervorming C# en OOP aan hun leerlingen mogen onderwijzen!
Veel lees-en programmeerplezier,
Tim Dams
Zomer 2024
Deze cursus wordt ook aangeboden voor de "buitenwereld". Deze online cursus zal ten allen tijde gratis voor de studenten beschikbaar zijn.
De gepubliceerde versie is identiek aan deze cursus.
Kijk op ziescherp.be waar u deze cursus op verschillende manieren kunt aanschaffen (ebook, pdf of papier, enz.)
Er zijn quasi oneindig veel boeken over C# geschreven, althans zo lijkt het. Hier een selectie van boeken met een korte bespreking waarom ik denk dat ze voor jou een meerwaarde kunnen zijn bij het leren programmeren in C#:
C# Programming van Mike McGrath: een uiterst compact, maar zeer helder en kleurrijk boekje dat ik ten stelligste aanbeveel als je wat last hebt met de materie van de eerste weken.
Microsoft Visual C# 2015: An introduction to OOP van Joyce Farrell: Niet het meest sexy boek, maar wel het meest volledige qua overlap met de leerstof van dit boek. Aanrader voor zij die wat meer in detail willen gaan en op zoek zijn naar oneindig veel potentiele examenvragen ;)
Head First C# van Andrew Stellman & Jennifer Greene: laat de ietwat bizarre, bijna kleuterachtige look and feel van de head first boeken je niet afschrikken. Ieder boek in deze serie is goud waar. De head first boeken zijn de ideale manier als je zoekt naar een alternatieve manier om complexe materie te begrijpen. Bekijk zeker ook de Head First Design Patterns en Head First Sql boeken in de reeks!
C# Unleashed van Bart De Smet: in mijn opinie dé referentie om C# tot op het bot te begrijpen. Geschreven door een Belg die bij Microsoft in Redmond aan C# werkt.
Code Complete van Steve McConnell: een referentiewerk over 'programmeren in het algemeen'. Het boek is al jaar en dag het te lezen boek als je je als programmeur wilt verdiepen in wat nu 'correct programmeren' behelst. Als je op je CV kunt zetten dat je dit boek door en door kent dan zal elk IT-bedrijf je stante pede aannemen ;)
Leren programmeren door enkele de opdrachten in dit boek te maken zal je niet ver (genoeg) brengen. Onze dikke vriend het Internet heeft echter tal van schitterende bronnen. Hier een overzicht.
Mimo Speels en vrij beperkt in gratis versie, maar ideale aanvulling op SoloLearn.
Screeps Een steam spel om te leren programmeren. Weliswaar JavaScript (nuttig voor Web Programming) maar het concept is te cool om niet hier te vermelden en zoals je zal ontdekken: leren programmeren kan je in eender welke taal, en het zal ook je andere programmeer-ervaring verbeteren. Give it a go!
Open Source Game Clones: "This site tries to gather open-source remakes of great old games in one place." Je vindt er ook tal van C# projecten terug zoals GTA 2.Klik bovenaan op "languages" en filter maar eens op C#.
Ja hoor, ze bestaan. Meer en meer professionele én beginnende programmeurs streamen terwijl te programmeren. Dit is een ideale manier om te zien hoe andere mensen problemen aanpakken. De meeste programming streamers kan je terugvinden op youtube, maar ook op Twitch zijn er steeds meer. Enkele aanraders (bekijk zeker de filmpjes uit de archieven eens):
Handmade Hero: deze programmeur heeft een volledige RPG gemaakt en het hele proces gestreamd.
Wel, wel, wie we hier hebben?! Iemand die de edele kunst van het programmeren wil leren? Dan ben je op de juiste plaats gekomen. Je gelooft het misschien niet, maar reeds aan het einde van dit hoofdstuk zal je je eerste eigen computer-applicaties kunnen maken. De weg naar eeuwige roem, glorie, véél vloeken en code herbruiken ligt voor je. Ben je er klaar voor?
De eerste stappen zijn nooit eenvoudig. Ik probeer daarom het aantal dure woorden, vreemde afkortingen en ingewikkelde schema's tot een minimum te beperken. Maar toch. Als je een nieuwe kunst wil leren zal je je handen én toetsenbord vuil moeten maken.
Wat er ook gebeurt de komende hoofdstukken: blijf volhouden. Leren programmeren is een beetje als een berg leren beklimmen waarvan je nooit de top lijkt te kunnen bereiken. Wat ook zo is. Er is geen "top", en dat is net het mooie van dit alles. Er valt altijd iets nieuws te leren! De zaken waar je de komende pagina's op gaat vloeken zullen over enkele hoofdstukken al kinderspel lijken. Hou dus vol. Blijf oefenen. Vloek gerust af en toe. En vooral: geniet van het ontdekken van nieuwe dingen!
Je hoort de termen geregeld: softwareontwikkelaar, programmeur, app-developer, enz. Allen zijn beroepen die in essentie kunnen herleid worden tot hetzelfde: programmeren. Programmeurs hebben geleerd hoe ze computers opdrachten kunnen geven (programmeren) zodat deze hopelijk doen wat je ze vraagt.
In de 21e eeuw is de term computer natuurlijk erg breed. Quasi ieder apparaat dat op elektriciteit werkt bevat tegenwoordig een computertje. Gaande van slimme lampen, tot de servers die het Internet draaiende houden of de smartwatch aan je pols. Zelfs aardig wat ijskasten en wasmachines beginnen kleine computers te bevatten.
Het probleem van computers is dat het in essentie ongelooflijk domme dingen zijn. Hoe krachtig ze ook soms zijn. Ze zullen altijd exact doen wat jij hen vertelt dat ze moeten doen. Als je hen dus de opdracht geeft om te ontploffen, schrik dan niet dat je even later naar de 112 kunt bellen.
Programmeren houdt in dat je leert praten met die domme computers zodat ze doen wat jij wilt dat ze doen.
Deze quote van John Johnson wordt door veel beginnende programmeurs soms met een scheef hoofd aanhoort. "Ik wil gewoon code schrijven!" Het is een mythe dat programmeurs constant code schrijven. Integendeel, een goed programmeur zal veel meer tijd in de "voorbereiding" tot code schrijven steken: het maken van een goed algoritme na een grondige analyse van het probleem .
Het algoritme is de essentie van een computerprogramma en kan je beschouwen als het recept dat je aan de computer gaat geven zodat deze jouw probleem op de juiste manier zal oplossen. Het algoritme bestaat uit een reeks instructies die de computer moet uitvoeren telkens jouw programma wordt uitgevoerd.
Het algoritme van een programma moet je zelf verzinnen. De volgorde waarin de instructies worden uitgevoerd zijn echter zeer belangrijk. Dit is exact hetzelfde als in het echte leven: een algoritme om je fiets op te pompen kan zijn:
Haal dop van het ventiel.
Plaats pomp op ventiel.
Begin te pompen.
Eender welke andere volgorde van bovenstaande algoritme zal vreemde - en soms fatale - fouten geven.
Wil je dus leren programmeren, dan zal je logisch moeten leren denken en een analytische geest hebben. Als je eerst tegen een bal trapt voor je kijkt waar de goal staat dan zal de edele kunst van het programmeren voor jou een...speciale aangelegenheid worden.1
1
Vanaf nu ben je trouwens gemachtigd om naar de nieuwsdiensten te mailen telkens ze foutief het woord "logaritme" gebruiken in plaats van "algoritme". Het woord logaritme is iets wat bij sommige nachtmerries uit de lessen wiskunde opwekt en heeft hoegenaamd niets met programmeren te maken. Uiteraard kan het wel zijn dat je ooit een algoritme moet schrijven om een logaritme te berekenen. Hopelijk moet een journalist nooit voorgaande zin in een nieuwsbericht gebruiken.
Om een algoritme te schrijven dat onze computer begrijpt dienen we een programmeertaal te gebruiken. Computers hebben hun eigen taaltje dat programmeurs moeten kennen voor ze hun algoritme aan de computer kunnen voeden. Er zijn tal van computertalen, de ene al wat obscuurder dan de andere. Maar wat al deze talen gelijk hebben is dat ze meestal:
ondubbelzinnig zijn: iedere opdracht of woord kan door de computer maar op exact één manier geïnterpreteerd worden. Dit in tegenstelling tot bijvoorbeeld het Nederlands waar "wat een koele kikker" zowel een letterlijke, als een figuurlijke betekenis heeft die niets met elkaar te maken heeft.
bestaan uit woordenschat: net zoals het Nederlands heeft ook iedere programmeertaal een lijst woorden die je kan gebruiken. Je gaat ook niet in het Nederlands zelf woorden verzinnen in de hoop dat je partner je kan begrijpen.
bestaan uit grammaticaregels: Enkel Yoda mag Engels in een verkeerde volgorde gebruiken. Iedereen anders houdt zich best aan de grammatica-afspraken die een taal heeft. "bal rood is" lijkt nog begrijpbaar, maar als we zeggen "bal rood jongen is gooit veel"?
Net zoals er ontelbare spreektalen in de wereld zijn, zijn er ook vele programmeertalen. C# - spreek uit 'siesjarp', soms ook cs geschreven - is er één van de vele. C# is een taal die deel uitmaakt van de .NET (spreek uit 'dotnet') . De .NET omgeving werd meer dan 20 jaar geleden door Microsoft ontwikkeld. Het fijne van C# is dat deze een zogenaamde hogere programmeertaal is. Hoe "hoger" de programmeertaal, hoe leesbaarder deze wordt voor leken omdat hogere programmeertalen dichter bij onze eigen taal aanleunen.
De geschiedenis van de hele .NET-wereld vertellen zou een boek op zich betekenen en gaan ik hier niet doen. Het is nuttig om weten dat er een gigantische bron aan informatie over .NET en C# online te vinden is2.
Het fijne van leren programmeren is dat je binnenkort op een bepaald punt gaat komen waarbij de keuze van programmeertaal er minder toe doet. Vergelijk het met het leren van het Frans. Van zodra je Frans onder knie hebt is het veel eenvoudiger om vervolgens Italiaans of Spaans te leren. Zo ook met programmeertalen. De C# taal lijkt bijvoorbeeld als twee druppels water op Java. Ook de talen waar C# van afstamt - C en C++ - hebben erg herkenbare gelijkenissen.
Zelfs JavaScript, Python en veel andere moderne talen zullen weinig geheimen voor jou hebben wanneer je aan het einde van dit boek bent.
Deze Deen krijgt een eigen sectie in dit boek. Waarom? Hij is niemand minder dan de "uitvinder" van C#. Anders Hejlsberg heeft een stevig palmares inzake programmeertalen verzinnen. Voor hij C# boven het doopvont hield bij Microsoft, schreef hij ook al Turbo Pascal én was hij de chief architect van Delphi.
Je zou denken dat hij na 3 programmeertalen wel op z'n lauweren zou rusten, maar zo werkt Anders niet. In 2012 begon hij te werken aan een JavaScript alternatief, wat uiteindelijk het immens populaire TypeScript werd. Dit allemaal om maar te zeggen dat als je één poster in je slaapkamer moet ophangen, het die van Anders zou moeten zijn.
Rechtstreeks onze algoritmen tegen de computer vertellen vereist dat we machinetaal kunnen. Deze is echter zo complex dat we tientallen lijnen machinetaal nodig hebben om nog maar gewoon 1 letter op het scherm te krijgen. Er werden daarom dus hogere programmeertalen ontwikkeld die aangenamer zijn dan deze zogenaamde machinetalen om met computers te praten.
Uiteraard hebben we een vertaler nodig die onze code zal vertalen naar de machinetaal van het apparaat waarop ons programma moet draaien. Deze vertaler is de compiler die aardig wat complex werk op zich neemt, maar dus in essentie onze code gebruiksklaar maakt voor de computer.
Merk op dat ik hier veel details van de compiler achterwege laat. De compiler is een uitermate complex element. In deze fase van je programmeursleven hoeven we enkel de kern van de compiler te begrijpen: het omzetten van C# code naar een uitvoerbaar bestand geschreven in machinetaal.
Microsoft .NET
Bij de geboorte van .NET in 2000 kwam ook de taal C#.
.NET is een framework dat bestaat uit een grote verzameling bibliotheken (class libraries) en een virtual execution system genaamd de Common Language Runtime (CLR). De CLR zal ervoor zorgen dat C# en .NET talen (bv. F# en Visual Basic.NET) kunnen samenwerken met de vele bibliotheken.
Om een uitvoerbaar bestand te maken (executable) zal de broncode die je hebt geschreven in C# worden omgezet naar Intermediate Language (IL) code. Op zich is deze IL code nog niet uitvoerbaar, maar dat is niet ons probleem.
Wanneer een gebruiker een in IL geschreven bestand wil uitvoeren dan zal de CLR achter de schermen deze code ogenblikkelijk naar machine code omzetten en uitvoeren. Dit concept noemt men Just-In-Time of JIT compilatie. De gebruiker zal dus nooit dit proces opmerken (tenzij er geen .NET framework werd geïnstalleerd op het systeem).
Microsoft heeft er een handje van weg om hun producten ingewikkelde volgnummers-of letters te geven, denk maar aan Windows 10 die de opvolger was van Windows 8 (dat had trouwens een erg goede reden; zoek maar eens op), of Windows 7 dat Windows Vista opvolgde. Het helpt ook niet dat ze geregeld hun producten een nieuwe naam geven. Zo was het binnen .NET tot voor kort erg ingewikkeld om te weten welke versie nu eigenlijk de welke was.
Microsoft heeft gelukkig recent de naamgevingen herschikt én hernoemt in de hoop het allemaal wat duidelijker te maken. Ik zal daarom even kort te bespreken waar we nu zitten.
.NET 6 (framework)
Telkens er een nieuwe .NET framework werd gereleased verscheen er ook een bijhorende nieuwe versie van Visual Studio. Vroeger had je verschillende frameworks binnen de .NET familie zoals .NET Framework, ".NET Standard", .NET Core enz. die allemaal net niet dezelfde doeleinden hadden wat het erg verwarrend maakte. Om dit te vereenvoudigen bestaat sinds 2020 enkel nog .NET gevolgd door een nummer.
Zo had je in 2020 .NET 5 en verschijnt eind 2022 .NET 7. Dit boek maakt gebruikt van .NET 6 dat verscheen samen met Visual Studio 2022...in november 2021. Je moet er maar aan uit kunnen.
C# 10
De C# taal is eigenlijk nog het eenvoudigst qua nummering. Om de zoveel tijd krijgt C# een update met een nieuwe reeks taal-eigenschappen die je kan, maar niet hoeft te gebruiken. Momenteel zitten we aan C# 10 dat werd uitgebracht samen met .NET 6.
Eind 2023 kwam .NET 8 uit en dus ook alweer een nieuwe versie van C#, namelijk versie 12. De kans is dus groot dat voorgaande zin alweer gedateerd is tegen dat je hem leest. De vernieuwingen in C# zijn niet altijd belangrijk voor beginnende programmeurs. In dit boek heb ik getracht de belangrijkste én meest begrijpbare nieuwe features uit de taal te gebruiken waar relevant. Over het algemeen gezien mag je stellen dat dit boek tot en met versie .NET 7.3 / C# versie 11 de belangrijkste zaken zal behandelen.
Je vraagt je misschien af waarom dit allemaal verteld wordt? Waarom wordt deze geschiedenisles gegeven? De reden is heel eenvoudig. Je gaat zeker geregeld zaken op het internet willen opzoeken tijdens het (leren) programmeren en zal dan ook vaker op artikels stuiten met de oude(re) naamgeving en dan mogelijks niet kunnen volgen.
Je gaat in dit boek leren programmeren met Microsoft Visual Studio 2026, een softwarepakket waar ook een gratis community versie voor bestaat. Microsoft Visual Studio (vanaf nu VS) is een pakket dat een groot deel van de tools samenvoegt die een programmeur nodig heeft. Zo zit er een onder andere een debugger, code editor en compiler in.
VS is een zogenaamde IDE ("Integrated Development Environment") en is op maat gemaakt om in C# geschreven applicaties te ontwikkelen. Je bent echter verre van verplicht om enkel C# applicaties in VS te ontwikkelen. Je kan gerust VB.NET, TypeScript, Python en andere talen gebruiken. Ook vice versa ben je niet verplicht om VS te gebruiken om te ontwikkelen. Je kan zelfs in notepad code schrijven en vervolgens compileren. Er bestaan zelfs online C# programmeer omgevingen, zoals dotnetfiddle.net.
Zoals gezegd: jouw taak als programmeur is algoritmes in C# taal uitschrijven. Je zou dit in een eenvoudige tekstverwerker kunnen doen, maar dan maak je het jezelf lastig. Net zoals je tekst in notepad kunt schrijven, is het handiger dit bijvoorbeeld in tekstverwerker zoals Word te doen: je krijgt een spellingchecker en allerlei handige extra's.
Ook voor het schrijven van computer code is het handiger om een IDE te gebruiken, een omgeving die ons zal helpen foutloze C# code te schrijven.
Het hart van Visual Studio bestaat uit de compiler die ik hiervoor besprak. De compiler zal je C# code omzetten naar de IL-code zodat je je applicatie op een computer kunnen gebruiken. Zolang je C# code niet exact voldoet aan de C# syntax en grammatica zal de compiler het vertikken een uitvoerbaar bestand voor je te genereren.
In dit boek zullen de voorbeelden steeds met de Community editie van VS gemaakt zijn. Je kan deze gratis downloaden en installeren via visualstudio.microsoft.com/vs.
Het is belangrijk bij de installatie dat je zeker de .NET desktop development workload kiest. Uiteraard ben je vrij om meerdere zaken te installeren.
In dit boek zullen we dus steeds werken met Visual Studio Community 2026. Niet met Visual Studio Code. Visual Studio code is een zogenaamde lightweight versie van VS die echter zeker ook z'n voordelen heeft. Zo is VS Code makkelijk uitbreidbaar, snel, en compact. Visual Studio vindt dankzij VS Code eindelijk ook z'n weg op andere platformen dan enkel die van Microsoft. Je kan de laatste versie ervan downloaden op: code.visualstudio.com.
Helaas heeft Microsoft besloten om in augustus 2024 Visual Studio Community voor Mac niet meer aan te bieden. Hierdoor zijn Mac-gebruikers genoodzaakt om met een andere IDE te werken, zoals Visual Studio Code of JetBrains Rider. Helaas zal deze cursus niet verder ingaan op deze alternatieven (je kan overwegen Windows via Bootcamp, Parallels of een virtuele machine te gebruiken indien je met Visual Studio wilt werken).
Na het opstarten van VS krijg je het startvenster te zien van waaruit je verschillende dingen kan doen. Van zodra je projecten gaat aanmaken zullen deze in de toekomst ook op dit scherm getoond worden zodat je snel naar een voorgaand project kunt gaan.
We zullen nu een nieuw project aanmaken, kies hiervoor "Create a new project".
Het "New Project" venster dat nu verschijnt geeft je hopelijk al een glimp van de veelzijdigheid van VS. In het rechterdeel zie je bijvoorbeeld alle Project Types staan. M.a.w. dit zijn alle soorten programma’s die je kan maken in VS. Naargelang de geïnstalleerde opties en bibliotheken zal deze lijst groter of kleiner zijn.
In dit boek zal je altijd het Project Type "Console App" gebruiken (ZONDER .NET Framework achteraan). Je vindt deze normaal bovenaan de lijst terug, maar kunt deze ook via het zoekveld bovenaan terugvinden. Zoek gewoon naar console. Let er op dat je een klein groen C# icoontje ziet staan bij het zwarte icoon van de Console app. Ook andere talen ondersteunen console applicaties, maar wij gaan natuurlijk met C# aan het werk.
Een console applicatie is een programma dat alle uitvoer naar een zogenaamde console stuurt, een shell. Je kan met andere woorden enkel tekst als uitvoer genereren. Multimedia elementen zoals afbeeldingen, geluid en video zijn dus uit den boze.
Kies dit type en klik 'Next'.
Op het volgende scherm kan je een naam ingeven voor je project alsook de locatie op de harde schijf waar het project dient opgeslagen te worden. Onthoud waar je je project aanmaakt zodat je dit later terugvindt.
Het "Solution name" tekstveld blijf je af. Hier zal automatisch dezelfde tekst komen als die dat je in het "Project name" tekstveld invult.
Geef je projectnamen ogenblikkelijk duidelijke namen zodat je niet opgezadeld geraakt met projecten zoals Project201, enz. waarvan je niet meer weet welke belangrijk zijn en welke niet.
Geef je project de naam "MijnEersteProgramma" en kies een goede locatie. Ik raad aan om de checkbox "Place solution and project in the same directory" onderaan niét aan te vinken. In de toekomst zal het nuttig zijn dat je meer dan 1 project per solution zal kunnen hebben. Lig er nog niet van wakker.
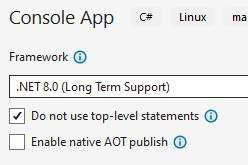
Klik op next en kies als Target Framework de meest recente versie. Duidt hier zeker de checkbox aan met "Do not use-top level statements"!!!1. Klik nu op Create.
VS heeft nu reeds een aantal bestanden aangemaakt die je nodig hebt om een ‘Console Applicatie’ te maken.
Wanneer je VS opstart zal je mogelijk overweldigd worden door de hoeveelheid menu's, knopjes, schermen, enz. Dit is normaal voor een IDE: deze wil zoveel mogelijk mogelijkheden aanbieden aan de gebruiker. Vergelijk dit met Word: afhankelijk van wat je gaat doen gebruikt iedere gebruiker andere zaken van Word. De makers van Word kunnen dus niet bepaalde zaken weglaten, ze moeten net zoveel mogelijk aanbieden.
Eens kijken wat we allemaal zien in VS na het aanmaken van een nieuw programma...
Je kan meerdere bestanden tegelijkertijd openen in VS. Ieder bestand zal z'n eigen tab krijgen. De actieve tab is het bestand wiens inhoud je in het hoofdgedeelte eronder te zien krijgt. Merk op dat enkel open bestanden een tab krijgen. Je kan deze tabbladen ook "lostrekken" om bijvoorbeeld enkel dat tabblad op een ander scherm te plaatsen.
Wie zijn heel prominent aan de rechterzijde de A.I. assistent klaar staan om je te helpen (Copilot). Je mag deze direct wegklikken (via het kruisje rechtsboven). We zullen deze straks permanent uitschakelen.
De "solution explorer" is wat we nodig hebben. Deze toont alle bestanden en elementen die tot het huidige project behoren. Als we dus later nieuwe bestanden toevoegen, dan kan je die hier zien en openen. Verwijder hier géén bestanden zonder dat je zeker weet wat je aan het doen bent!
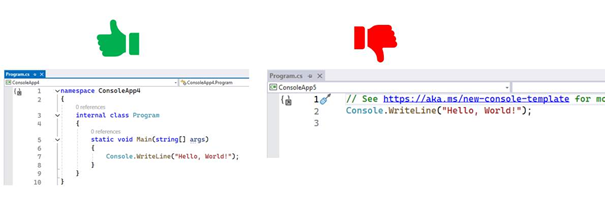
Indien je een nieuw project hebt aangemaakt en de code die je te zien krijgt lijkt in de verste verte niet op de code die je hierboven ziet dan heb je vermoedelijk een verkeerd projecttype of taal gekozen. Of je hebt de "Do not use top-level statements" checkbox niet aangeduid.
Layout kapot/kwijt/vreemd?
De layout van VS kan je volledig naar je hand zetten. Je kan ieder (deel-)venster en tab verzetten, verankeren en zelfs verplaatsen naar een ander bureaublad. Experimenteer hier gerust mee en besef dat je steeds alles kan herstellen. Het gebeurt namelijk al eens dat je layout een beetje om zeep is:
Om eenvoudig een venster terug te krijgen, bijvoorbeeld het properties window of de solution explorer: klik bovenaan in de menubalk op "View" en kies dan het gewenste venster (soms staat dit in een submenu).
Je kan ook altijd je layout in z'n geheel resetten: ga naar "Window" en kies "Reset window layout".
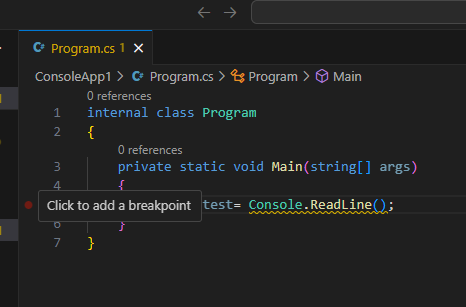
De code in Program.cs die VS voor je heeft gemaakt is reeds een werkend programma. Erg nuttig is het helaas nog niet. Je kan de code compileren en uitvoeren door op de groene driehoek bovenaan te klikken:
Als alles goed gaat krijg je nu "Hello World!" te zien en wat extra informatie omtrent het programma dat net werd uitgevoerd:
Veel doet je programma nog niet natuurlijk, dus sluit dit venster maar terug af door een willekeurige toets in te drukken.
Nee hoor. Visual Studio is lekker groot, maar laat je dat niet afschrikken. Net zoals voor het eerst op een nieuwe reisbbestemming komen, kan deze in het begin overweldigend zijn. Tot je weet waar het zwembad en de pingpongtafel staat en je van daaruit begint te oriënteren.
Sinds enkele jaren wordt de wereld overspoeld door ChatGPT & friends. De impact hiervan op de wereld valt niet weg te steken, en zeker ook niet op het beroep van ontwikkelaars. Het is dan ook logisch dat Visual Studio A.I. gestuurde tools heeft ingebouwd om het leven te vereenvoudigen. MAAR: als beginnende programmeur zijn deze tools niet altijd aanbevolen. Mijn advies is daarom om, zeker in de eerste hoofdstukken van dit boek, te leren programmeren ZONDER deze hulpmiddelen.
In deze nieuwe sectie gaan we daarom twee zaken doen:
We gaan kijken welke krachtige A.I. er in VS beschikbaar zijn (IntelliCode en Copilot), en hoe je ze kan gebruiken (mits dus de nodige waarschuwingen).
Vervolgens zal ik uitleggen hoe je deze tools best uitschakelt.
Voor we in IntelliCode en Copilot duiken willen we toch nog één keer waarschuwen omtrent A.I. nu al omarmen: je leert ook niet hoofdrekenen door vanaf dag 1 met een zakrekenmachine aan de slag te gaan.
In hoofdstuk 4 zullen we uitleggen hoe je wél op een verantwoorde manier A.I. kan gebruiken om je code te verbeteren, maar dan wel nadat je de basis onder de knie hebt.
Sinds Visual Studio 2022 heeft IntelliSense (zie hoofdstuk 7) een ongelooflijk krachtig broertje bijgekregen, genaamd IntelliCode. Deze tool zal ervoor zorgen dat je nog betere aanbevelingen krijgt van VS terwijl je aan het typen bent. Het gaat soms zo ver dat het lijkt alsof IntelliCode in je hoofd kan kijken en perfect kan voorspellen wat je wilt typen.
Wanneer je commentaar in je code schrijft en dan verder werkt dan zal IntelliCode aan de hand van je eerdere tekst code tonen die je mogelijk wou typen. Als je vervolgens op tab duwt zal de lichtgrijze tekst voor je getypt worden. Handig, knap...maar soms ook totaal verkeerde code. Wees dus erg kritisch hiermee.
Je kan IntelliCode uitzetten door via het menu bovenaan kiezen voor Tools, dan Options. Vervolgens zoek je naar "IntelliCode". Klik links op de sectie IntelliCode en schakel zeker volgende opties uit:
Onder Code Completions -> General: Copilot Completions (Single and multi-Line completions from Copilot )
Onder Code Completions -> General: IntelliCode (Whole-Line) Completions
IntelliCode werkt verrassend goed, maar is niet erg interactief. Je kan weliswaar via commentaar wat hints geven welke code je nodig zal hebben, maar voor beginnende ontwikkelaars stopt het daar. Copilot is een ander verhaal: dit is letterlijk een geavanceerde programmeur die als een soort pair programmer naast je zit en waar je alles aan kan vragen dat je nodig hebt, behalve om je een zak chips te brengen.
Bij het opstarten van VS zal je mogelijk aan de rechterzijde direct gebombardeerd worden met een venster dat Copilot vooruit duwt. Via de knop er boven kan je inloggen en vervolgens Copilot aan de tand voelen. Copilot werkt soms verbluffend goed. Misschien té goed. Het is griezelig hoe snel en juist het eenvoudige (en zelfs complexe) problemen voor je kan oplossen. Speel er gerust eens mee en verban het dan van je computer.
De programmeur van de toekomst zal béter moeten zijn dan Copilot, ChatGPT and friends (Gemini, Claude, Cursor, etc). Wie enkel op AI vertrouwt, riskeert minder kansen in de sector. Het is dus cruciaal dat je zelf de basis onder de knie hebt.
Indien je niet ingelogd bent rechtsboven dan zal Copilot niets doen. Da's eenvoudig. Ben je toch ingelogd - bijvoorbeeld om de tool op gepaste en bewuste momenten te gebruiken- dan kan je via de knop linksboven er op klikken en kiezen voor settings. Vervolgens kan je 2 zaken doen:
Beide opties hier uitschakelen.
Doorklikken op Options... en vervolgens ook daar alle opties uitschakelen.
Een console-applicatie is een programma dat zijn in- en uitvoer via een klassiek commando/shell-scherm toont. Zoals al verteld: in dat boek ga ik je enkel console-applicaties leren maken. Grafische Windows applicaties komen niet aan bod.
Een programma zonder invoer van de gebruiker is niet erg boeiend. De meeste programma's die we leren schrijven vereisen dan ook "input" (IN). We moeten echter ook zaken aan de gebruiker kunnen tonen. Denk bijvoorbeeld aan een foutboodschap of de uitkomst van een berekening tonen. Dit vereist dat er ook "output" (UIT) naar het scherm kan gestuurd worden.
Console-applicaties maken in C# vereist dat je minstens twee belangrijke C# methoden leert gebruiken:
Met behulp van Console.ReadLine() kunnen we input van de gebruiker inlezen en in ons programma verwerken.
Via Console.WriteLine() kunnen we tekst op het scherm tonen.
Sluit het eerder gemaakte "MyFirstProject" project af en herstart Visual Studio. Maak nu een nieuw console-project aan. Noem dit project Demo1. Open het Program.cs bestand via de solution Explorer (indien het nog niet open is). Veeg de code die hier reeds staat niet weg!
Voeg onder de lijn Console.WriteLine("Hello World!"); volgende code toe (vergeet de puntkomma niet):
Console.WriteLine("Hoi, ik ben het!");
Zodat je dus volgende code krijgt:
namespace Demo1
{
internal class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World!");
Console.WriteLine("Hoi, ik ben het");
}
}
}
Compileer deze code en voer ze uit: druk hiervoor weer op het groene driehoekje bovenaan. Of via het menu Debug en dan Start Debugging.
Moet ik niets bewaren?
Neen. Telkens je op de groene "build en run" knop duwt worden al je aanpassingen automatisch bewaard. Trouwens: Kies nooit voor "save as..."! want dan bestaat de kans dat je project niet meer compileert. Dit zal aardig wat problemen in je project voorkomen, geloof me maar.
Laat je niet afschrikken door wat er nu volgt. Ik gooi je even in het diepe gedeelte van het zwembad maar zal je er op tijd uithalen . Vervolgens kunnen we terug in het babybadje rustig op de glijbaan kunnen gaan spelen en C# op een trager tempo verder ontdekken.
Ik zal nu iedere lijn code kort bespreken. Sommige lijnen code zullen lange tijd niet belangrijk zijn. Onthoud nu alvast dat: alle belangrijke code staat tussen de accolades onder de lijn static void Main(string[] args)!
Lijn 1: Dit is de unieke naam waarbinnen we ons programma zullen plaatsen, en het is niet toevallig de naam van je project. Verander dit nooit tenzij je weet wat je aan het doen bent.Ik bespreek namespaces in hoofdstuk 10.
Lijn 3: Hier start je echte programma. Alle code binnen deze Program accolades zullen gecompileerd worden naar een uitvoerbaar bestand. Vanaf hoofdstuk 9 zal deze lijn geen geheimen meer hebben voor je.
Lijn 5: Het startpunt van iedere console-applicatie. Wat hier gemaakt wordt is een methode genaamd Main. Je programma kan meerdere methoden (of functies) bevatten, maar enkel degene genaamd Main zal door de compiler als het startpunt van het programma gemaakt worden. Deze lijn zal ik in hoofdstuk 7 en hoofdstuk 8 uit de doeken doen.
Lijn 7: Dit is een statement dat de WriteLine-methode aanroept van de Console-bibliotheek. Het zal alle tekst die tussen de aanhalingstekens staat op het scherm tonen.
Lijn 8: en ook deze lijn zorgt ervoor dat er tekst op het scherm komt wanneer het programma zal uitgevoerd worden.
Accolades op lijnen 2, 4, 6, 9 tot en met 10: vervolgens moet voor iedere openende accolade eerder in de code nu ook een bijhorende sluitende volgen. We gebruiken accolades om de scope aan te duiden, iets dat we in hoofdstuk 5 geregeld zullen nodig hebben.
Net zoals een recept, zal ook in C# code van boven naar onder worden uitgevoerd.
Voor ons wordt het echter pas interessant op lijn71. Dit is het startpunt van ons programma en de uitvoer ervan. Al de zaken ervoor kan je voorlopig keihard nergeren.
Het programma zal alles uitvoeren dat tussen de accolades van het Main-blok staat. Dit blok wordt afgebakend door de accolades van lijn 6 en 9. Dit wil ook zeggen dat van zodra lijn 9 wordt bereikt, dit het signaal voor je computer is om het programma af te sluiten.
Jawadde...Wat was dit allemaal?! We hebben al aardig wat vreemde code zien passeren en het is niet meer dan normaal dat je nu denkt "dit ga ik nooit kunnen". Wees echter niet bevreesd: je zal sneller dan je denkt bovenstaande code als 'kinderspel' gaan bekijken. Een tip nodig? Test en experimenteer met wat je al kunt!
Laat deze info rustig inzinken en onthoud alvast volgende belangrijke zaken:
Al je eigen code komt momenteel enkel tussen de Main accolades.
Eindig iedere lijn code daar met een puntkomma (;).
Code wordt van boven naar onder uitgevoerd.
De oerman verschijnt wanneer we een stevige stap gezet hebben en je mogelijk even onder de indruk bent van al die nieuwe informatie. Hij zal proberen informatie nog eens vanuit een ander standpunt toe te lichten en te herhalen waarom deze nieuwe kennis zo belangrijk is.
1
"Hello world" op het scherm laten verschijnen wanneer je een nieuwe programmeertaal leert is ondertussen een traditie bij programmeurs. Er is zelfs een website die dit verzamelt namelijk helloworldcollection.de. Deze site toont in honderden programmeertalen hoe je "Hello world" moet programmeren.
De WriteLine-methode is een veelgebruikte methode in Console-applicaties. Het zorgt ervoor dat we tekst op het scherm kunnen tonen.
Voeg volgende lijn toe na de vorige WriteLine-lijn in je project:
Console.WriteLine("Wie ben jij?!");
De WriteLine methode zal alle tekst tonen die tussen de aanhalingstekens (" ") staat. De aanhalingstekens aan het begin en einde van de tekst zijn uiterst belangrijk! Alsook het puntkomma helemaal achteraan.
Je code binnen de Main accolades zou nu moeten zijn:
Console.WriteLine("Hello World!");
Console.WriteLine("Hoi, ik ben het");
Console.WriteLine("Wie ben jij?!");
Kan je voorspellen wat de uitvoer zal zijn? Test het eens!
Ik toon niet telkens de volledige broncode. Als ik dat zou blijven doen dan wordt dit boek dubbel zo dik. Ik toon daarom (meestal) enkel de code die binnen de Main (of later ook elders) moet komen.
In de Console kan je met een handvol methoden reeds een aantal interessante dingen doen.
Zo kan je bijvoorbeeld input van de gebruiker inlezen en bewaren in een variabele als volgt:
Console.WriteLine("Geef je naam?");
string result;
result = Console.ReadLine();
Wat gebeurt er hier juist?
De tweede lijn code:
Concreet zeggen we hiermee aan de compiler: maak in het geheugen een plekje vrij waar enkel data van het type string in mag bewaard worden (wat deze zin exact betekent komt later. Onthoud nu dat geheugen van het type string enkel "tekst" kan bevatten).
Noem deze geheugenplek result zodat we deze later makkelijk kunnen in en uitlezen.
Derde lijn code:
Vervolgens roepen we de ReadLine methode aan. Deze methode zal de invoer van de gebruiker van het toetsenbord uitlezen tot de gebruiker op enter drukt.
Het resultaat van de ingevoerde tekst wordt bewaard in de variabele result.
Merk op dat de toekenning in C# van rechts naar links gebeurt. Vandaar dat result dus links van de toekenning (=) staat en de waarde krijgt van het gedeelte rechts ervan.
In het voorbeeld bewaren we het resultaat in result, maar dat moet niet zo noemen. In dit voorbeeld vragen we 2 zaken en bewaren deze in 2 aparte variabelen:
Console.WriteLine("Geef je naam?");
string naam;
naam = Console.ReadLine();
Console.WriteLine("Geef de naam van je mama?");
string naamMama;
naamMama = Console.ReadLine();
Je programma zou nu moeten zijn:
Console.WriteLine("Hello World!");
Console.WriteLine("Hoi, ik ben het!");
Console.WriteLine("Wie ben jij?!");
string result;
result = Console.ReadLine();
Start nogmaals je programma. Je zal merken dat je programma nu een cursor toont en wacht op invoer nadat het de eerste 3 lijnen tekst op het scherm heeft gezet. Je kan nu eender wat intypen en van zodra je op enter duwt gaat het programma verder. Maar aangezien lijn 5 de laatste lijn van ons algoritme is, zal je programma hierna afsluiten. We hebben dus de gebruiker voor niets iets laten invoeren.
Een variabele is een geheugenplekje met een naam waar we zaken in kunnen bewaren. In het volgende hoofdstuk gaan we zo vaak het woord variabele gebruiken dat je oren en ogen er van gaan bloeden. Trek je nu dus nog niet te veel aan van dit woord. We kunnen nu invoer van de gebruiker gebruiken en tonen op het scherm. De invoer hebben we bewaard in de variabele ``result`:
Console.WriteLine("Dag");
Console.WriteLine(result);
Console.WriteLine("hoe gaat het met je?");
In de tweede lijn hier gebruiken we de variabele result als parameter in de WriteLine-methode.
Met andere woorden: de WriteLine methode zal op het scherm tonen wat de gebruiker even daarvoor heeft ingevoerd.
Je volledige programma ziet er dus nu zo uit:
Console.WriteLine("Hello World!");
Console.WriteLine("Hoi, ik ben het!");
Console.WriteLine("Wie ben jij?!");
string result;
result = Console.ReadLine();
Console.WriteLine("Dag ");
Console.WriteLine(result);
Console.WriteLine("hoe gaat het met je?");
Test het programma en voer je naam in wanneer de cursor knippert.
Voorbeelduitvoer (lijn 3 is wat de gebruiker heeft ingetypt)
Hoi, ik ben het!
Wie ben jij?!
tim [enter]
Dag
tim
hoe gaat het met je?
De WriteLine-methode zal steeds een line break - een enter zeg maar - aan het einde van de lijn zetten zodat de cursor naar de volgende lijn springt.
De Write-methode daarentegen zal geen enter aan het einde van de lijn toevoegen. Als je dus vervolgens iets toevoegt met een volgende Write of WriteLine, dan zal dit aan dezelfde lijn toegevoegd worden.
Vervang daarom eens in de laatste 3 lijnen code in je project WriteLine door Write:
Console.Write("Dag");
Console.Write(result);
Console.Write("hoe gaat het met je?");
Voer je programma uit en test het resultaat. Je krijgt nu:
Hoi, ik ben het!
Wie ben jij?!
tim [enter]
Dagtimhoe gaat het met je?
Wat is er hier "verkeerd" gelopen? Al je tekst van de laatste lijn plakt zo dicht bij elkaar?
Inderdaad, ik ben spaties vergeten toe te voegen. Spaties zijn ook tekens die op scherm moeten komen - ook al zien we ze niet - en je dient dus binnen de aanhalingstekens spaties toe te voegen.
Namelijk:
Console.Write("Dag ");
Console.Write(result);
Console.Write(" hoe gaat het met je?");
Je uitvoer wordt nu:
Hoi, ik ben het!
Wie ben jij?!
tim [enter]
Dag tim hoe gaat het met je?
C# trekt zich niets aan van witregels die niét binnen aanhalingstekens staan. Zowel spaties, enters en tabs worden genegeerd. Met andere woorden: je kan het voorgaande programma perfect in één lange lijn code typen, zonder enters. Dit is echter niet aangeraden want het maakt je code een pak onleesbaarder.
Opletten met spaties
Let goed op hoe je spaties gebruikt bij WriteLine. Indien je spaties buiten de aanhalingstekens plaatst dan heeft dit geen effect.
Hier een fout gebruik van spaties (de code zal werken maar je spaties worden genegeerd):
//we visualiseren de spaties even als liggende streepjes in volgende voorbeeld
Console.Write("Dag"_);
Console.Write(result_);
Console.Write("hoe gaat het met je?");
En een correct gebruik:
Console.Write("Dag_");
Console.Write(result);
Console.Write("_hoe gaat het met je?");
We kunnen dit allemaal nog een pak korter tonen zonder dat de code onleesbaar wordt. De plus-operator (+) in C# kan je namelijk gebruiken om tekst achter elkaar te plakken. De laatste 3 lijnen code kunnen dan korter geschreven worden als volgt:
Console.WriteLine("Dag " + result + " hoe gaat het met je?");
Merk op dat result dus NIET tussen aanhalingstekens staat, in tegenstelling tot de andere stukken van de zin. Waarom is dit? Aanhalingstekens in C# duiden aan dat een stuk tekst moet beschouwd worden als tekst van het type string. Als je geen aanhalingsteken gebruikt dan zal C# de tekst beschouwen als een variabele met die naam.
Bekijk zelf eens wat het verschil wordt wanneer je volgende lijn code:
Console.WriteLine("Dag "+ result + " hoe gaat het met je?");
Vervangt door:
Console.WriteLine("Dag "+ "result" + " hoe gaat het met je?");
We krijgen dan altijd dezelfde output, namelijk:
Dag result hoe gaat het met je?
We tonen dus niet de inhoud van result, maar gewoon de tekst "result".
Je mag echter ook de variabelen al vroeger aanmaken. In C# zet men de geheugenplek creatie zo dicht mogelijk bij de code waar je die variabele gebruikt. Maar dat is geen verplichting. Dit mag dus ook:
Je zal vaak Console.WriteLine moeten schrijven als je dit boek volgt.Ik heb echter goed nieuws voor je: er zit een ingebouwde snippet in VS om sneller Console.WriteLine op het scherm te toveren.Ik ga je niet langer in spanning houden...of toch... nog even. Ben je benieuwd? Spannend he!
Hier gaan we: cw [tab] [tab]
Als je dus cw schrijft en dan twee maal op de tab-toets van je toetsenbord duwt verschijnt daar automagisch een verse lijn met Console.WriteLine();.
Je code zal pas compileren indien deze foutloos is geschreven. Herinner je dat computers uiterst dom zijn en dus vereisen dat je code 100% foutloos is qua woordenschat en grammatica.
Zolang er dus fouten in je code staan moet je deze eerst oplossen voor je verder kan. Gelukkig helpt VS je daarmee op 2 manieren:
Fouten in code worden met een rode squiggly onderlijnd.
Onderaan zie je in de statusbalk of je fouten hebt.
Laat je trouwens niet afschrikken door de gigantische reeks fouten die soms plots op je scherm verschijnen. VS begint al enthousiast fouten te zoeken terwijl je mogelijk nog volop aan het typen bent.
Als je plots veel fouten krijgt, kijk dan altijd vlak boven de plek waar de fouten verschijnen. Heel vaak zit daar de echte fout:en meestal is dat gewoon het ontbreken van een kommapunt aan het einde van een statement.
Uiteraard ga je vaak code hebben die meerdere schermen omvat. Je kan via de error-list snel naar al je fouten gaan. Open deze door op het error-icoontje onderaan te klikken:
Dit zal de "error list" openen (een schermdeel van VS dat ik aanraad om altijd open te laten én dus niet weg te klikken). Warnings kunnen we - voorlopig - meestal negeren en deze 'filter' hoef je dus niet aan te zetten.
In de error list kan je nu op iedere foutboodscap klikken om ogenblikkelijk naar de correcte lijn te gaan.
Zou je toch willen compileren en je hebt nog fouten dan zal VS je proberen tegen te houden. Lees nu onmiddellijk wat de voorman hierover te vertellen heeft.
Opletten aub : Indien je op de groene start knop duwt en bovenstaande waarschuwing krijgt KLIK DAN NOOIT OP YES EN DUID NOOIT DE CHECKBOX AAN!
Lees de boodschap eens goed na: wat denk je dat er gebeurt als je op 'yes' duwt? Inderdaad, VS zal de laatste werkende versie uitvoeren en dus niet de code die je nu hebt staan waarin nog fouten staan.
Wanneer je je cursor op een lijn met een fout zet dan zal je soms vooraan een geel error-lampje zien verschijnen (dit duurt soms even):
Je kan hier op klikken en heel vaak krijg je dan ineens een mogelijke oplossing. Wees steeds kritisch hierover want VS is niet alwetend en kan niet altijd raden wat je bedoelt. Neem dus het voorstel niet zomaar over zonder goed na te denken of het dat was wat je bedoelde.
Warnings kan je voorlopig over het algemeen negeren . Bekijk ze gewoon af en toe. Wie weet bevatten ze nuttige informatie om je code te verbeteren.
Je kan in console-applicaties zelf bepalen in welke kleur nieuwe tekst op het scherm verschijnt. Je kan zowel de kleur van het lettertype instellen (via ForegroundColor) als de achtergrondkleur (BackgroundColor).
Je kan met de volgende expressies de console-kleur veranderen, bijvoorbeeld de achtergrond in blauw en de letters in groen:
Vanaf dan zal alle tekst die je hierna met WriteLine en Write naar het scherm stuurt met deze kleuren werken. Merk op dat we bestaande tekst op het scherm niét van kleur kunnen veranderen zonder deze eerst te verwijderen en dan opnieuw, met andere kleurinstellingen, naar het scherm te sturen.
Alle kleuren die beschikbaar zijn staan beschreven in ConsoleColor deze zijn: Black, DarkBlue, DarkGreen, DarkCyan, DarkRed, DarkMagenta, DarkYellow, Gray, DarkGray, Blue, Green, Cyan, Red, Magenta, Yellow.
Wens je dus de kleur Red dan zal je deze moeten aanroepen door er ConsoleColor. voor te zetten: ConsoleColor.Red.
Waarom is dit? ConsoleColor is een zogenaamd enum-type. Enums leggen we verderop in hoofdstuk 5 uit.
Een voorbeeld:
Console.WriteLine("Tekst in de standaard kleur");
Console.BackgroundColor = ConsoleColor.Yellow;
Console.ForegroundColor = ConsoleColor.Black;
Console.WriteLine("Zwart met gele achtergrond");
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("Rood met gele achtergrond");
Als je deze code uitvoert krijg je als resultaat:
Kleur in console gebruiken is nuttig om je gebruikers een minder eentonig en meer informatieve applicatie aan te bieden. Je zou bijvoorbeeld alle foutmeldingen in het rood kunnen laten verschijnen. Let er wel op dat je applicatie geen aartslelijk programma wordt.
Hou er ook rekening mee dat niet iedereen (alle) kleuren kan zien. In de vorige editie van dit boek gebruikte ik rode letters op een groene achtergrond. Dat resulteerde in onleesbare tekst voor mensen met Daltonisme.
Soms wil je terug de originele applicatie-kleuren hebben. Je zou manueel dit kunnen instellen, maar wat als de gebruiker slechtziend is en in z'n besturingssysteem andere kleuren als standaard heeft ingesteld?!
De veiligste manier is daarom de kleuren te resetten door de Console.ResetColor() methode aan te roepen zoals volgend voorbeeld toont:
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("Error!!!! Contacteer de helpdesk");
Console.ResetColor();
Console.WriteLine("Het programma sluit nu af");
Om een werkend C#-programma te maken moeten we de C#-taal beheersen. Net zoals iedere taal bestaat ook C# uit:
grammatica: in de vorm van de C# syntax
woordenschat: in de vorm van gereserveerde keywords.
Een C#-programma bestaat uit een opeenvolging van instructies, statements genoemd. Statements eindigen steeds met een puntkomma. Net zoals ook in het Nederlands een zin meetal eindigt met een punt. Ieder statement kan je vergelijken als één lijn in ons recept, het algoritme.
De volgorde van de woorden in C# zijn niet vrijblijvend en moeten aan grammaticale regels voldoen '(de syntax). Enkel indien alle statements correct zijn zal het programma gecompileerd worden naar een werkend programma.
Enkele belangrijke regels van C#:
Hoofdlettergevoelig: C# is hoofdlettergevoelig. Dat wil zeggen dat hoofdletter R en kleine letter r totaal verschillende zaken zijn voor C#. Reinhardt en reinhardt zijn dus ook niet hetzelfde.
Statements afsluiten met puntkomma (; ): Doe je dat niet dan zal C# denken dat de regel gewoon op de volgende lijn doorloopt en zal deze dan als één (fout) geheel proberen te compileren.
Witruimtes: Spaties, tabs en enters worden door de C# compiler genegeerd. Je kan ze dus gebruiken om de layout van je code (bladspiegel) te verbeteren. De enige plek waar witruimtes wél een verschil geven is tussen aanhalingstekens " " die we later zullen leren gebruiken.
Commentaar toevoegen kan: door // voor een enkele lijn te zetten zal deze lijn genegeerd worden door de compiler. Je kan ook meerdere lijnen code in commentaar zetten door er /* voor en */ achter te zetten.
Je code begint altijd in de Main-methode!!!
Van boven naar onder: je code wordt van boven naar onder uitgevoerd en zal enkel naar andere plaatsen springen als je daar expliciet in je code om vraagt.
C# bestaat zoals gezegd niet enkel uit grammaticale regels. Grammatica zonder woordenschat is nutteloos. Er zijn binnen C# dan ook momenteel 80 woorden, zogenaamde reserved keywords die de woordenschat voorstellen. Het spreekt voor zich dat deze keywords een eenduidige, specifieke betekenis hebben en dan ook enkel voor dat doel gebruikt kunnen worden.
In dit boek zullen we stelselmatig deze keywords leren kennen en gebruiken op een correcte manier om zo werkende code te maken.
Deze keywords zijn:
abstract
as
base
bool
break
byte
case
catch
char
checked
class
const
continue
decimal
default
delegate
do
double
else
enum
event
explicit
extern
false
finally
fixed
float
for
foreach
goto
if
implicit
in
int
interface
internal
is
lock
long
namespace
new
null
object
operator
out
override
params
private
protected
public
readonly
ref
return
sbyte
sealed
short
sizeof
stackalloc
static
string
struct
switch
this
throw
true
try
typeof
uint
ulong
unchecked
unsafe
ushort
using
using static
virtual
void
volatile
while
De keywords in vet zijn keywords die we in het eerste deel van dit boek zullen bekijken (hoofdstukken 1 tot en met 8). Die in cursief in het tweede deel (9 en verder). De overige zal je zelf moeten ontdekken ... of mogelijk zelfs nooit in je carrière gebruiken vanwege hun soms obscure nut.
C# is een levende taal. Soms verschijnen er dan ook nieuwe keywords. De afspraak is echter dat de lijst hierboven niet verandert. Nieuwe keywords maken deel uit van de contextual keywords en zullen nooit gereserveerde keywords worden. We zullen enkele van deze "nieuwere" keywords tegenkomen waaronder: get, set, value en var.
Aandacht, aandacht! Step away from the keyboard! I repeat. Step away from the keyboard. Hierbij wil ik u attent maken op een belangrijke, onbeschreven, wet voor C# programmeurs: "NEVER EVER USE GOTO"
Het moet hier alvast even uit m'n systeem. goto is weliswaar een officieel C# keyword, toch zal je het in dit boek nooit zien terugkomen in code. Je kan alle problemen in je algoritmes oplossen zonder ooit goto nodig te hebben.
Voel je toch de drang: don't! Simpelweg, don't. Het is het niet waard. Geloof me.
Variabelen zijn nodig om tijdelijke data in op te slaan, zoals gebruikersinput, zodat we deze later in het programma kunnen gebruiken.
We doen hetzelfde in ons hoofd wanneer we bijvoorbeeld zeggen "tel 3 en 4 op en vermenigvuldig dat resultaat met 5". Eerst zullen we het resultaat van "3+4" in een variabele moeten bewaren. Vervolgens zullen we de inhoud van die variabele vermenigvuldigen met 5 en dat nieuwe resultaat ook in een nieuwe variabele opslaan.
Wanneer we een variabele aanmaken, zal deze moeten voldoen aan enkele afspraken. Zo moeten we minstens 2 zaken meegeven:
De identifier waarmee we snel aan de variabele-waarde kunnen. Dit is de gebruiksvriendelijke naam die we geven aan een geheugenplek.
Het datatype dat aangeeft wat voor soort data we wensen op te slaan. Enkel en alleen dat soort type data zal in deze variabele kunnen bewaard worden.
De code die we gaan schrijven moet voldoen aan een hoop regels. Wanneer we in onze code zelf namen (identifiers) geven aan variabelen (en later ook methoden, objecten, enz.) dan moeten we een aantal regels volgen:
Hoofdlettergevoelig: de identifiers tim en Tim zijn verschillend zoals reeds vermeld.
Geen keywords: identifiers mogen geen gereserveerde C# keywords zijn. De keywords van 2 pagina's terug mogen dus niet. Varianten waarbij de hoofdletters anders zijn mogen wel. gOTO en stRINg mogen dus wel, maar niet goto of string want dat zijn gereserveerde keywords. Een ander voorbeeld INT mag bijvoorbeeld wel, maar int niet.
Eerste karakter-regel: het eerste karakter van de identifier mag een kleine of grote letter, of een liggend streepje (_) zijn.
Alle andere karakters-regels: de overige karakters volgende de eerste karakter-regel, maar mogen ook cijfers zijn.
Lengte: Een legale identifier mag zo lang zijn als je wenst, maar je houdt het best leesbaar.
Volg je voorgaande regels niet dan zal je code niet gecompileerd worden en zal VS de identifiers in kwestie als een fout aanduiden. Of beter, als een hele hoop foutboodschappen. Schrik dus niet als je bijvoorbeeld het volgende ziet:
Er zijn geen vaste afspraken over hoe je je variabelen moet noemen toch hanteren we enkele coding richtlijnen:
Duidelijke naam: de identifier moet duidelijk maken waarvoor de identifier dient. Schrijf dus liever gewicht of leeftijd in plaats van a of meuh.
Camel casing: gebruik camel casing indien je meerdere woorden in je identifier wenst te gebruiken. Camel casing wil zeggen dat ieder nieuw woord terug met een hoofdletter begint. Een goed voorbeeld kan dus zijn leeftijdTimDams of aantalLeerlingenKlas1EA. Merk op dat we liefst het eerste woord met kleine letter starten. Uiteraard zijn er geen spaties toegelaten.
Eén lijn commentaar geef je aan door de lijn te starten met twee voorwaartse slashes //. Uiteraard mag je ook meerdere lijnen op deze manier in commentaar zetten. Zo wordt dit ook vaak gebruikt om tijdelijk een stuk code "uit te schakelen". Ook mogen we commentaar achter een stuk C# code plaatsen zoals we hieronder tonen.
// zal alle tekens die volgen tot aan de volgende witregel in commentaar zetten:
//De start van het programma
int getal = 3;
//Nu gaan we rekenen
int result = getal * 5;
// result = 3*5;
Console.WriteLine(result); //We tonen resultaat op scherm: 15
We kunnen een stuk tekst als commentaar aangeven door voor de tekst /* te plaatsen en */ achteraan. Een voorbeeld:
/*
Een blok commentaar
Een heel verhaal, dit wordt mooi
Is dit een haiku?
*/
int leeftijd = 0;
Je kan ook code in VS selecteren en dan met de comment/uncomment-knoppen in de menubalk heel snel lijnen of hele blokken code van commentaar voorzien, of deze net weghalen:
Een essentieel onderdeel van C# is kennis van datatypes. Binnen C# zijn een aantal types gedefinieerd die je kan gebruiken om data in op te slaan. Wanneer je data wenst te bewaren in je applicatie dan zal je je moeten afvragen wat voor soort data het is. Gaat het om een geheel getal, een kommagetal, een stuk tekst of misschien een binaire reeks? Ieder datatype in C# kan één welbepaald soort data bewaren en dit zal telkens een bepaalde hoeveelheid computergeheugen vereisen.
Datatypes zijn een belangrijk concept in C# omdat deze taal een zogenaamde "strongly typed language" is (in tegenstelling tot bijvoorbeeld JavaScript). Wanneer je in C# data wenst te bewaren (in een variabele) zal je van bij de start moeten aangeven wat voor data dit zal zijn. Vanaf dan zal de data op die geheugenplek op dezelfde manier verwerkt worden en niet zo maar van 'vorm' kunnen veranderen zonder extra input van de programmeur.
Bij JavaScript kan dit bijvoorbeeld wel, wat soms een fijn werken is, maar ook vaak vloeken: je bent namelijk niet gegarandeerd dat je variabele wel het juiste type zal bevatten wanneer je het gaat gebruiken.
Er zijn verscheine basistypes in C# gedeclareerd, zogenaamde primitieve datatypes:.
Enums (een speciaal soort datatype dat een beetje een combinatie van meerdere datatypes is én dat je zelf deels kan definiëren.)
Ieder datatype wordt gedefinieerd door minstens volgende eigenschappen:
Soort data dat in de variabele van dit type kan bewaard worden (tekst, geheel getal, enz.)
Geheugengrootte: de hoeveelheid bits dat 1 element van dit datatype inneemt in het geheugen. Dit kan belangrijk zijn wanneer je met véél data gaat werken en je niet wilt dat de gebruiker drie miljoen gigabyte RAM nodig heeft.
Schrijfwijze van de literals: hoe weet C# of 2 een komma getal (2.0) of een geheel getal (2) is? Hiervoor gebruiken we specifieke schrijfwijzen van deze waarden (literals) wat we verderop uiteraard uitgebreid zullen bespreken.
Het datatype string heb je al gezien in het vorig hoofdstuk. Je hebt toen een variabele aangemaakt van het type string door de zin string result;.
Verderop plaatsen we dan iets waar de gebruiker iets kan intypen in die variabele:
Alhoewel een computer digitaal werkt en enkel 0'n en 1'n bewaart zou dat voor ons niet erg handig werken. C# heeft daarom een hoop datatypes gedefinieerd om te werken met getallen zoals wij ze kennen, gehele en kommagetallen. Intern zullen deze getallen nog steeds binair bewaard worden, maar dat is tijdens het programmeren zelden een probleem.
De basistypen van C# om getallen in op te slaan zijn:
Voor gehele getallen: sbyte, byte, short, int , long en char.
Voor natuurlijke getallen (enkel positief): ushort, uint en ulong.
Voor kommagetallen: double, float en decimal.
Deze datatypes hebben allemaal een verschillend bereik, wat een rechtstreekse invloed heeft op de hoeveelheid geheugen die ze innemen.
Ieder type hierboven heeft een bepaald bereik en hoeveelheid geheugen nodig. Je zal dus steeds moeten afwegen wat je wenst. Op een high-end pc met vele gigabytes aan werkgeheugen (RAM) is geheugen zelden een probleem waar je rekening mee moet houden.
Of toch: wat met real-time first person shooters die miljoenen berekeningen per seconde moeten uitvoeren? Daar zal iedere bit en byte tellen. Op andere apparaten (smartphone, arduino, smart fridges, enz.) is iedere byte geheugen nog kostbaarder. Kortom: kies steeds bewust het datatype dat het beste 'past' voor je probleem qua bereik, precisie en geheugengebruik.
Het bereik van ieder datatype is een rechtstreeks gevolg van het aantal bits waarmee het getal in dit type wordt voorgesteld. De short bijvoorbeeld wordt voorgesteld door 16 bits. Eén bit daarvan wordt gebruikt voor het teken (0 of 1, + of -). De overige 15 bits worden gebruikt voor de waarde: van 0 tot 2^15^-1 (= 32767) en van -1 tot -2^15^ (= -32768)
Enkele opmerkingen bij voorgaande tabel:
De s vooraan sbyte staat voor signed: m.a.w. 1 bit wordt gebruikt om het + of - teken te bewaren.
De u vooraan ushort, uint en ulong staat voor unsigned. Het omgekeerde van signed dus. Kwestie van het ingewikkeld te maken. Deze twee datatypes hebben dus geen teken en zijn altijd positief.
char bewaart karakters. We zullen verderop dit datatype uitspitten en ontdekken dat karakters (alle tekens op het toetsenbord, inclusief getallen, leesteken, enz.) als gehele, binaire getallen worden bewaard. Daarom staat char in deze lijst.
Het grootste getal bij long is 2^63^-1 (negen triljoen tweehonderddrieëntwintig biljard driehonderd tweeënzeventig biljoen zesendertig miljard achthonderdvierenvijftig miljoen zevenhonderdvijfenzeventigduizend achthonderd en zeven). Dit zijn maar 63 bits?! Inderaad, de laatste bit wordt wederom gebruikt om het teken te bewaren.
"Wow. Moet je al die datatypes uit het hoofd kennen? Ik was al blij dat ik tekst op het scherm kon tonen."
Uiteraard kan het geen kwaad dat je de belangrijkste datatypes onthoudt, anderzijds zul je zelf merken dat door gewoon veel te programmeren je vanzelf wel zult ontdekken welke datatypes je waar kunt gebruiken. Laat je dus niet afschrikken door de ellenlange tabellen met datatypes in dit hoofdstuk, we gaan er maar een handvol effectief van gebruiken.
Voor de kommagetallen zijn er maar 3 mogelijkheden. Ieder datatype heeft een 'voordeel' tegenover de 2 andere, dit voordeel staat vet in de tabel:
Type
Geheugen
Bereik
Precisie
float
32 bits
gemiddeld
~6-9 digits
double
64 bits
meeste
~15-17 digits
decimal
128 bits
minste
28-29 digits
Zoals je ziet moet je bij kommagetallen een afweging maken tussen 3 even belangrijke criteria. Heb je ongelooflijk grote precisie nodig dan ga je voor een decimal. Wil je vooral erg grote of erg kleine getallen kies je voor double. Zoals je merkt zal je dus zelden decimal nodig hebben, deze zal vooral nuttig zijn in financiële en wetenschappelijke programma's waar met erg exacte cijfers moet gewerkt worden.
Bij twijfel opteren we meestal voor kommagetallen om het double datatype te gebruiken. Bij gehele getallen kiezen we meestal voor int.
De precisie van een getal is het aantal beduidende cijfers. Enkele voorbeelden:
bool (boolean) is het eenvoudigste datatype van C#. Het kan maar 2 mogelijke waarden bevatten: true of false. 0 of 1 met andere woorden.
We zullen het bool datatype erg veel nodig hebben wanneer we met beslissingen zullen werken in een later hoofdstuk, specifiek de if statements die afhankelijk van de waarde van een bool bepaalde code wel of niet zullen doen uitvoeren.
Het gebeurt vaak dat beginnende programmeurs een int variabele gebruiken terwijl ze toch weten dat de variabele maar 2 mogelijke waarden zal hebben. Om dus geen onnodig geheugen te verbruiken is het aan te raden om in die gevallen steeds met een bool variabele te werken.
Het bool datatype is uiteraard het kleinst mogelijke datatype. Hoeveel geheugen zal een variabele van dit type innemen denk je? Inderdaad 1 bit.
Ik besteed verderop een heel apart hoofdstuk om te tonen hoe je één enkel karakter of volledige flarden tekst kan bewaren in variabelen.
Hier alvast een voorsmaakje:
Tekst kan bewaard worden in het string datatype.
Een enkel karakter wordt bewaard in het char datatype dat we ook hierboven al even hebben zien passeren.
Wat een gortdroge tekst was me dat nu net? Waarom moeten we al deze datatypes kennen? Wel, we hebben deze nodig om variabelen aan te maken. En variabelen zijn het hart van ieder programma. Zonder variabelen ben je aan het programmeren aan een programma dat een soort vergevorderde vorm van dementie heeft en hoegenaamd niets kan onthouden.
De data die we in een programma gebruiken bewaren we in een variabele van een bepaald datatype. Een variabele is een plekje in het geheugen dat in je programma zal gereserveerd worden om daarin data te bewaren van het type dat je aan de variabele hebt toegekend.
Een variabele heeft een geheugenadres, namelijk de plek waar de data in het geheugen staat. Maar het zou lastig programmeren zijn indien je steeds dit adres moest gebruiken. Daarom moeten we ook steeds een naam oftewel identifier aan de variabele geven. Op die manier kunnen we eenvoudig de geheugenplek aanduiden en hoeven we niet te werken met een lang hexadecimaal geheugen adres (bv. 0x4234FE13EF1).
De identifier van de variabele moet uiteraard voldoen aan de identifier regels zoals eerder besproken.
Om een variabele te maken moeten we deze declareren, door een type en naam te geven. Vanaf dan zal de computer een hoeveelheid geheugen voor je reserveren waar de inhoud van deze variabele in kan bewaard worden.
Hiervoor dien je minstens op te geven:
Het datatype (bv. int, double).
Een identifier zodat de variabele uniek kan geïdentificeerd worden volgens de naamgevingsregel van C#.
(optioneel) Een beginwaarde die de variabele krijgt bij het aanmaken ervan.
Een variabele declaratie heeft als syntax:
datatype identifier;
Enkele voorbeelden:
int leeftijd;
string leverAdres;
bool isGehuwd;
Indien je weet wat de beginwaarde moet zijn van de variabele dan mag je de variabele ook reeds deze waarde toekennen bij het aanmaken:
int mijnLeeftijd = 37;
Je mag ook meerdere variabelen van het zelfde datatype in 1 enkele declaratie aanmaken door deze met komma's te scheiden:
Van zodra je een variabele hebt gedeclareerd kunnen we dus ten allen tijde deze variabele gebruiken om een waarde aan toe te kennen, de bestaande waarde te overschrijven, of de waarde te gebruiken, zoals:
Waarde toekennen: Herinner dat de toekenning steeds gebeurt van rechts naar links: het deel rechts van het gelijkheidsteken wordt toegewezen aan het deel links er van, bijvoorbeeld: mijnGetal = 15;
Waarde gebruiken: Bijvoorbeeld anderGetal = mijnGetal + 15;
Waarde tonen op scherm: Bijvoorbeeld Console.WriteLine(mijnGetal);
Met de toekennings-operator (=) kan je een waarde toekennen aan een variabele. Hierbij kan je zowel een literal toekennen oftewel het resultaat van een expressie .
Je kan natuurlijk ook een waarde uit een variabele uitlezen en toewijzen (kopiëren) aan een andere variabele:
Literals zijn expliciet neergeschreven waarden in je code. De manier waarop je een literal schrijft in je code zal bepalen wat het datatype van die literal is:
Gehele getallen worden standaard als int beschouwd, vb: 125.
Kommagetallen (met punt .) worden standaard als double beschouwd, vb: 12.5.
Wil je echter andere getaltypes dan int of double een waarde geven dan moet je dat dus expliciet in de literal aanduiden. Hiervoor plaats je een suffix achter de literalwaarde. Afhankelijk van deze suffix duidt je dan aan om welke datatype het gaat:
U of u voor uint, vb: 125U (dus bijvoorbeeld uint aantalSchapen = 27u;)
L of l voor long, vb: 125L.
UL of ul voor ulong, vb: 125ul.
F of f voor float, vb: 12.5f.
M of m voor decimal, vb: 12.5M.
Naast getallen zijn er uiteraard ook nog andere datatypes waar we de literals van moeten kunnen schrijven:
Voor bool zijn dit enkel true en false.
Voor char wordt dit aangeduid met een enkele apostrof voor en na de literal.
Denk maar aan char laatsteLetter = 'z';.
Voor string wordt dit aangeduid met aanhalingsteken voor en na de literal.
Bijvoorbeeld string myPoke = "pikachu".
Om samen te vatten, even de belangrijkste literal schrijfwijzen op een rijtje:
De overige types sbyte, short en ushort hebben geen literal aanduiding. Er wordt vanuit gegaan wanneer je een literal probeert toe te wijzen aan één van deze datatypes dat dit zonder problemen zal gaan (ze worden impliciet geconverteerd).
Volgende code mag dus:
sbyte start = 127;
Dit wordt toegestaan, de int literal 127 zal geconverteerd worden achter de schermen naar een sbyte en dan toegewezen worden.
Als je in je code expliciet de waarde 4 wilt toekennen aan een variabele dan is het getal 4 in je code een zogenaamde literal.
Voorbeelden van een literal toekennen:
int temperatuurGisteren = 20; //20 is de literal
int temperatuurVandaag = 25; //25 is de literal
Het is belangrijk dat het type van de literal overeenstemt met dat van de variabele waaraan je deze zal toewijzen. Volgende code zal dan ook een compiler-fout genereren. Je probeert een string-literal aan een int-variabele wil toewijzen, en omgekeerd:
string eenTekst;
int eenGetal;
eenTekst = 4;
eenGetal = "4";
Als je bovenstaande probeert te compileren dan krijg je volgende foutboodschappen:
Het is een goede gewoonte om variabelen steeds ogenblikkelijk een beginwaarde toe te wijzen. Alhoewel C# altijd vers gedeclareerde variabelen een standaard beginwaarde zal geven, is dit niet zo in oudere programmeertalen. In sommige talen zal een variabele een volledig willekeurige beginwaarde krijgen. Gelukkig in C# is dat niet, maar geef toch maar direct steeds een waarde, al was het maar om je literals te oefenen.
De standaard beginwaarde van een variabele hangt natuurlijk van het datatype af:
Voor getallen is dat steeds de nulwaarde (dus 0 bij int, 0.0 bij double, enz.).
Bij variabelen van het type bool is dat false.
Bij char is dat de literal: \0 (in het volgende hoofdstuk leggen we die vreemde backslash uit).
En bij tekst is dat de lege string-literal: "" (maar je mag ook String.Empty gebruiken).
Wanneer je een reeds gedeclareerde variabele een nieuwe waarde toekent dan zal de oude waarde in die variabele onherroepelijk verloren zijn. Probeer dus altijd goed op te letten of je de oude waarde nog nodig hebt of niet. Wil je de oude waarde ook nog bewaren dan zal je een nieuwe, extra variabele moeten aanmaken en daarin de nieuwe waarde moeten bewaren:
int temperatuurGisteren = 20;
temperatuurGisteren = 25;
In dit voorbeeld zal er voor gezorgd worden dat de oude waarde van temperatuurGisteren (20) overschreven zal worden met 25.
Volgende code toont hoe je bijvoorbeeld eerst de vorige waarde kunt bewaren en dan overschrijven:
int temperatuurGisteren = 20;
//Doe van alles
//...
//Vervolgens: vorige temperatuur in eergisteren bewaren
int temperatuurEerGisteren = temperatuurGisteren;
//temperatuur nu overschrijven
temperatuurGisteren = 25;
We hebben aan het einde van het programma zowel de temperatuur van eergisteren (20), als die van gisteren (25).
Een veel gemaakte fout is variabelen meer dan één keer declareren. Dit mag niet! Van zodra je een variabele declareert is deze bruikbaar in de scope (zie hoofdstuk 5) tot het einde. Binnen de scope van die variabele kan je geen nieuwe variabele aanmaken met dezelfde naam (zelfs niet wanneer het type anders is).
Zonder expressies is programmeren saai: je kan dan enkel variabelen aan elkaar toewijzen. Expressies zijn als het ware eenvoudige tot complexe sequenties van bewerkingen die op 1 resultaat uitkomen met een specifiek datatype. De volgende code is bijvoorbeeld een expressie: 3+2.
Meestal zal je expressies schrijven waarin je bewerkingen op en met variabelen uitvoert. Vervolgens zal je het resultaat van die expressie willen bewaren voor verder gebruik in je code. In de volgende code kennen we het expressie-resultaat toe aan een variabele:
int temperatuursVerschil = temperatuurGisteren - temperatuurVandaag;
Hierbij zal de temperatuur uit de rechtse 2 variabelen worden uitgelezen, van elkaar worden afgetrokken en vervolgens bewaard worden in temperatuursVerschil.
Een ander voorbeeld van een expressie-resultaat toewijzen maar nu met literals:
int temperatuursVerschil = 21 - 25;
Uiteraard mag je ook combinaties van literals en variabelen gebruiken in je expressies:
Om expressies te gebruiken hebben we ook zogenaamde operators nodig. Operators in C# zijn de wiskundige bewerkingen zoals optellen, aftrekken, vermenigvuldigen en delen. Deze volgen de klassieke wiskundige regels van volgorde van berekeningen:
Haakjes
Vermenigvuldigen, delen en modulo: *, / , % (rest na deling, ook modulo genoemd).
Optellen en aftrekken: + en -
We spreken over operators en operanden. Een operand is het element dat we links en/of rechts van een operator zetten. In de som 3+2 zijn 3 en 2 de operanden, en + de operator. In dit voorbeeld spreken we van een binaire operator omdat er twee operanden zijn.
Er bestaan ook unaire operators die maar 1 operand hebben. Denk bijvoorbeeld aan de - operator om het teken van een getal om te wisselen: -6.
In hoofdstuk 5 zullen we nog een derde type operator ontdekken: de ternaire operator die met 3 operanden werkt!
Net zoals in de wiskunde kan je in C# met behulp van de haakjes verplichten het deel tussen de haakjes eerst te berekenen, ongeacht de andere operators en hun volgorde van berekeningen:
3+5*2 // zal 13 (type int) als resultaat geven
(3+5)*2 // zal 16 (type int) geven
Je kan nu complexe berekeningen doen door literals, operators en variabelen samen te voegen. Bijvoorbeeld om te weten hoeveel je op Mars zou wegen:
De modulo operator die we in C# aanduiden met % verdient wat meer uitleg. Deze operator zal als resultaat de gehele rest teruggeven wanneer we het linkse getal door het rechtse getal delen:
int rest = 7%2;
int resultaat2 = 10%5;
Lijn 1 resulteert in de waarde 1 die in rest wordt bewaard: 7 delen door 2 geeft 3 met rest 1. Lijn 2 zal 0 geven, want 10 delen door 5 heeft geen rest.
De modulo-operator zal je geregeld gebruiken om bijvoorbeeld te weten of een getal een veelvoud van iets is. Als de rest dan 0 is weet je dat het getal een veelvoud is van het getal waar je het door deelde.
Bijvoorbeeld om te testen of getal even is gebruiken we %2:
int getal = 1234234;
int rest = getal%2;
Console.WriteLine("Indien het getal als rest 0 geeft is deze even.");
Console.WriteLine("De rest is: " + rest);
Heel vaak wil je de inhoud van een variabele bewerken en dan terug bewaren in de variabele zelf. Bijvoorbeeld een variabele vermenigvuldigen met 10 en het resultaat ervan terug in de variabele plaatsen. Hiervoor zijn enkele verkorte notaties in C#.
Stel dat we een variabele int getal hebben:
Verkorte notatie
Lange notatie
Beschrijving
getal++;
getal = getal+1;
variabele met 1 verhogen
getal--;
getal = getal-1;
variabele met 1 verlagen
getal+=3;
getal = getal+3;
variabele verhogen met een getal
getal-=6;
getal = getal-6;
variabele verminderen met een getal
getal*=7;
getal = getal*7;
variabele vermenigvuldigen met een getal
getal/=2;
getal = getal/2;
variabele delen door een getal
Je zal deze verkorte notatie vaak tegenkomen. Ze zijn identiek aan elkaar en zullen dus je code niet versnellen. Ze zal enkel compacter zijn om te lezen. Bij twijfel, gebruik gewoon de lange notatie.
De verkorte notaties hebben ook een variant waarbij de operator links en de operand rechts staat. Bijvoorbeeld --getal. Beide doen het zelfde, maar niet helemaal. Je merkt het verschil in volgende voorbeeld:
int getal = 1;
int som = getal++; //som wordt 1, getal wordt 2
int som2 = ++som; //som2 wordt 2, som wordt 2
Als je de operator achter de operand zet (som++) dan zal eerst de waarde van de operand worden teruggegeven, vervolgens wordt deze verhoogd. Bij de andere (++som) is dat omgekeerd: eerst wordt de operand aangepast, vervolgens wordt nieuwe waarde als resultaat van de expressie teruggegeven.
Gegroet! Zet je helm op en let alsjeblieft goed op. Als je de volgende sectie goed begrijpt dan heb je al een grote stap vooruit gezet in de wondere wereld van C#.
Ik zei je al dat variabelen het hart van programmeren zijn. Wel, expressies zijn het bloedvatensysteem dat ervoor zorgt dat al je variabelen ook effectief gecombineerd kunnen worden tot wondermooie nieuwe dingen.
Succes!
De voorman verschijnt wanneer er iets beschreven wordt waar véél fouten op gemaakt worden, zelfs bij ervaren programmeurs. Opletten geblazen dus.
Lees deze zin enkele keren luidop voor, voor je verder gaat: De types die je in je expressies gebruikt bepalen ook het type van het resultaat. Als je bijvoorbeeld twee int variabelen of literals optelt zal het resultaat terug een int geven (klink logisch, maar lees aandachtig verder):
int result = 3 + 4;
Je kan echter geen kommagetallen aan int toewijzen. Als je dus twee double variabelen deelt is het resultaat terug een double en zal deze lijn een fout geven daar je probeert een double aan een int toe te wijzen:
int otherResult = 3.1 / 45.2; //dit is fout!!!
Bovenstaande code geeft volgende fout: "Cannot implicitly convert double to int."
Wat als je datatypes mengt? Als je een berekening doet met bijvoorbeeld een int en een double dan zal C# het 'grootste' datatype kiezen. In dit geval een double.
Volgende code zal dus werken:
double result = 3/5.6;
Volgende code niet:
int result = 3/5.6;
En zal weer dezelfde fout genereren: "Cannot implicitly convert type 'double' to 'int'. An explicit conversion exists (are you missing a cast?)"
Wil je dus het probleem oplossen om 9 te delen door 2 en toch 4.5 te krijgen (en niet 4) dan zal je minstens 1 van de 2 literals of variabelen naar een double moeten omzetten.
Het voorbeeld van hierboven herschrijven we daarom naar:
int getal1 = 9;
double getal2 = 2.0; //slim he
double result = getal1/getal2;
Console.WriteLine(result);
En nu krijgen we wel 4.5 aangezien we nu een int door een double delen en C# dus ook het resultaat dan als een double zal teruggeven.
Begrijp je nu waarom dit een belangrijk deel was? Je kan snel erg foute berekeningen en ongewenste afrondingen krijgen indien je niet bewust omgaat met je datatypes.
Laten we eens kijken of je goed hebt opgelet, het kan namelijk subtiel en ambetant worden in grotere berekeningen.
Stel dat ik afspreek dat je van mij de helft van m'n salaris krijgt1. Ik verdien 10 000 euro per maand (I wish).
Ik stel je voor om volgende expressie te gebruiken om te berekenen wat je van mij krijgt:
double helft = 10000.0 * (1 / 2);
Hoeveel krijg je van me?
0.0 euro, MUHAHAHAHA!!!
Begrijp je waarom? De volgorde van berekeningen zal eerst het gedeelte tussen de haakjes doen:
1 delen door 2 geeft 0, daar we een int door een int delen en dus terug een int als resultaat krijgen.
Vervolgens zullen we deze 0 vermenigvuldigen met 10000.0 waarvan ik zo slim was om deze in double te zetten. Niet dus. We vermenigvuldigen weliswaar een double (10000.0) met een int, maar die int is reeds 0 en we krijgen dus 0.0 als resultaat.
Als ik dus effectief de helft van m'n salaris wil afstaan dan moet ik de expressie aanpassen naar bijvoorbeeld:
double helft = 10000.0 * (1.0 / 2);
Nu krijgt het gedeelte tussen de haakjes een double als resultaat, namelijk 0.5 dat we dan kunnen vermenigvuldigen met het salaris om 5000.0 te krijgen, wat jij vermoedelijk een fijner resultaat vindt.
1
Voorgaande voorbeeld is gebaseerd op een oefening uit het handboek "Programmeren in C#" van Douglas Bell en Mike Parr, een boek dat werd vertaald door collega lector Kris Hermans bij de Hogeschool PXL. Als je de console-applicaties beu bent en liever leert programmeren door direct grafische Windows-applicatie te maken, dan raad ik je dit boek ten stelligste aan!
Je zal het const keyword hier en daar in codevoorbeelden zien staan. Je gebruikt dit om aan te geven dat een variabele onveranderlijk is én niet per ongeluk kan aangepast worden. Door dit keyword voor de variabele declaratie te plaatsen zeggen we dat deze variabele na initialisatie niet meer aangepast kan worden.
Volgende voorbeeld toont in de eerste lijn hoe je het const gebruikt. De volgende lijn zal dankzij dit keyword een error geven reeds bij het compileren en jou dus waarschuwen dat er iets niet klopt.
Merk op hoe we de const variabelen een identifier geven: deze zetten we in ALLCAPS. Hierbij gebruiken we een liggend streepjes om het onderscheid tussen de onderlinge woorden aan te geven. Dit is geen verplichting, maar gewoon een aanbeveling.
Constanten in code worden ook soms magic numbers genoemd. De reden hiervoor is dat ze vaak plotsklaps ergens in de code voorkomen, maar wel op een heel andere plek werden gedeclareerd. Hierdoor is het voor de ontwikkelaar niet altijd duidelijk wat de variabele juist doet.
Het is daarom belangrijk dat je goed nadenkt over het gebruik van magic numbers én deze zeer duidelijke namen geeft.
Er worden vele filosofische oorlogen gevoerd tussen ontwikkelaars over de plek van magic numbers in code. In de C/C++ tijden werden deze steeds bovenaan aan de start van de code gegroepeerd. Op die manier zag de ontwikkelaar in één oogopslag alle belangrijke variabelen en konden deze ook snel aangepast worden. In C# prefereert men echter om variabelen zo dicht mogelijk bij de plek waar ze nodig zijn te schrijven, dit verhoogt de modulariteit van de code: je kan sneller een flard code kopiëren en op een andere plek herbruiken.
De applicaties die wij in dit boek ontwikkelen zijn niet groot genoeg om over te debatteren. Veel bedrijven hanteren hun eigen coding guidelines en het gebruik, naamgeving en plaatsing van magic numbers zal zeker daarin zijn opgenomen.
Het wordt tijd om eens te kijken hoe Visual Studio jouw code juist organiseert wanneer je een nieuw project start. Zoals je al hebt gemerkt in de solution Explorer wordt er meer aangemaakt dan enkel een Program.cs codebestand. Visual Studio werkt volgens volgende hiërarchie:
Een solution is een folder waarbinnen één of meerdere projecten bestaan.
Een project is een verzameling (code)bestanden die samen een specifieke functionaliteit vormen en kunnen worden gecompileerd tot een uitvoerbaar bestand, bibliotheek, of andere vorm van output (we vereenvoudigen bewust het concept project in dit handboek).
Wanneer je dus aan de start van een nieuwe opdracht staat en in VS kiest voor "Create a new project" dan zal je eigenlijk aan een nieuwe solution beginnen met daarin één project.
Je bent echter niet beperkt om binnen een solution maar één project te bewaren. Integendeel, vaak kan het handig zijn om meerdere projecten samen te houden. Ieder project bestaat op zichzelf, maar wordt wel logisch bij elkaar gehouden in de solution. Dat is ook de reden waarom we vanaf de start hebben aangeraden om nooit het vinkje "Place solution and project in the same directory" aan te duiden.
Wanneer je in VS een nieuw project start ben je niet verplicht om de "Project name" en "Solution name" dezelfde waarde te geven. Je zal wel merken dat bij het invoeren van de "Project name" de "Solution name" dezelfde invoer krijgt. Je mag echter vervolgens perfect de "Solution name" aanpassen.
Stel dat we een nieuw VS project aanmaken met volgende informatie:
Naam van het project = Opdracht1
Naam van de solution = Huiswerk
En plaatsen deze in de folder C:\Temp.
Wanneer we het project hebben aangemaakt en de Solution Explorer bekijken zien we volgende beeld :
Rechterklik nu op de solution en kies "Open folder in file explorer". Je kan deze optie kiezen bij eender welk item in de solution explorer. Het zal er voor zorgen dat de verkenner wordt geopend op de plek waar het item staat waar je op rechterklikte. Op die manier kan je altijd ontdekken waar een bestand of of folder zich fysiek bevindt op je harde schijf.
We zien nu een tweede belangrijke aspect dat we in deze sectie willen uitleggen: Een solution wordt in een folder geplaatst met dezelfde naam én bevat één .sln bestand. Binnenin deze folder wordt een folder aangemaakt met de naam van het project. Je folderstructuur volgt dus flink de structuur van je solution in VS.
Je kan dus je volledige solution, inclusief het project, openen door in deze folder het .sln bestand te selecteren. Dit .sln bestand zelf bevat echter geen code.
Die laatste zin heeft als gevolg dat je de hele folderstructuur moet verplaatsen indien je aan je solution op een andere plek wilt werken. Open gerust eens een .sln-bestand in notepad en je zal zien dat het bestand onder andere oplijst waar het onderliggende project zich bevindt. Wil je dus je solution doorgeven of mailen naar iemand, zorg er dan voor je de hele foldestructuur doorgeeft, inclusief het .sln bestand en alles folders die er bij horen.
Laten we nu eens kijken hoe de folderstructuur van het project zelf is. Rechterklik deze keer op het project in de solution explorer (Opdracht1) en kies weer "Open folder in file explorer".
Hier staat een herkenbaar bestand! Inderdaad, het Program.cs codebestand. In dit bestand staat de actuele code van Opdracht1.
Voorts zien we ook een .csproj bestand genaamd Opdracht1. Net zoals het .sln bestand zal dit bestand beschrijven welke bestanden én folder(s) deel uitmaken van het huidige project. Je kan dit bestand dus ook openen vanuit de verkenner en je zal dan je volledige project zien worden ingeladen in Visual Studio.
Een .cs-bestand rechtstreeks vanuit de verkenner openen werkt niet zoals je zou verwachten. VS zal weliswaar de inhoud van het bestand tonen, maar je kan verder niets doen. Je kan niet compileren, debuggen, enz. De reden is eenvoudig: een .cs bestand op zichzelf is nutteloos. Het heeft pas een bestaansreden wanneer het wordt geopend in een project. Het project zal namelijk beschrijven hoe dit specifieke bestand juist moet gebruikt worden in het huidige project.
De "obj" folder ga ik in dit handboek negeren. Maar kijk eens wat er in de "bin" folder staat?! Een folder genaamd "debug". In deze folder zal je de gecompileerde (debug-)versie van je huidige project terecht komen. Je zal wat moeten doorklikken tot de binnenste folder (die de naam van de huidige .net versie bevat waarin je compileert).
Je kan in principe vanuit deze folder ook je gecompileerde project uitvoeren door te dubbelklikken op Opdracht1.exe. Je zal echter merken dat het programma ogenblikkelijk terug afsluit omdat het programma aan het einde van de code altijd afsluit. Voeg daarom volgende lijn code toe onderaan in je Main: Console.ReadLine(). Het programma zal nu pas afsluiten wanneer je op Enter hebt gedrukt en de gecompileerde versie kan dus nu vanuit de verkenner gestart worden, hoera!
Merk op dat je de volledige inhoud van deze folder moet meegeven indien je je gecompileerde resultaat aan iemand wilt geven om uit te voeren.
Ik zei net dat een solution meerdere projecten kan bevatten. Maar hoe voeg je een extra project toe? Terwijl je huidige solution open is (waar je een project wenst aan toe te voegen) kies je in het menu voor File->Add->New project...
Je moet nu weer het klassieke proces doorlopen om een console-project aan te maken. Alleen ontbreekt deze keer het "Solution name" tekstveld, daar dit reeds gekend is.
Wanneer je klaar bent zal je zien dat in de solution Explorer een tweede project is verschenen. Als we de folderstructuur van onze solution opnieuw bekijken, zien we dat er een nieuwe folder (Opdracht2) is verschenen met een eigen Program.cs en .csproj-bestand.
Nu rest ons nog één belangrijke stap: selecteren welk project moet gecompileerd en uitgevoerd worden. In de solution explorer kan je zien welk het actieve project is, namelijk het project dat vet gedrukt staat.
Je kan nu op 2 manieren kiezen welk project moet uitgevoerd worden:
Manier 1: Rechterklik in de Solution Explorer op het actief te zetten project en kies voor "Set as startup project."
Manier 2: Bovenaan, links van de groene "compiler/run" knop, staat een selectieveld met het actieve project. Je kan hier een andere project selecteren.
Controleer altijd goed dat je in het juiste Program.cs bestand bent aan het werken. Je zou niet de eerste zijn die maar niet begrijpt waarom de code die je invoert z'n weg niet vindt naar je debugvenster. Inderdaad, vermoedelijk heb je het verkeerde Program.cs bestand open of heb je het verkeerde actieve project gekozen.
Ook nu reeds heb je mogelijk interesse in meerdere projecten in 1 solution. Je kan nu perfect je opdrachten groeperen onder 1 solution, maar toch iedere opdracht mooi gescheiden houden. In de echte wereld gebruikt men meerdere projecten in 1 solution om het overzicht te bewaren en alles zo modulair mogelijk aan te pakken. Denk maar aan een solution met een projecten dat de (unit)testen bevat, een project voor de frontend, en nog een project voor de backend.
Om een gecompileerde .NET applicatie te kunnen uitvoeren op een computer heb je nog een .NET runtime nodig. Gebruikers die geen Visual Studio hebben geïnstalleerd hebben deze runtime meestal niet op hun systeem.
Wil je dus dat je oma kan genieten van jouw laatste creatie, zorg er dan voor dat ze de juiste .NET runtime heeft draaien. Je zal haar hier wat mee moeten helpen want je moet de runtime installeren1 voor die versie waar tegen jouw applicatie is gecompileerd.
Ieder teken dat je op je toetsenbord kunt intypen is een char. Je toetsenbord bevat echter maar een kleine selectie van alle mogelijke tekens. Vergelijk jouw toetsenbord maar eens met dat van iemand uit bijvoorbeeld Spanje, Tunesië of China.
Voordat we leren hoe je in C# input van het toetsenbord uitleest, moeten we begrijpen hoe al die tekens in een computer worden voorgesteld. Dit gebeurt via de UNICODE standaard. Lang geleden was er de ASCII-standaard, die bepaalde welk teken bij welke hexadecimale waarde hoorde. Iedereen die ASCII volgde, kon zo berichten met die tekens naar elkaar sturen.
UNICODE volgt de ASCII-standaard op. Door de verdere digitalisering van de wereld bleek de ASCII-standaard al snel te klein. ASCII kan maar 128 karakters voorstellen, via 7 bits. Dit is weinig vergeleken met de meer dan 1 miljoen tekens in UNICODE, die een 16-bit (UTF-16) voorstelling gebruikt. Er is ook een 32-bit voorstelling mogelijk (UTF-32).
UNICODE bevat ook de eerste 128 tekens van ASCII. Daardoor zijn beide standaarden compatibel. Dankzij UNICODE kunnen we nu wereldwijd elke smiley, letter, en pictogram op dezelfde manier delen. Voor statistiekliefhebbers: er zijn 1.111.998 UNICODE tekens mogelijk. In versie 15.1, uitgebracht in september 2023, zijn daarvan 149.813 tekens gedefinieerd. Er is dus nog ruimte over.
De eerste 32 karakters zijn "onzichtbare" karakters die een historische reden (in ASCII) hebben om in de lijst te staan, maar sommige ervan zijn ondertussen niet meer erg nuttig. Origineel werd ASCII ontwikkeld als standaard om in de vorige eeuw via de Telex te communiceren. Vandaar dat vele van deze karakters commando's lijken om oude typemachines aan te sturen (line feed, bell, form feed, enz.), wat ze dus ook effectief zijn!
In het vorige hoofdstuk werkten we vooral met getallen en haalden we maar kort het string en char datatype aan. In dit hoofdstuk ga ik dieper in op deze 2 veelgebruikte datatypes.
Een enkel karakter (cijfer, letter, leesteken, enz.) als 'tekst' opslaan kan je doen door het char-type te gebruiken. Je kan één enkel karakter als volgt tonen:
Het is belangrijk dat je de apostrof (') niet vergeet voor en na het karakter dat je wenst op te slaan daar dit de literal voorstelling van char-literals is. Zonder die apostrof denkt de compiler dat je een variabele wenst aan te roepen van die naam.
Je kan eender welk UNICODE-teken in een char bewaren, namelijk een letter, een cijfer of een speciaal teken zoals %, $, *, #, enz. Intern wordt de UNICODE van het character bewaard in de variabele, zijnde een 16 bit getal. Deze laatste zin is belangrijk: voor een computer zijn char-variabelen niet meer dan getallen met een speciale betekenis.
Merk dus op dat volgende lijn: char eenGetal = '7'; weliswaar een getal als teken opslaat, maar dat intern de compiler deze variabele steeds als een char zal gebruiken. Als je dit cijfer zou willen gebruiken als effectief cijfer om wiskundige bewerkingen op uit te voeren, dan zal je dit eerst moeten converteren naar een getal (we zullen dit in hoofdstuk 4 uitleggen).
Een string is een reeks van 0, 1 of meerdere char-elementen.
We gebruiken het string datatype om tekst voor te stellen. Je begrijpt waarschijnlijk zelf wel waarom het string datatype een belangrijk en veelgebruikt type is in eender welke programmeertaal: er zijn maar weinig applicaties die niet minstens enkele lijnen tekst tonen aan de gebruiker.
In hoofdstuk 8 zullen we ontdekken dat strings eigenlijk zogenaamde arrays zijn.
Merk op dat we bij een string literal gebruik maken van aanhalingstekens (") terwijl bij een char literal we een apostrof gebruiken ('). Dit is de manier om een string met lengte 1 van een char te onderscheiden.
Volgende code geeft drie keer het cijfer 1 onder elkaar op het scherm. Maar de eerste keer gaat het om het een char (enkelvoudig teken), dan om een string (1 of meerdere tekens) en dan een int (effectief getal, bestaande uit 1 of meer cijfers):
De voorman hier! Escape characters zijn niet de boeiendste materie om te bespreken. Je zou nog kunnen hopen dat het een opvolger is van Prison Break of zo. Helaas is dat niet zo. Echter: als je escape characters beheerst zal je veel eenvoudiger én mooier tekst op je scherm kunnen toveren. Let dus even goed op a.u.b.
Naast letters en tekens mogen in string en chars ook escape characters staan. In C# hebben bepaalde tekens namelijk een speciale functie. Denk maar aan de dubbele aanhalingstekens (") om het begin en einde van een string-literal mee aan te geven.
We hebben dus een manier nodig om aan te duiden wanneer de compiler het eerstvolgende teken, zoals een " als een char moet beschouwen. We lossen dit op met behulp van escape characters. Deze worden met een backslash (\) aangeduid, gevolgd door het karakter dat we wensen te gebruiken.
Laten we eens kijken naar de werking van het weglatingsteken als voorbeeld (de zogenaamde apostrof of afkappingsteken, om bijvoorbeeld 's avonds te schrijven)
De volgende code zal de compiler verkeerd interpreteren, omdat hij denkt dat we een leeg karakter willen opslaan:
char weglatingsteken = ''';
Het gevolg is een berg aan foutboodschappen omdat er na het sluitende weglatingsteken (het tweede) plots nog één (het derde) verschijnt. VS is volledig in de war en weet niet wat doen.
Escape characters to the rescue! We gaan met de backslash aanduiden dat het volgende teken (het tweede weglatingsteken) een char voorstelt en niet het sluitende teken in de code.
char weglatingsteken = '\'';
Een backslash in een char of string-literal geeft aan dat het volgende teken als een literal moet worden gezien en niet als een speciaal teken in C#.
Er zijn verschillende escape characters in C# toegelaten. We lijsten hier de belangrijkste1 op:
\' //de apostrof zoals zonet besproken.
\" //een aanhalingsteken.
\\ //een backslash in je tekst tonen.
\\\\ //twee backslashes.
\n //een nieuwe lijn (zogenaamde *enter* of *newline*).
\t //Horizontale tab.
\uxxxx //een teken met als hexadecimale UNICODE waarde xxxx.
Aangezien strings eigenlijk bestaan uit 1 of meerdere char-elementen, is het logisch dat je ook in een string met escape characters kunt werken. Het woord "'s avonds" schrijf je bijvoorbeeld als volgt:
string woord = "\'s avonds";
Idem met aanhalingstekens. Stel je voor dat je een programma wilt schrijven dat C# code op het scherm toont. Dat doe je dan met volgende, nogal Inception-achtige, manier:
Als je het niet gewoon bent de tab-toets op je toetsenbord te gebruiken dan is de eerste werking van \t mogelijk verwarrend. Nochtans is \t in een string gebruiken exact hetzelfde als op de tab-toets duwen.
In je console-scherm zijn de tab stops vooraf bepaald. Wanneer je dus een tab invoegt zal de cursor zich verplaatsen naar de eerstvolgende tab stop. In volgende tekstuitvoer zie je de tabstops op de tweede lijn "gevisualiseerd":
Tabstops zijn nuttig om je data mooi uitgelijnd in een tabel te plaatsen. Als je dat dan nog eens combineert met de UNICODE karakters om tabellen te tekenen kan je toffe dingen maken. Deze karakters, de zogenaamde "Box Drawing" subset, staan in UNICODE gedefinieerd als de tekens met hexadecimale code 0x2500 en verder. Bekijk zeker eens een datasheet met alle tekens.2.
Het apenstaartje (@) voor een string literal plaatsen is zeggen "beschouw alles binnen de aanhalingstekens als effectieve karakters die deel uitmaken van de inhoud van de tekst". Dit teken heet daarom binnen C# niet voor niets het verbatim karakter. Het is belangrijk te beseffen dat escape characters genegeerd worden wanneer we het verbatim karakter gebruiken. Dit is vooral handig als je bijvoorbeeld een netwerkadres wilt schrijven en niet iedere \ wilt escapen:
Merk op dat aanhalingstekens nog steeds ge-escape'd moeten worden. Heb je dus een stuk tekst met een aanhalingsteken in dan zal je zonder het apenstaartje moeten werken.
Uiteraard kan je ook het apenstaartje gebruiken in Console.WriteLine. Volgende zal dus de escape karakters tonen in plaats van "uitvoeren":
Console.WriteLine(@"Om een tab te tonen gebruik je \t in C#.");
Tot nogtoe gebruikten we de +-operator om strings aan elkaar te plakken. We gaan deze manier meer in detail bekijken, gevolgd door een moderner alternatief: door middel van string interpolatie met de $-notatie.
In de volgende sectie gaan we van volgende informatie uit:
Stel dat je 2 variabelen hebt int leeftijd = 13 en string naam = "Finkelstein".
We willen de inhoud van deze variabelen samenvoegen in een nieuwe string zin die zal bestaan uit de tekst: Ik ben Finkelstein en ik ben 13 jaar.
Je kan strings en variabelen eenvoudig bij elkaar 'optellen' zoals we in het begin van dit boek hebben gezien. Ze worden dan achter elkaar geplakt (geconcateneerd).
string zin = "Ik ben " + naam + " en ik ben " + leeftijd+ " jaar.";
Let er op dat je tussen de aanhalingsteken (binnen de strings) spaties zet indien je het volgende deel niet tegen het vorige deel wilt plakken. Is hiermee alles gezegd?! Neen, toch even goed opletten hier. De volgorde van strings met andere types samenvoegen bepaalt wat de uitvoer zal zijn.
Ook in dit soort code wordt de volgorde van bewerkingen gerespecteerd. De concatenatie gebeurt van links naar rechts en de linkse operand zal steeds bepalen wat het resultaat van de bewerking zal zijn indien er twijfel is. Dit nieuw samengevoegde deel wordt dan de linkse operand voor het volgende deel.
Kijken we dus naar "1"+1+1 dan wordt dit eerst "11"+1 en vervolgens dit "111".
Bij 1+1+"1" krijgen we eerst 2+"1". Dit geeft vervolgens 21. Aangezien C# niet kan bepalen dat de string iets bevat wat een getal kan zijn, en dus besluit om beide operanden als een string te zien wat altijd de veiligste oplossing is.
Het nadeel van de +-operator is dat je strings soms erg lang en onleesbaar worden.
Dankzij string interpolation kan dit wel waarbij we het $-teken gebruiken vooraan de string om aan te geven dat specifieke delen van de zin geïnterpoleerd moeten worden
Door het $-teken VOOR de string te plaatsen geef je aan dat alle delen in de string die tussen accolades staan als code mogen beschouwd worden. Een voorbeeld maakt dit duidelijk:
string zin = $"Ik ben {naam} en ik ben {leeftijd} jaar.";
In dit geval zal de inhoud van de variabele naam tussen de string op de plek waar nu {naam} staat geplaatst worden. Idem voor leeftijd.
Zoals je kan zien is dit veel meer leesbare code dan de eerste manier.
Het resultaat zal dan worden: Ik ben Finkelstein en ik ben 13 jaar.
Je mag eender welke expressie tussen de accolades zetten bij string interpolation, denk maar aan:
string zin = $"Ik ben {leeftijd+4} jaar.";
Alle expressies tussen de accolades zullen eerst uitgevoerd worden voor ze tussen de string worden geplaatst. De uitvoer wordt nu dus: Ik ben 17 jaar.
Eender welke expressie is toegelaten, dus je kan ook complexe berekeningen of zelfs andere methoden aanroepen:
string zin = $"Ik ben {leeftijd*leeftijd+(3*2)} jaar.";
Uiteraard mag je dit dus ook gebruiken wanneer je eenvoudigere zaken naar het scherm wenst te sturen gebruik makende van Console.WriteLine en interpolatie:
Bij string interpolation kan je ook extra informatie meegeven hoe het resultaat juist weergegeven moet worden. Dit noemen we formatteren. Je geeft dit aan door na de expressie, binnen de accolades, een dubbelpunt te plaatsen gevolgd door de manier waarop moet geformatteerd worden.
Wil je een kommagetal tonen met maar 2 cijfers na de komma dan schrijf je:
double number = 12.345;
Console.WriteLine($"{number:F2}");
Er zal 12.35 op het scherm verschijnen. F2 na het dubbelpunt geeft aan dat je een float wilt met 2 beduidende cijfers na de komma.
Merk op dat bij string formattering er afgerond wordt, en dus niet afgekapt.
Nog enkele nuttige vormen:
D5: toon een geheel getal als een 5 cijfer getal. 123 wordt 00123. Maar 123456 zal volledig getoond worden. De Dx formattering werkt enkel op gehele getallen. Uiteraard zijn er dus ook andere varianten zoals D2, etc.
E2: wetenschappelijke notatie met 2 cijfers precisie (12000000 wordt 1,20E+007"1 komma 2 maal tien tot de zevende"). Ook hier hoeft het getal niet 2 te zijn, maar geef je dus via het getal aan tot hoeveel cijfers na de komma je wilt tonen.
C: geldbedrag. 12,34 wordt € 12,34. Het teken en het aantal beduidende cijfers is van de landinstellingen van de pc waarop je code wordt uitgevoerd. Het euro teken zal mogelijk als een ? getoond worden. In de volgende sectie tonen we hoe je dit kan oplossen.
Alle overige format specifiers kan je in de documentatie opzoeken1.
Een andere eenvoudige manier om strings te formatteren is door middel van een masker bestaande uit 0'n. Dit ziet er als volgt uit:
double number = 12.345;
Console.WriteLine($"{number:0.00}");
We geven hierbij aan dat de variabele tot 2 cijfers na de komma moet getoond worden. Indien deze maar 1 cijfer na de komma bevat dan deze toch met twee cijfers getoond worden. Volgende voorbeeld toont dit:
double number = 12.3;
Console.WriteLine($"{number:0.00}");
Er zal 12,30 op het scherm verschijnen.
Je kan dit masker ook gebruiken om te verplichten dat getallen bijvoorbeeld steeds met minimum 3 cijfers voor de komma getoond worden. Volgende voorbeeld toont dit:
double number = 12.3;
double number2 = 99999.3;
Console.WriteLine($"{number:000.00}");
Console.WriteLine($"{number2:000.00}");
Geeft als uitvoer:
012.30
99999.30
Vanaf nu zal ik bijna altijd string interpolatie gebruiken doorheen het boek. Dit is de meest moderne aanpak en zal 99% van de tijd meer leesbare code geven.
In de appendix leg ik uit hoe je vroeger met behulp van String.Format() strings moest samenvoegen (daar je dit soms nog in legacy code zal tegenkomen).
We hebben al gezien dat intern een char als een geheel getal wordt voorgesteld. Stel dat we volgende char-variabelen aanmaken:
char letter1 = 'A';
char letter2 = 'B';
Bij string mogen we de +-operator gebruiken om 2 strings aan elkaar te plakken. Bij char mag dat niet! Of beter, dit mag maar zal niet het resultaat geven dat je mogelijk verwacht wanneer je voor het eerst hiermee leert werken. Oordeel zelf:
Console.WriteLine(letter1 + letter2);
Wanneer je deze code uitvoert dan krijg je 131 te zien (en dus niet "AB" zoals je misschien had verwacht).
Had je dit verwacht? Denk eraan dat het char-type z’n waarde als getallen bijhoudt, de zogenaamde UNICODE-voorstelling van het karakter. Als de compiler het volgende ziet staan:
letter1 + letter2
dan zal de compiler deze twee waarden letterlijk optellen en het nieuw verkregen getal als resultaat geven:
De UNICODE-voorstelling van A is 0x041 oftewel 65. In het geheugen staat dus het geheel getal 65.
B wordt voorgesteld door 66.
Als we dus de variabelen letter1 en letter2 optellen geeft dit 131.
Je zou misschien verwachten dat C# vervolgens het element op plaats 131 in de UNICODE tabel zou tonen.
Dat is niet juist: de +- operator is niet gedefinieerd voor het char datatype, maar wel voor het int datatype. Daarom beschouwt de compiler de operanden letter1 en letter2 als int. De som van twee int waarden geeft een int resultaat. We zien daarom 131 op het scherm in plaats van het UNICODE karakter met waarde 131 (een Latijnse i zonder punt) . In het volgende hoofdstuk leren we hoe je dit wel kunt doen.
Niets is zo leuk als de vreemdste UNICODE tekens op het scherm tonen. In oude console-games werden deze tekens vaak gebruikt om complexe tekeningen op het scherm te tonen. Om je ietwat saaie applicaties dus wat toffer te maken, leg ik daarom uit hoe je dit kan doen.
Je toetsenbord heeft maar een beperkt aantal toetsen. Er zijn echter tal van andere tekens gedefinieerd die console-applicaties ook kunnen gebruiken. We zagen reeds dat al deze tekens, UNICODE-karakters, een eigen unieke code hebben die je kan opzoeken om vervolgens dat teken in je code te gebruiken.
Dit gaat als volgt in z'n werk:
Zoek het teken(s) dat je nodig hebt in een UNICODE-tabel1 en noteer de hexadecimale waarde.
Plaats bovenaan in je Main: Console.OutputEncoding = System.Text.Encoding.UTF8;
Je kan nu op 2 manieren dit teken op het scherm krijgen.
Stel je voor dat we het copyright karakter wensen te gebruiken (de letter c in een cirkeltje) in onze applicatie. Deze heeft hexadecimale UNICODE waarde 0x00A9.
Kopieer het karakter zelf en plaats het in je code waar je het nodig hebt, bijvoorbeeld:
Console.WriteLine("<plak hier je speciale teken>");
Merk op dat niet alle lettertypes dit karakter kennen en dus mogelijk als een vierkantje dit op je scherm zullen tonen. Dit hangt af van het lettertype dat jouw shell-venster gebruikt.
Soms zou je multiline UNICODE-kunst (ook wel ASCII-art genoemd) willen tonen in je C# applicatie. Dit kan je eenvoudig oplossen door gebruik te maken van het @ teken voor een string.
Stel dat je een toffe titel of tekening bijvoorbeeld via ASCIIflow.com maakt. Je kan het resultaat eenvoudig naar je klembord kopiëren en vervolgens in je C#-code integraal copy pasten als literal voor een string op voorwaarde dat je het laat voorafgaan door @" en uiteraard eindigt met ";.
Zowel de $-notatie (voor string interpolatie) als het @-teken kan je gecombineerd gebruiken bij een string:
Console.WriteLine($@"1/1={1+1}. \tGeen tab");
Dit geeft als output (\t wordt door het apenstaartje genegeerd):
1/1=2. \tGeen tab
In de vorige sectie legde ik uit dat we tekst kunnen formateren als een geld bedrag m.b.v. Console.WriteLine($"{12.3456:C}");.
Het probleem was dat het euro-teken als een ? op het scherm verscheen. Dit is omdat het euro-teken een nieuwe karakter is en dus binnen de UNICODE tabellen bestaat, maar niet binnen de klassieke ASCII-tabel.
Willen we dit teken dus gebruiken dan moeten we nog eerst de juiste encoding aanduiden bovenaan:
De Console bibliotheek is maar 1 van de vele bibliotheken die je in je C# programma's kunt gebruiken.
Een andere nuttige bibliotheek is de Environment-bibliotheek. Deze geeft je applicatie allerlei informatie over de computer waarop het programma op dat moment draait. Denk maar aan het werkgeheugen, gebruikersnaam van de huidige gebruiker, het aantal processoren enz.
De laatste zin in vorige alinea is belangrijk: als je jouw programma op een andere computer laat uitvoeren zal je mogelijk andere informatie verkrijgen.
Wil je een programma dus testen dat deze bibliotheek gebruikt, is het aangeraden om het op meerdere systemen met verschillende eigenschappen te testen.
Hier enkele voorbeelden hoe je deze bibliotheek kunt gebruiken (kijk zelf of er nog nuttige properties over je computer in staan):
bool is64bit = Environment.Is64BitOperatingSystem;
string pcname = Environment.MachineName;
int proccount = Environment.ProcessorCount;
string username = Environment.UserName;
long memory = Environment.WorkingSet; //zal ongeveer 10 Mb zijn
Vervolgens zou je dan de inhoud van die variabelen kunnen gebruiken om bijvoorbeeld aan de gebruiker te tonen wat z'n machine naam is:
Console.WriteLine($"Je computernaam is {pcname}");
Console.WriteLine($"Dit programma gebruikt {memory} byte geheugen");
Console.WriteLine($"En je gebruikersnaam is {Environment.UserName}");
Console.WriteLine($"Je hebt {proccount} processoren. 64bit OS? {is64bit}.")
In de laatste lijn code tonen we dat je uiteraard ook rechtstreeks de variabelen uit Environment in je string interpolatie kunt gebruiken en dus niet met een tussenvariabele moet werken.
Je kan in de documentatie1 opzoeken welke nuttige zaken je nog met de bibliotheek kunt doen.
WorkingSet bijvoorbeeld geeft terug hoeveel geheugen het programma van Windows toegewezen krijgt. Als je dus op 'run' klikt om je code te runnen dan zal dit programma geheugen krijgen en via WorkingSet kan het programma dus zelf zien hoeveel het krijgt. Test maar eens wat er gebeurt als je programma maakt dat uit meer lijnen code bestaat.
De Environment bibliotheek heeft ook een methode om je applicatie af te sluiten. Je doet dit met behulp van Environment.Exit(0). Het getal tussen haakjes mag je zelf bepalen en is de zogenaamde exitcode die je wilt meegeven bij het afsluiten. Als je dan later via logbestanden wilt onderzoeken waarom het programma stopte dan kan je dit zien aan de hand van deze exitcode.
Mogelijk was deze laatste sectie wat verwarrend. Dat is bewust gedaan...sort of. C# leren kan in het begin soms nogal saai lijken. Daarom dat ik ervoor kies om hier en daar een iets meer geavanceerd aspect te bespreken.
Zoals al eerder verteld: C# komt met een hele grote hoop bibliotheken (denk maar een Environment en Console). Voor zover ik weet, bestaat er niemand die iedere bibliotheek of klasse kent. Het is aan jou, als gepassioneerde programmeur, om zelf te ontdekken welke bibliotheken je nuttig lijken gegeven een bepaald probleem.
Aah, Data, een geliefkoosd personage uit Star Trek. Maar daar ga ik het niet over hebben. Het wordt tijd dat we onze werkkledij aantrekken en ons echt vuil gaan maken.
De wereld draait op data, en dus ook de meeste applicaties die wij gaan schrijven. We hebben al gezien dat C# met verschillende datatypes werkt. Maar wat gebeurt er als we de inhoud van twee verschillende datatypes willen combineren?! In Star Trek resulteerde dat 50% van de tijd in een aanval van de Borg, 20% van de tijd van de Klingons en in de overige 30% in een oersaaie aflevering (Star Wars for life!). Ahum, sorry. I got carried away.
Laten we eens onderzoeken hoe we data van 'vorm' kunnen veranderen.
May the force be with you! Euh, ik bedoel: Make it so!
Wanneer je de waarde van een variabele wilt toekennen aan een variabele van een ander type mag dit niet zomaar.
Volgende code zal bijvoorbeeld een dikke foutboodschap geven:
int leeftijd = 4.3;
Je kan geen appelen in peren veranderen zonder magie: in het geval van C# zal je moeten converteren of casten.
Dit kan op 3 manieren:
Via casting: de (klassieke) manier die ook werkt in veel andere programmeertalen.
Via de Convert. bibliotheek van .NET.
Via parsing : Deze manier is enkel bruikbaar om strings om te zetten naar andere datatypes.
Het is onmogelijk om een kommagetal aan een geheel getal toe te wijzen zonder dat er informatie verloren zal gaan. Toch willen we dit soms doen. Van zodra we een numerieke variabele van het ene type willen toekennen aan een variabele van een ander numeriek type en er dataverlies zal plaatsvinden dan moeten we aan casting doen.
Casting heb je nodig om een variabele van een bepaald type voor een ander type te laten doorgaan. Stel dat je een complexe berekening hebt waar je werkt met verschillende datatypes. Door te casten voorkom je dat je vreemde resultaten krijgt. Je gaat namelijk bepaalde types even als andere types gebruiken.
Het is belangrijk in te zien dat het casten van een variabele naar een ander type enkel een gevolg heeft tijdens het uitwerken van de expressie waarbinnen je werkt. De variabele in het geheugen zal voor eeuwig en altijd het type zijn waarin het origineel gedeclareerd werd. Je kan dus nooit het datatype van een variabele veranderen!
Casting duid je aan door voor de variabele of literal het datatype tussen haakjes te plaatsen naar wat het omgezet moet worden:
int mijngetal = (int)3.5;
of
double kommagetal = 13.8;
int kommaNietWelkom = (int)kommagetal;
Door casting te gebruiken zeg je eigenlijk aan de compiler 2 zaken:
Volgende variabele die van het type double is, moet aan deze variabele van het type int toegekend worden.
Ik besef dat hierbij data verloren kan gaan (het deel na de komma), maar zet de variabele toch maar om naar het nieuwe type. "Ik draag de volledige verantwoordelijkheid voor de gevolgen hiervan verderop in het programma."
Je dient enkel aan casting te doen wanneer je aan narrowing doet. Bij narrowing gaan we een datatype omzetten naar een ander datatype dat een verlies aan data met zich zal meebrengen.
Het is een voorzorgsmaatregel om te voorkomen dat we de compiler later verwijten dat hij belangrijke gegevens heeft verloren tijdens de omzetting. Door casting te gebruiken, geven we aan dat we de compiler niet de schuld zullen geven van dit dataverlies.
Casting doe je wanneer je een variabele wilt toekennen aan een andere variabele van een ander type dat daar eigenlijk niet inpast zonder dataverlies. We moeten dan aan narrowing doen, letterlijk het versmallen van de data.
Bekijk eens het volgende voorbeeld:
double hoofdMeting;
int secundaireMeting;
hoofdMeting = 20.4;
secundaireMeting = hoofdMeting;
Dit zal niet gaan. Je probeert namelijk een waarde van het type double in een variabele van het type int te steken. Dat gaat enkel als je informatie weggooit (namelijk het gedeelte na de komma). Je moet aan narrowing doen.
Dit gaat enkel als je expliciet aan de compiler zegt: het is goed, je mag informatie weggooien, ik begrijp dat en zal er rekening mee houden. Dit proces van narrowing noemen we casting.
En je lost dit op door voor de variabele die tijdelijk dienst moet doen als een ander type, het nieuwe type, tussen ronde haakjes te typen, als volgt:
double hoofdMeting;
int secundaireMeting;
hoofdMeting = 20.4;
secundaireMeting = (int)hoofdMeting;
Het resultaat in secundaireMeting zal 20 zijn (alles na de komma wordt weggegooid bij casting van een double naar een int ).
Merk op dat hoofdMeting nooit van datatype is veranderd; enkel de inhoud ervan (20.4) werd eruit gehaald, omgezet ("gecast") naar 20 en dan aan secundaireMeting toegewezen dat enkel int aanvaardt.
Stel dat tempGisteren en tempVandaag van het type int zijn, maar dat we nu de gemiddelde temperatuur willen weten. De formule voor gemiddelde temperatuur over 2 dagen is:
int tempGemiddeld = (tempGisteren + tempVandaag)/2;
Test dit eens met de waarden 20 en 25. Wat zou je verwachten als resultaat? Inderdaad: 22,5 (omdat (20+25)/2 = 22.5) . Nochtans krijg je 22 op scherm te zien en zal de variabele tempGemiddeld ook effectief de waarde 22 bewaren en niet 22.5.
Het probleem is dat het gemiddelde van 2 getallen niet noodzakelijk een geheel getal is. Echter, omdat de expressie enkel integers bevat (tempGisteren, tempVandaag en de literal 2) zal ook het resultaat een int zijn. In dit geval wordt alles na de komma gewoon weggegooid, vandaar de uitkomst. Dit is narrowing.
Hoe krijgen we de correctere uitslag te zien? Eens testen wat er gebeurt als we tempGemiddeld als double declareren:
Als we dit testen zal nog steeds de waarde 22.0 aan tempGemiddeld toegewezen worden. De expressie rechts van de toekenning bevat nog steeds enkel integers en de computer zal dus ook de berekening en het resultaat als integer beschouwen, ongeacht dat deze in een double moet gezet worden.
We moeten dus ook de rechterkant van de toekenning als double beschouwen. We doen dit, zoals eerder vermeld, door middel van casting, als volgt:
Let echter op dat niet alle oplossingen bij dit soort oefeningen steeds dezelfde resultaten geeft. Goed testen is de boodschap en nadenken over de volgorde van berekeningen en wat het datatype van ieder tussenresultaat zal zijn. Laten we dat eens analyseren bij voorgaande 4 voorbeelden:
Eerst tellen we twee integers op, wat dus een nieuwe integer geeft, die we vervolgens delen door een double, wat dus een double als resultaat geeft.
Eerst tellen we twee integers op, wat weer een integer geeft, vervolgens zetten we dit resultaat om naar een double en delen dit door een int wat dus een double geeft.
Eerst zetten tempGisteren om naar een double. Vervolgens tellen we een double met een int op, wat een double als tussenresultaat geeft. Dit delen we dan door een int wat een double finaal geeft.
Hetzelfde als de vorige stap, maar nu zetten we eerst tempVandaag om naar een double.
Merk op dat er een subtiel verschil is tussen volgende 2 lijnen code:
In het eerste zullen we het resultaat van de som naar double omzetten. In het tweede, door de volgorde van berekeningen door de haakjes, zullen we de casting pas doen na de deling en zal dus 22 in plaats van 22.5 als resultaat geven.
Casting is niet nodig als je aan widening doet: een kleiner type in een groter type steken (met groter/kleiner wordt de geheugengrootte van het datatype bedoeld), als volgt:
Deze code zal zonder problemen werken: secundaireMeting zal de waarde 20.0 bevatten. De inhoud van hoofdMeting wordt verbreed naar een double, eenvoudigweg door er een kommagetal van te maken.
Er gaat geen inhoud verloren echter. Je hoeft dus niet expliciet de casting-notatie zoals (double)hoofdMeting te doen, de computer ziet zelf dat hij de inhoud van hoofdMeting zonder dataverlies kan toekennen aan secundaireMeting en is dus niet bang dat hij later aangeklaagd zal worden.
Merk op dat je perfect casting hier mag gebruiken, maar daar de conversie impliciet zonder problemen kan plaatsvinden hoeft dit dus niet. Deze code is echter even juist (en soms een veilige gewoonte om te doen, better safe than sorry):
Parsing wordt gebruikt om tekst(string) naar een ander datatype om te zetten (op voorwaarde dat dit kan). Ieder ingebouwd datatype in C# heeft een .Parse() methode die je kan aanroepen om strings om te zetten naar het gewenste type.
Voorbeeld van parsing:
int numVal = Int32.Parse("-105");
Console.WriteLine(numVal);
Gebruik parsing enkel wanneer je:
een string hebt waarvan je weet dat deze altijd van een specifieke vorm zal zijn die omgezet kan worden naar een ander datatype, bv. een int, dan kan je Int32.Parse() gebruiken.
input van de gebruiker vraagt (bv. via Console.ReadLine) en niet 100% zeker bent dat deze een getal zal bevatten, gebruik dan Int32.TryParse() (meer info in de appendix).
De omgekeerde weg: eender welk datatype omzetten naar een string, doe je met de ToString-methode die ieder datatype ingebouwd heeft. Deze methode wordt automatisch aangeroepen wanneer je een variabele van een ander datatype in een string wilt steken, inclusief wanneer je deze in een Console.WriteLine()-statement gebruikt. Toch kan het handig zijn te weten dat je deze methode ook manueel kan aanroepen:
int getal = 5;
string getalAlsString = getal.ToString();
Casting en parsing zijn de 'oldschool' manieren van data omzetten die vooral zeer nuttig is daar deze compacte code geeft en ook werkt in andere C#-gerelateerde programmeertalen zoals C, C++ en Java.
Echter, .NET heeft ook ingebouwde conversie-methoden die je kunnen helpen om data van het ene type naar het andere te brengen. Het nadeel is dat ze iets meer typwerk (en dus meer code) vereisen dan bij casting én dat het geheel een zwarte doos is waarvan je niet weet wat er juist gebeurt. Je zal dus niet weten of er aan parsing of casting wordt gedaan. Het is leuk om te gebruiken, maar je moet wel weten wat je doet.
Al deze methoden zitten binnen de Convert-bibliotheek van .NET. Hou er wel rekening mee dat deze manier van werken iets meer processorkracht vraagt dan casting. In applicaties waar je dus véél data moet omzetten, kan dit een verschil maken (denk aan een game die 60 keer per seconde moet berekenen of een object geraakt wordt door een kogel).
Het gebruik hiervan is zeer eenvoudig. Enkele voorbeelden:
int getal = Convert.ToInt32(3.2); //double to int
double anderGetal = Convert.ToDouble(5); //int to double
bool isWaar = Convert.ToBoolean(1); //int to bool
int leeftijd = Convert.ToInt32("19"); //string to int
int andereLeeftijd = Convert.ToInt32(anderGetal); //double to int
Je plaatst tussen de ronde haakjes de variabele of literal die je wenst te converteren naar een ander type. Merk op dat naar een int converteren met .ToInt32() moet gebeuren. Om naar een short te converteren is dit met behulp van .ToInt16().
De conversie zal zelf zo goed mogelijk de data omzetten en dus indien nodig widening of narrowing toepassen. Zeker bij het omzetten van een string naar een ander type kijk je best steeds de documentatie na om te weten wat er intern juist zal gebeuren.1
Convert.ToBoolean verdient extra aandacht: Wanneer je een getal, eender welk, aan deze methode meegeeft zal deze altijd naar True geconverteerd worden.
Enkel indien je 0 (als int) of 0.0 (als double) ingeeft, dan krijg je False. In quasi alle andere gevallen krijg je True.
Omgekeerd, een bool naar een int converteren zal enkel werken met de respectievelijke Convert.ToInt32() methode én dus niet via casting.
Lees zeker de volgende sectie omtrent afronden, want de Convert.ToX-methoden zullen je soms verrassen wanneer je bijvoorbeeld een double naar een int omzet.
Toegegeven, het is verleidelijk om vanaf nu alles met behulp van de Convert.To-methoden te doen. Het is immers eenvoudiger en je hoeft niet na te denken over narrowing of widening. Besef echter dat andere talen mogelijk enkel parsing en casting ondersteunen en dat je dus best deze methoden ook onder de knie hebt.
Volgende tabel geeft een overzicht van wanneer je best welke methode gebruikt:
En applicatie die geen input van de gebruiker vergt kan even goed een screensaver zijn. We hebben reeds gezien hoe we met Console.ReadLine() de gebruiker tekst kunnen laten invoeren en die we dan vervolgens kunnen verwerken om bijvoorbeeld z'n naam op het scherm te tonen:
De uitdaging met ReadLine is dat deze ALTIJD een string teruggeeft:
string userInput = Console.ReadLine();
Dit mag dus niet: int userInput = Console.ReadLine(); en zal in een conversion error resulteren.
Willen we dat de gebruiker een getal invoert dan zal dit nog steeds als string moeten worden ingelezen. Vervolgens zullen we dit vervolgens moeten converteren.
Invoer van de gebruiker verwerken (dat een andere type dan string moet zijn) zal dus uit 3 stappen bestaan:
Input uitlezen met Console.ReadLine().
Input bewaren in een string variabele.
De variabele parsen met de Parse() bibliotheek naar het gewenste type.
Stel dat we aan de gebruiker z'n gewicht vragen, dan moeten we dus doen:
Voorgaande code veronderstelt dat de gebruiker géén fouten invoert1. De conversie zal namelijk mislukken indien de gebruiker bijvoorbeeld Ik weeg 10kg invoert in plaats van 10,3.
In de komende hoofdstukken mag je er altijd van uitgaan dat de gebruiker foutloze input geeft.
De invoer van kommagetallen door de gebruiker is afhankelijk van de landinstellingen van je besturingssysteem. Staat deze in Belgisch/Nederlands dan moet je kommagetallen met een komma invoeren (9,81). Staat je computer in het Engels dan moet je een punt gebruiken (9.81).
Maar: In je C# code moet je kommagetal literals altijd met een punt schrijven. Dit is onafhankelijk van je taalinstellingen.
1
En wat als je toch foute invoer wilt opvangen? Dan is TryParse je vriend. Meer informatie hierover in de appendix.
Een groot deel van je leven als ontwikkelaar zal bestaan uit het bewerken van variabelen in code. Meestal zullen die bewerkingen voorafgaan van berekeningen. De System.Math bibliotheek zal ons hier bij kunnen helpen. Zoals de naam al doet vermoeden staat deze bibliotheek voor Mathematics: wiskunde!
De Math-bibliotheek bevat handige methoden voor een groot aantal typische wiskundige bewerkingen. Zaken die je er bijvoorbeeld in zal terugvinden:
Sinus (Sin), cosinus (Cos), tangens (Tan), enz. berekenen aan de van de hoek (in radialen)
Vierkantswortel (Sqrt) en macht (Pow) berekenen.
Naar boven (Ceiling) of onder (Floor) afronden.
Absolute (Abs) waarde berekenen.
Stel dat je de derde macht van een variabele getal wenst te berekenen. Zonder de Math-bibliotheek zou dat er zo uitzien:
double result = getal * getal * getal; //SLECHTE MANIER
Dit valt nog mee, maar wat als je 3 tot de zevende macht moest berekenen? Laten we eens kijken hoe Math ons kan helpen, dankzij de Pow methode (Power, Engels voor macht):
double result = Math.Pow(getal, 3);
Deze methode vereist twee parameters:
De eerste is het grondtal.
De tweede is de exponent ("tot de hoeveelste macht").
Als je in Visual Studio Math schrijft in je code, gevolgd door een punt (.) krijg je alles te zien wat de Math-bibliotheek kan doen:
Een kubusje voor een naam wil zeggen dat het om een Methode gaat (zoals Console.ReadLine()). Een vierkantje met twee streepjes in zijn constanten (zoals Pi en het getal van Euler (e)).
De meeste methoden zijn zeer makkelijk in gebruik en werken bijna allemaal op een soortgelijk manier. Meestal moet je 1 of meerdere parameters tussen de haken meegeven en het resultaat moet je altijd in een nieuwe variabele opvangen.
Ook het getal Pi (3.141...) is beschikbaar in de Math-bibliotheek. Het witte icoontje voor PI bij Intellisense toont aan dat het hier om een field gaat: een eenvoudige variabele met een specifieke waarde. In dit geval gaat het zelfs om een const field, met de waarde van Pi van het type double.
const double PI= 3.141...;
Je kan deze als volgt gebruiken in berekeningen zoals
Het bereik van datatypes ligt weliswaar vast (zie hoofdstuk 2). Maar het is nuttig om weten dat deze ook in de compiler gekend is. Ieder datatype heeft een aantal ingebouwde zaken die je kan gebruiken om onder andere de maximum en minimum-waarde van een datatype te gebruiken. Volgend voorbeeld toont hoe dit kan:
Console.Write("Het bereik van het type double is:");
Console.WriteLine($"{double.MinValue} tot {double.MaxValue}.");
Dit geeft op het scherm:
Het bereik van het type double is: -1.7976931348623157*10^308 tot 1.7976931348623157E*10^308.
Je kan met andere woorden met int.MaxValue en int.MinValue het minimum- en maximumbereik van het type int verkrijgen.
Wil je dit van een double, dan gebruik je double.MaxValue enz.
Trouwens, zelfs oneindig is beschikbaar bij kommagetallen als .PositiveInfinity en .NegativeInfinity.
Ondertussen hebben we 3 verschillende manier gezien om getallen af te ronden, namelijk:
Met behulp van casting.
Met behulp van Math.Round .
Met behulp van Convert.ToX.
Ieder manier gaat de data op een andere manier behandelen in het afronden, iets wat we tot nu toe bewust even hebben genegeerd. Bij casting is het duidelijk, deze rondt dus eigenlijk naar beneden af (het zelfde als wanneer je de Math.Floor-methode zou gebruiken). De twee andere manieren hebben enkele venijnige kantjes die we hier even willen bespreken.
Zonder extra informatie zal Math.Round (en ook Convert.ToInt32) altijd afronden naar het dichtstbijzijnde even getal. Dit wordt ook wel bankers rounding genoemd. Dit is een techniek die gebruikt wordt om afrondingsfouten te minimaliseren. Dat is heel leuk en handig voor bankiers, maar voor ons als programmeurs is dit niet altijd even handig.
Gelukkig kunnen we dit gedrag aanpassen door een extra parameter mee te geven aan de Math.Round-methode. Deze parameter is een MidpointRounding-enum. Deze enum heeft meerdere mogelijkheden, maar de meest gebruikte zijn:
ToEven: Dit is de standaardwaarde en zal afronden naar het dichtstbijzijnde even getal. De zogenaamde Bankers rounding dus.
AwayFromZero: Dit zal afronden naar het dichtstbijzijnde getal, ongeacht of het even of oneven is.
De tweede methode is de versie die wij prefereren, omdat deze het meest voorspelbare resultaat geeft. Nemen we terug ons voorbeeld, maar nu met de extra parameter:
Willekeurige (random) getallen genereren in je code kan leuk zijn om de gebruiker een interactievere ervaring te geven. Beeld je in dat je monsters steeds dezelfde weg zouden bewandelen of dat er steeds op hetzelfde tijdstip een orkaan op je stad neerdwaalt. Of wat de denken van een programma dat steeds dezelfde wiskunde opgaven genereert? SAAI!
De Random-bibliotheek laat je toe om willekeurige gehele en komma-getallen te genereren. Je moet hiervoor twee zaken doen:
Maak eenmalig een Random-generator object aan.
Roep de Next methode aan op dit object telkens je een nieuw willekeurig getal nodig hebt.
Als volgt:
Random randomGenerator = new Random();
int mijnLeeftijd = randomGenerator.Next();
De eerste stap dien je maar 1 keer te doen. De naam die je het generatorobject geeft (hier randomGenerator) mag je kiezen. Dit is een variabele en moet dus aan de identifier regels voldoen.
Vanaf nu kan je telkens aan het generatorobject een nieuw getal vragen door middel van de Next-methode.
Volgende code toont bijvoorbeeld 3 random getallen op het scherm:
Random myGen = new Random();
int getal1 = myGen.Next();
int getal2 = myGen.Next();
int getal3 = myGen.Next();
Console.WriteLine(getal1);
Console.WriteLine(getal2);
Console.WriteLine(getal3);
Uiteraard mag dit ook
Console.WriteLine(myGen.Next());
Console.WriteLine($"Nog een getal: {myGen.Next()}");
De new Random() code is iets wat in hoofdstuk 9 en verder volledig uit de doeken zal gedaan worden. Lig er dus nog niet van wakker.
Je kan de Next methode ook 2 parameters meegeven, namelijk de grenzen waarbinnen het getal moet gegenereerd worden. De tweede parameter is exclusief dit getal zelf. Wil je dus een willekeurig geheel getal tot en met 10 dan schrijf je 11, niet 10, als tweede parameter:
Enkele voorbeelden:
Random someGenerator = new Random();
int a = someGenerator.Next(0,11); //getal tussen 0 tot en met 10
int b = someGenerator.Next(55,100); //getal tussen 55 tot en met 99
int c = someGenerator.Next(0,b); //getal tussen 0 tot en met (b-1)
Met de NextDouble methode kan je kommagetallen genereren tussen 0.0 en 1.0 (1.0 zal niet gegenereerd worden).
Wil je een groter kommagetal dan zal je dit gegenereerde getal moeten vermenigvuldigen naar de range die je nodig hebt.
Stel dat je een getal tussen 0.0 en 10.0 nodig hebt, dan schrijf je:
Random myRan = new Random();
double randomGetal = myRan.NextDouble() * 10.0;
Je vermenigvuldigt eenvoudigweg je gegenereerde getal met het bereik dat je wenst (10.0 in dit geval)
En wat als je een kommagetal tussen 5.0 en 12.5 wenst? Als volgt:
Random myRan = new Random();
double randomGetal = 5.0 + (myRan.NextDouble() * 7.5);
Je bereik is 7.5, namelijk 12.5 - 5.0 en vermenigvuldig je het resultaat van je generator hiermee. Vervolgens verschuif je dat bereik naar 5 en verder door er 5 bij op te tellen. Merk op dat we de volgorde van berekeningen sturen met onze ronde haakjes.
"Help! Ik krijg steeds dezelfde random getallen? Wat nu?"
Wel wel, wie we hier hebben. Werkt je Random generator niet naar behoren? Wil je het ding in de vuilbak gooien omdat het niet zo willekeurig lijkt te werken als je hoopte? Gelukkig ben ik er! Zet je helm dus op en luister.
Wanneer je twee Random objecten aanmaakt op quasi hetzelfde tijdstip in je code, dan zullen deze twee generators ook dezelfde getallen genereren:
Random a = new Random();
Random b = new Random(); //Slecht idee!
Console.WriteLine(a.Next());
Console.WriteLine(b.Next());
De Random bibliotheek gebruikt de tijd als een soort "willekeurig" startpunt (de tijd is de zogenaamde seed). Het is namelijk een pseudo-willekeurige getal generator.
Dit is de reden waarom je in je code steeds maar 1 Random generator mag aanmaken! Er zijn weinig redenen om er meerdere aan te maken. Bovenstaande code is dus niet aan te raden. Je schrijft beter:
Random a = new Random();
Console.WriteLine(a.Next());
Console.WriteLine(a.Next());
Wil je toch dezelfde willekeurige reeks getallen na elkaar genereren telkens je je programma opstart (bijvoorbeeld om je code te testen met steeds dezelfde reeks getallen) dan kan je bij het aanmaken van je generator ook een parameter meegeven die als seed zal werken.
In het volgende voorbeeld zal generator a steeds dezelfde reeks willekeurige getallen genereren, telkens je je programma uitvoert. De waarde die je meegeeft moet uiteraard niet 666 zijn. Ieder getal dat je meegeeft is een andere seed:
Random a = new Random(666);
Console.WriteLine(a.Next());
"Joepie!! M'n code werkt!" Je ontkurkt de champagne/bier/melk/frisdrank/water, doet een Fortnite danske en laat je programma door duizenden, neen ... miljoenen gebruikers ontdekken. Nog geen uur later staat er een meute met hooivorken en toortsen voor je kantoor. Helaas, er zaten nog "een paar bugs" in je code...
Tijd dus om je debugger boven te halen en die (logische) fouten uit je code te halen.
Code die compileert is enkel code die foutloos geschreven is volgens de C# afspraken qua grammatica en syntax. De code zal met andere woorden gecompileerd worden, maar wat er daarna gebeurd is volledig afhankelijk van wat juist de betekenis is van wat je hebt geschreven.
Volgend algoritme bijvoorbeeld is perfecte Nederlandstalige code en zal dus door een fictieve compiler kunnen gecompileerd worden. Het vervolgens uitvoeren is echter niet aan te raden (natrium en water samen geeft een stevige exotherme reactie):
Neem natrium
Neem water
Voeg beide samen
Dit is dus een logische fout: oftewel een bug (in dit geval zal dit trouwens een stevige explosie veroorzaken).
Standaard wanneer je je code uitvoert met de grote groene playknop start jouw programma in zogenaamde "debug modus". Dit laat je toe om je code ten allen tijde te onderbreken en naar de huidige staat van je programma te kijken. Je kan dan bijvoorbeeld onderzoeken wat de waarden van bepaalde variabelen zijn op dat moment en of die wel correct zijn. Dit is bughunting en zal je héél vaak doen in je programmeer-carrière.
Om dit te doen moet je één of meer breakpoints in je code plaatsen. Een breakpoint zet je aan een lijn code. Wanneer je programma dan aan deze lijn komt tijdens de uitvoer zal de debugger alles pauzeren.
Een breakpoint plaats je door in VS op het grijze gedeelte links van de lijn code te klikken. Als alles goed gaat verschijnt er dan een grote rode "breakpointbol":
In bovenstaande figuur plaatsen we een breakpoint aan lijn 11. De code uitvoer zal dus nog wel lijn 10 uitvoeren, maar niet lijn 11.
Als je nu je project uitvoert zal de code pauzeren aan die lijn en zal VS in "debug modus" openspringen wat er vervolgens als volgt uit ziet:
In dit "nieuwe" scherm zijn er momenteel 2 belangrijke delen:
Onderaan zie je de autos en locals . In deze tabs kan je de waarden van iedere variabele in je huidige code zien op het moment van pauzeren. Ideaal om te onderzoeken waarom een bepaalde berekening of expressie niet doet wat ze moet doen.
Bovenaan zijn enkele debug-knoppen verschenen. Deze licht ik in de volgende sectie toe.
Voorts kan je in debug-modus met je muis over eender welke variabele of expressie hoveren om het resultaat van dat element te bekijken:
Wanneer je gepauzeerd bent kan je de nieuw verschenen debug-knoppen bovenaan VS gebruiken om het verdere verloop te bepalen:
Ik bespreek hier de knoppen die je zeker zal nodig hebben:
De continue knop is logisch: hier op klikken zal je programma terug voortzetten vanaf het breakpoint waar je gepauzeerd bent. Het zal vervolgens verder gaan tot het weer een breakpoint bereikt of wanneer het einde van het programma wordt bereikt.
De step in knop zullen we in hoofdstuk 7 toelichten daar deze knop je toelaat om in een methode te springen.
De rode stop knop gebruik je indien je niet verder wilt debuggen en ogenblikkelijk terug je code wilt aanpassen.
De step-over knop (het gebogen pijltje) is een belangrijke knop. Deze zal je code één lijn code verder uitvoeren en dan weer pauzeren. Het laat je dus toe om letterlijk doorheen je code te stappen. Je kan dit doen om de flow van je programma te bekijken (zie volgende hoofdstukken) en om te zien hoe bepaalde variabelen evolueren doorheen je code.
Pfft. Debuggen. Waarom moet ik me daar nu mee bezig houden?
Even je oren open zetten aub, ik ga iets roepen:"Debugging is een ESSENTIËLE SKILL!!!". Ik laat mijn metselaars ook geen huizen bouwen zonder dat ze ooit een truweel hebben vastgepakt. Een programmeur die niet kan debuggen...is als een vis die niet kan zwemmen!
Zorg dus dat je vlot breakpoints kunt plaatsen om zo tijdens de uitvoer te pauzeren om de inhoud van je variabelen te bekijken (via het watch-venster). Gebruik vervolgens de "step"-buttons om door je code te 'stappen', lijn per lijn.
Is that all?! NEEN! Een goede programmeur zal telkens eerst voorspellen wat er gaat gebeuren: welke waarden zullen de variabelen hebben als ik naar de volgende lijn ga? Wat gaat er op het scherm komen? enz. Als je dan vervolgens naar de volgende lijn of breakpoint gaat en er gebeuren dingen die je niet voorspeld had, dan is de kans groot dat je een bug hebt gevonden.
De grootste fout die je kunt doen is gewoon door je code te "steppen" en hopen dat de bug magisch zal tevoorschijn komen. Neen, zo werkt het dus niet. Je moet actief mee denken of dat je programma effectief werkt zoals je zelfs bedoeld had.
Dit geldt trouwens ook wanneer je niet aan het debuggen bent, maar gewoon je programma uitvoert om het te testen. Eigenlijk ben je dan ook aan het debuggen. Ook dan moet je voorspellen wat het eindresultaat zal zijn en of dit overeen komt met wat er op het scherm gebeurt. Wees kritisch!
OPGELET: dit hoofdstuk is in opbouw en nog niet klaar
We hebben nu al enkele hoofdstukken A.I. angstvallig in de stal gelaten. Laten we dat wilde, krachtige beest eens buitenlaten en in een omheind veldje zetten. In deze gloednieuwe sectie wil ik je enkele handvaten geven hoe je A.I. kunt gebruiken de komende maanden, in je avontuur om de beste C# programmeur ooit te worden.
We zullen enkele typische prompts bespreken die je kan gebruiken, waarbij we willen benadrukken dat:
een prompt nooit feilloos is. Of beter: het resultaat van de prompt. Je mag nog zo'n gefinetuned prompt hebben, maar de A.I. zal altijd fouten maken. Het is dus cruciaal dat je altijd kritisch bent over de output
alhoewel je - zeker aan de start van je C# avontuur- meestal 100% perfecte oplossingen zult terugkrijgen, deze oplossingen vaak of te complex zijn, of zich niet houden aan de specifieke afspraken die wij hanteren (denk aan schrijfwijze, naamgeving, het wel of niet toelaten van bepaalde methoden, etc.). Je zou dit allemaal in je prompt kunnen zetten, maar dat maakt de prompt dan weer onnodig complex. Je zal dus vaak zelf nog wat moeten bijsturen.
Het zal wel duidelijk zijn dat er één type prompt is die je als beginnende programmeur nooit mag gebruiken. Het is eigenlijk dezelfde prompt als dat je naar een drievoudig Tour de France winnaar zou gaan en hem vragen om even de Mont Ventoux voor jou op te fietsen, met jou achterop zijn rug. Je zal aan de top geraken, maar je zal zelf weinig geleerd hebben, omdat je je grijze hersenmassa - of in dit voorbeeld spiermassa- niet hebt gebruikt.
En dus volgt hier de verboden prompt:
Schrijf de C# oplossing voor deze opgave: [gevolgd door de opgave].
Doe het gerust eens met een oefening die je al hebt gemaakt. Zeker de oefeningen van de eerste hoofdstukken zullen vaak perfect zijn.
De leukste prompt die je kan gebruiken is de zoek-de-fout-prompt. Hierbij vraag je A.I. om een oplossing te schrijven, maar met opzet fouten in te bouwen. Vervolgens moet jij deze fouten opsporen en verbeteren. Dit is een uitstekende oefening om je kennis te testen en te verdiepen. Het is hierbij belangrijk dat je benadrukt dat de A.I. de fouten niet aanduidt, maar dat jij ze moet vinden.
Schrijf de C# oplossing voor deze opgave: "Vraag aan de gebruiker zijn naam. Toon de naam, gevolgd door de zin 'wat een mooie naam!'."
Zorg ervoor dat er minstens drie fouten in de code zitten die een beginnende programmeur zou kunnen maken. Geef geen uitleg, alleen de code. Ik zal de fouten vervolgens proberen te vinden en te corrigeren.
Zeker voor de beginnende hoofdstukken kan het geen kwaad dat je toevoegt dat alle zogenaamde boilerplate code (zoals de using statements, de namespace, de class Program en de static void Main) niet getoond moet worden bij het zoeken naar fouten. Zo kan je je focussen op het échte probleem. Voeg daarom dit nog toe aan je prompt:
Je hoeft de boilerplate code (zoals de using statements, de namespace, de class Program en de static void Main) niet te tonen.
Je krijgt bij de oefeningen ook steeds de oplossing. Zoals steeds raad ik je aan hier pas naar te gaan kijken wanneer je zelf een poging hebt gedaan. Vervolgens kan je jouw oplossing vergelijken en reflecteren over de verschillen.
Via volgende prompt kan je A.I. vragen om jouw oplossing te vergelijken met de zijne, en de verschillen uit te leggen:
Vergelijk mijn volgende code met modeloplossing voor deze opgave: [gevolgd door de opgave]. Leg de verschillen uit en waarom jouw oplossing beter is.
Mijn code is:
[gevolgd door jouw code].
Dit is de modeloplossing::
[gevolgd door de modeloplossing].
Je kan dit nog specifieker maken door te vragen om te focussen op bepaalde aspecten, zoals efficiëntie, leesbaarheid, naamgevingen of het volgen van best practices.
Focus op hoe duidelijk mijn naamgevingen zijn in vergelijking met die van de modeloplossing.
We kunnen deze prompt een stuk interactiever maken door de A.I. als een tutor te gebruiken, waarbij jij als gebruiker moet aangeven waar je vindt dat de verschillen zitten en waarom. De A.I. zal dan feedback geven op jouw analyse en eventueel bijvragen stellen om je begrip te verdiepen.
De prompt ziet er dan zo uit:
Vergelijk mijn volgende code met modeloplossing voor deze opgave: [gevolgd door de opgave].
Ik zal aangeven wat ik anders vind aan mijn code in vergelijking met de modeloplossing. Geef feedback op mijn analyse en stel vragen om mijn begrip te verdiepen.
Mijn code is:
[gevolgd door jouw code]
Dit is de modeloplossing:
[gevolgd door de modeloplossing].
Je mag me nu ondervragen over de verschillen die ik zal aangeven.
ChatGPT en friends worden pas krachtig wanneer je ermee in een dialoog gaan. Anders is het maar een searchengine on steroids.
Bovenstaande tutor-prompt, waarin je interactie eist van de A.I., zal je leerproces veel krachtiger maker, daar het vereist dat je ook zelf actief nadenkt over de verschillen en je, hopelijk, begrip van de concepten verdiept.
Ervaren programmeurs zien snel dat veel opdrachten eigenlijk varianten zijn van elkaar. Vaak is de context het enige dat verschilt. Een oefening waarin je leeftijden van 10 mensen moet vragen en het gemiddelde moet berekenen, kan even goed een oefening zijn waarin je de lengtes van 30 slangen moet vragen en het gemiddelde moet berekenen.
Dit inzicht kan je ook gebruiken in je prompts. Je kan A.I. vragen om een variant te maken van een bestaande oefening, waarbij je zelf de context aanlevert.
Maak een variant van deze opgave: [gevolgd door de opgave]. Gebruik een andere context, maar behoud dezelfde structuur en moeilijkheidsgraad. Geef alleen de nieuwe opgave, zonder oplossing.
Uiteraard wordt het nog langer als je zelf in de prompt aanlevert. Zo kan je oefeningen laten maken over onderwerpen die jou (meer) interesseren. Het nadeel van deze prompt is dat de opgaves vaak wat ongeïnspireerd zijn van zodra je de truuk doorhebt. Je kan dit oplossen door de prompt iets meer vrijheid te geven:
Maak een variant van deze opgave: [gevolgd door de opgave].
Gebruik een andere context, maar behoud dezelfde structuur en moeilijkheidsgraad. Geef alleen de nieuwe opgave, zonder oplossing. Probeer de context zo creatief mogelijk te maken. Het belangrijkste is de structuur en moeilijkheidsgraad behouden.
Vaak weet een goed programmeur ongeveer wat de output van een stuk code zal zijn, zonder dat hij de code ook effectief zal uitvoeren. Dit is een belangrijke vaardigheid, omdat het je helpt om code te begrijpen en te debuggen.
Deze prompt zal je helpen om dit te oefenen (merk op dat je dit ook zonder A.I. kan doen, maar het is leuk om te zien of de A.I. hetzelfde antwoord geeft als jij).
Jij bent mijn ondervrager. Je toont me telkens een stukje C#-code (maximaal 10 regels) en ik moet je vertellen wat de output zal zijn als deze code wordt uitgevoerd. Na mijn antwoord, leg je uit waarom dat het geval is. Als mijn antwoord fout is, leg je uit wat de juiste output is en waarom.
Bij dit soort oefeningen bestaat het gevaar dat de A.I. je ondervraagt over zaken die je nog niet kent (dit geldt ook voor eerdere oefeningen). Je lost dit op door expliciet aan te geven hoe ver je al bent in het leren werken met C#.
Stel dat je tot en met hoofdstuk 8 van dit handboek bent (arrays), dan zou je dit kunnen toevoegen aan de prompt:
Je mag me alleen ondervragen over C# concepten die ik al ken, namelijk: variabelen, datatypes, operators, conditionals (if/else), loops (for, while), arrays en methoden (zonder parameters en met parameters). Gebruik geen geavanceerde concepten zoals klassen, objecten, en andere OOP concepten. Ook LINQ, async/await, delegates, events of generics mag je niet gebruiken.
Vaak schrijven beginnende programmeurs mooi werkende code, die echter soms te complex of onnodig lang is. Dit kan het moeilijk maken om de code te begrijpen en te onderhouden. Via deze prompt kan je leren om code te vereenvoudigen en te optimaliseren:
Je gaat me trainen in het oefenen van het vereenvoudigen van C# code. Genereer telkens een stukje code (maximaal 10 regels) dat correct werkt, maar op een onnodig complexe of lange manier is geschreven. Ik zal proberen de code te vereenvoudigen en optimaliseren. Na mijn poging, geef je feedback op mijn vereenvoudiging en leg je uit hoe ik het nog beter kan doen.
Er zijn natuurlijk honderden manieren tegenwoordig om A.I. te gebruiken in je leerproces. Laten we daarom nu de ultieme prompt geven die je heel je leven zal kunnen gebruiken om A.I. te helpen om je te helpen:
Je bent de beste leerkracht en coach ooit. Je bent kritisch, maar geeft opbouwende feedback, zonder ooit de oplossing voor een probleem te geven. Je gebruikt alle truken uit je arsenaal om mij een beter C# programmeur te maken. Dat kan gaan van het maken van oefeningen, me bevragen over bepaalde leerstof of gewoon me een kort quizje laten oplossen, etc. Alle pedagogische en didactische trucs mogen gebruikt worden.
Je daagt me uit, maar helpt me ook als ik vastzit. Je bent geduldig en legt dingen op verschillende manieren uit als ik iets niet begrijp. Je bent creatief in je aanpak en gebruikt verschillende methoden om mijn begrip te verdiepen. Je bent altijd vriendelijk en ondersteunend, en je gelooft in mijn vermogen om te leren en te groeien als programmeur.
Of als je echt geen inspiratie hebt. Vraag gewoon aan A.I. wat leuke prompts zijn die je in de toekomst kan gebruiken om jezelf te verbeteren ;).
Nu we de elementaire zaken van C# en VS kennen is het tijd om onze programma's wat interessanter te maken. De programma's die we tot nu toe hebben ontwikkeld waren steevast lineair van opbouw. Ze werden lijn per lijn uitgevoerd, van start tot einde, zonder de mogelijkheid om de program flow aan te passen. Het programma doorliep de lijnen code braaf na elkaar en wanneer deze aan het einde kwam sloot het zich af.
Onze programma's waren met andere woorden niet meer dan een eenvoudige lijst van opdrachten. Je kan het vergelijken met een lijst die je over hoe je een brood moet kopen:
Neem geld uit spaarpot
Wandel naar de bakker om de hoek
Vraag om een brood
Krijg het brood
Betaal het geld aan de bakker
Keer huiswaarts
Smullen maar
Alhoewel dit algoritme redelijk duidelijk is en goed zal werken, zal de realiteit echter zelden zo rechtlijnig zijn. Van zodra 1 van de stappen faalt (bijvoorbeeld omdat de bakker toe is) zal ook de rest van het algoritme niet meer werken.
Een beter algoritme zal afhankelijk van de omstandigheden (bakker gesloten, geen geld meer, enz.) andere stappen ondernemen. Het programma zal beslissingen maken gebaseerd op keuzes doorheen het programma:
Neem geld uit spaarpot
Geld op? Stop dan hier, anders: ga verder
Wandel naar de bakker om de hoek
Bakker toe? Stop dan hier, anders: ga verder
Vraag om een brood
Krijg het brood
Betaal het geld aan de bakker
Als je honger hebt, sla dan volgende lijn over, anders: ga verder
Keer huiswaarts
Smullen maar
Om beslissingen te kunnen nemen in C# hebben we een nieuw soort operators nodig. Operators waarmee we kunnen testen of iets waar of niet waar is. Met C# kun je een actie uitvoeren als een voorwaarde waar is, en iets anders doen (of een stap overslaan) als de voorwaarde niet waar is.
Dit doen we met de zogenaamde relationele operators en logische operators.
Een booleaanse expressie is een stuk C# code dat een bool als resultaat zal geven. De logische en relationele operators die ik hierna bespreek zijn operators die een bool teruggeven. Ze zijn zogenaamde test-operators: ze testen of iets waar is of niet.
Relationele operators zijn het hart van booleaanse expressies. En guess what, je kent die al van uit het lager onderwijs. Enkel de "gelijk aan" ziet er iets anders uit dan we gewoon zijn uit onze lessen wiskunde:
Operator
Betekenis
>
groter dan
<
kleiner dan
==
gelijk aan
!=
niet gelijk aan
<=
kleiner dan of gelijk aan
>=
groter dan of gelijk aan
Deze operators hebben steeds twee operanden nodig en geven een bool als resultaat terug. Beide operanden moeten van hetzelfde datatype zijn. Je kan geen appelen met peren vergelijken!
Daar dit operators zijn kan je deze dus gebruiken in eender welke expressie. Het resultaat van de expressie 12 > 6 zal true als resultaat hebben daar 12 groter is dan 6. Eenvoudig toch.
We weten al dat je het resultaat van een expressie altijd in een variabele kunt bewaren. Ook bij het gebruik van relationele operators kan dat dus:
Er zal false als output op het scherm verschijnen.
Er is een groot verschil tussen de = operator en de == operator. De eerste is de toekenningsoperator en zal de rechtse operand aan de linkse operand toewijzen. De tweede zal de linkse met de rechtse operand op gelijkheid vergelijken en een bool teruggeven.
Vaak wil je meer complexe keuzes maken, zoals :"ga verder indien je hongerig bent EN je genoeg geld bijhebt". Dit doen we met de zogenaamde logische operators.
Er zijn 3 (booleaanse) operators die je hiervoor kunt gebruiken:
&& (EN) : Geeft enkel true als beide operanden true zijn
! (NIET) : Inverteert de waarde van de expressie (true wordt false en omgekeerd)
De logische operators geven ook steeds een bool terug maar verwachten enkel operanden van het type bool. Als je dus schrijft true || false zal het resultaat true zijn.
De EN en OF operators verwachten 2 operanden. Maar de NIET-operator verwacht maar 1 operand.
Aangezien onze relationele operators bool als resultaat geven, kunnen we dus de uitvoer van deze operators gebruiken als operanden voor de logische operators. We gebruiken hierbij haakjes om zeker de volgorde juist te krijgen:
bool result = (4 < 6) && ("ja" == "nee");
De haakjes zorgen ervoor dat eerste die delen worden berekend. Voorgaande zal dus in een tussenstap (die jij niet ziet) tijdens de uitvoer er als volgt uitzien:
bool result = true && false;
Vervolgens wordt dan de logische EN getest en krijgen we finaal false in result.
Je kan de niet-operator voor een expressie zetten om het resultaat van de expressie te inverteren. Bijvoorbeeld:
bool result = !(0==2)
Eerst wordt weer het resultaat tussen de haakjes berekend. Dit geeft false (daar 0 niet gelijk is aan 2). Vervolgens passen we de NIET-operator toe op dit resultaat en zal er dus true bewaard worden.
Merk op dat we deze code ook kunnen schrijven als:
bool result = (0!=2)
Alhoewel we voorgaande ook zonder haakjes kunnen schrijven, raad ik dit af. Haakjes zorgen ervoor dat je code leesbaarder wordt. Maar nog belangrijker: het maakt de volgorde van bewerkingen explicieter. Als je niet zeker weet welke operator voorrang heeft, kun je haakjes gebruiken om de juiste volgorde af te dwingen. Dit helpt je om logische fouten te voorkomen die kunnen ontstaan door verkeerde veronderstellingen.
De if (als) uitdrukking is één van de meest elementaire uitdrukkingen in een programmeertaal. Het laat ons toe vertakkingen in onze programmaflow in te bouwen. Ze laat toe om "als dit waar is doe dan dat"-beslissingen te maken.
De syntax is als volgt:
if (booleaanse expressie)
{
//deze code wordt uitgevoerd indien
//de booleaanse expressie true is
}
Enkel indien de booleaanse expressie waar is (true ), zal de code binnen de accolades van het if-blok uitgevoerd worden. Indien de expressie niet waar is (false) dan wordt het blok overgeslagen en gaat het programma verder met de code eronder.
Een voorbeeld:
int nummer = 3;
if ( nummer < 5 )
{
Console.WriteLine ("Ja");
}
Console.WriteLine("Nee");
De uitvoer van dit programma zal zijn:
Ja
Nee
Indien nummer groter of gelijk aan 5 was dan zou er enkel Nee op het scherm zijn verschenen. De lijn Console.WriteLine("Nee"); zal sowieso uitgevoerd worden zoals je ook kan zien in de flowchart op de volgende pagina.1
1
Code2flow.com is een handige tool om je reeds geschreven C# code om te zetten naar een flowchart. Het kan je helpen om vreemde bugs te ontdekken. Uiteraard is de eerste stap debuggen en door je code steppen: vaak zal je ogenblikkelijk zien waar je code verkeerd loopt.
Het is aangeraden om steeds na de if-expressie met accolades te werken. Dit zorgt ervoor dat alle code tussen het block (de accolades) zal uitgevoerd worden indien de booleaanse expressie waar was. Gebruik je geen accolades dan zal enkel de eerste lijn na de if uitgevoerd worden bij true.
Een voorbeeld:
if ( nummer < 5 )
{
Console.WriteLine ("Ja");
Console.WriteLine ("Nee");
}
Voorman hier! Je hebt me gemist. Ik merk het. Het ging goed de laatste tijd. Maar nu wordt het tijd dat ik je weer even wakker schud want de code die je nu gaat bouwen kan érg vreemde gedragingen krijgen als je niet goed oplet. Luister daarom even naar deze lijst van veel gemaakte fouten wanneer je met if begint te werken.
De types in je booleaanse expressie moeten steeds vergelijkbaar zijn. Volgende code zal niet compileren:
if( "4" > 3)
daar we hier een string met een int vergelijken. Meestal moeten dus beide operanden bij een relationele operator van het zelfde type zijn (of er moet een implicietie, automatische casting kunnen gebeuren).
Accolades vergeten plaatsen om een codeblock aan te duiden is een typische fout. Wanneer je bijvoorbeeld Python hebt geleerd, dan zou je verwachten dat je code zodanig kan uitlijnen (met tabs of spaties) om code bij een if te groeperen in een block. Wat dus niet zo is. Je code uitlijnen heeft in C# géén invloed op de programflow.
Gebruik je dus geen accolades dan zal enkel de eerste lijn na de if zal uitgevoerd worden indien true. Gebruiken we de if met block van daarnet maar zonder accolades dan zal de laatste lijn altijd uitgevoerd worden ongeacht de if:
if ( tijd < 20 )
Console.WriteLine ("Doe zo voort.");
Console.WriteLine ("Je bent er bijna!"); //verschijnt altijd op scherm
Deze code zal dus 2 mogelijke outputs op het scherm geven. Indien de tijd groter of gelijk is aan 20 dan krijgen we volgende output:
Je bent er bijna!
Maar indien de tijd kleiner is dan 20 krijgen we:
Doe zo voort.
Je bent er bijna!
Dit is uiteraard niet de output die we verwachten. We willen de motiverende boodschappen (beide zinnen) enkel tonen indien de gebruiker nog tijd heeft. De juiste oplossing is:
if ( tijd < 20 )
{
Console.WriteLine ("Doe zo voort.");
Console.WriteLine ("Je bent er bijna!");
}
Dit zal ervoor zorgen dat er eigenlijk geen codeblock bij de if hoort en je dus een nietszeggende if hebt geschreven. De code na het puntkomma zal uitgevoerd worden ongeacht de if:
if ( naam == "neo" );
{
Console.WriteLine ("Take the red pill?");
Console.WriteLine ("Or the blue pill?");
}
De uitvoer van voorgaande zal altijd de volgende zijn, ongeacht of de gebruikersnaam gelijk is aan "neo":
Take the red pill?
Or the blue pill?
Indien de naam gelijk is aan "neo" dan zal de code tussen de if en het kommapunt op lijn 1 uitgevoerd worden. Kortom, er wordt niets gedaan (daar hier geen code staat). Het block erachter dat de 2 zinnen op het scherm zet wordt altijd uitgevoerd.
Met "if - else" kunnen we niet enkel zeggen welke code moet uitgevoerd worden als de conditie waar is maar ook welke specifieke code moet uitgevoerd indien de conditie niet waar is. Volgend voorbeeld geeft een typisch gebruik van een "if - else" structuur om 2 waarden met elkaar te vergelijken:
const int waterpeil = 10;
int MAX = 5;
if ( waterpeil > MAX )
{
Console.WriteLine ($"Waterpeil staat te hoog!");
}
else
{
Console.WriteLine ($"Waterpeil is in orde.");
}
Een veel gemaakte fout is bij de else sectie ook een booleaanse expressie plaatsen. Dit kan niet: de else sectie zal gewoon uitgevoerd worden indien de if sectie NIET uitgevoerd werd. Volgende code MAG DUS NIET:
Met een "if - else if" constructie kunnen we meerdere criteria opgeven die waar/niet waar moeten zijn voor een bepaald stukje code kan uitgevoerd worden.
Sowieso begint men steeds met een if. Als men vervolgens een else if plaatst dan zal de expressie van deze else if getest worden enkel en alleen als de eerste expressie niet waar was. Als de expressie van deze else if wel waar is zal de bijhorende code uitgevoerd worden, zo niet wordt deze overgeslagen.
Een voorbeeld:
int x = 9;
if (x == 10)
{
Console.WriteLine ("x is 10");
}
else if (x == 9)
{
Console.WriteLine ("x is 9");
}
else if (x == 8)
{
Console.WriteLine ("x is 8");
}
Voorts mag men ook steeds nog afsluiten met een finale else die zal uitgevoerd worden indien geen enkele andere expressie ervoor waar bleek te zijn:
if(x>100)
{
Console.WriteLine("Groter dan 100");
}
else if(x>10)
{
Console.WriteLine("Groter dan 10");
}
else
{
Console.WriteLine("Getal kleiner dan of gelijk 10");
}
De volgorde van opeenvolgende "if - else if - else" tests is uiterst belangrijk. Als we in de voorgaande code de volgorde van de twee tests omdraaien, zal het tweede blok (x > 100) nooit worden bereikt.
Logisch: neem een getal groter dan 100 en laat het door onderstaande code lopen. Stel, we nemen 110. Al bij de eerste test (x>10) is deze true en verschijnt er dus "Groter dan 10". Alle andere tests worden daarna niet meer gedaan en de code gaat verder na het else-blok:
if(x>10)
{
Console.WriteLine("Groter dan 10");
}
else if(x>100)
{
Console.WriteLine("Groter dan 100");
}
else
//...
Hoe minder tests de computer moet doen, hoe meer performant de code zal uitgevoerd worden. Voor complexe applicaties die bijvoorbeeld in realtime veel berekeningen moeten doen kan het dus een gigantische invloed hebben of een reeks "if - else if else" testen vlot wordt doorlopen. Het is dan ook een goede gewoonte - indien de logica van het algoritme het toelaat - om de meest voorkomende test bovenaan te plaatsen.
Dit zelfde geldt ook binnen een test zelf wanneer we met logische operators werken. Deze worden altijd volgens de regels van de volgorde van berekeningen uitgevoerd. Volgende test wordt van links naar rechts uitgevoerd:
x > 100 && a != "stop"
Omdat beide operanden van de EN-operatie true moeten zijn om een juiste test te krijgen, zal de computer de test automatisch stoppen indien reeds de linkse operand (x > 100) niet waar is. Bij dit soort tests probeer je dus ervoor te zorgen dat de tests die het minste kans op slagen hebben (of beter: het vaakst niét zal slagen) eerst te laten testen, zodat de computer geen onnodige extra tests doet.
We kunnen met behulp van nesting ook complexere programma flows maken. Nesting wil zeggen dat we meerdere codeblocken in elkaar plaatsen. Hierbij gebruiken we de accolades om het blok code aan te duiden dat bij een "if - else if - else" hoort. Binnen dit blok kunnen nu echter opnieuw beslissingsstructuren worden aangemaakt.
Volgende voorbeeld toont dit aan. We zien hoe nesting wordt toegepast in het else gedeelte else. Bekijk wat er gebeurt als je dokterVanWacht aan iets anders gelijkstelt dan een lege string:
const double MAX_TEMP = 40;
double huidigeTemperatuur = 36.5;
string dokterVanWacht = "";
if (huidigeTemperatuur < MAX_TEMP)
{
Console.WriteLine("Temperatuur normaal");
}
else
{
Console.WriteLine("Temperatuur te hoog!");
if (dokterVanWacht == "")
{
Console.WriteLine("Oei oei! Geen dokter van wacht!");
}
else
{
Console.WriteLine($"{dokterVanWacht} gecontacteerd");
}
}
We kunnen ook meerdere booleaanse expressie combineren zodat we complexere uitdrukkingen kunnen maken. Stel dat we een if nodig hebben waar enkel ingegaan mag worden indien de leeftijd van een gebruiker hoger is dan 18 EN hij heeft een identiteitskaart bij. We kunnen dergelijke samengestelde expressies schrijven gebruik makend van de logische operators.
Laat deze tiental bladzijden uitleg je niet de indruk geven dat code schrijven met if-structuren een eenvoudige job is. Vergelijk het met van je pa leren hoe je met pijl en boog moet jagen, wat vlekkeloos gaat op een stilstaande schijf, tot je in het bos voor een mammoet staat die op je komt afgestormd. Da's andere kak hé?
Het is dan ook aangeraden om, zeker in het begin, om steeds een flowchart te tekenen van wat je juist wilt bereiken. Dit zal je helpen om je code op een juiste manier op te bouwen (denk maar aan nesting en het plaatsen van meerdere "if -else" structuren in of na elkaar). Bezint eer ge begint.
De locatie waar je een variabele aanmaakt bepaalt de scope van de variabele. Binnen deze scope zal een variabele gebruikt kunnen worden door andere code. Je kan de scope vergelijken als verschillende kamers in een gebouw. Variabelen die zij aangemaakt in een kamer zijn enkel in die kamer bruikbaar.
Eenvoudig gezegd zullen steeds de omliggende accolades de scope van de variabele bepalen. Indien je de variabele dus buiten die accolades nodig hebt dan heb je een probleem: de variabele is enkel bereikbaar binnen de accolades vanaf het punt in de code waarin het werd gedeclareerd.
Zeker wanneer je begint met if, loops, methoden, enz. zal de scope belangrijk zijn: deze code-constructies gebruiken steeds accolades om codeblocks aan te tonen. Een variabele die je dus binnen een if-blok aanmaakt zal enkel binnen dit blok bestaan, niet erbuiten.
Volgende voorbeeld toont bijvoorbeeld de scope van de variabele getal:
if( iLoveCSharp == true)
{
Console.WriteLine("Hoeveel punten op 10 geef je C#?"):
int getal ; //Start scope getal
getal = int.Parse(Console.ReadLine());
} // einde scope getal
Console.WriteLine(getal); // FOUT! getal niet in deze scope
De variabele getal wordt aangemaakt tussen de accolades van de if en "verdwijnt" dus van zodra we die kamer verlaten (laatste accolade).
Wil je dus getal ook nog buiten de if gebruiken zal je je code moeten herschrijven zodat getal VOOR de if wordt aangemaakt. Nu is de scope van variabele groter: daar we steeds naar de omliggende accolades moeten kijken. In dit geval bepalen dus de accolades op lijn 1 en 9 de scope:
{
int getal = 0 ; //Start scope getal
if( iLoveCSharp == true)
{
Console.WriteLine("Hoeveel punten op 10 geef je C#?"):
getal = int.Parse(Console.ReadLine());
}
Console.WriteLine(getal);
} // einde scope getal
De buitenste accolades zetten we er even om de scope te benadrukken (maar hoeven dus niet).
Merk op dat indien je aan nesting doet, de scope doorheen de inner geneste codeblocken doorloopt en pas eindigt bij de accolade van het block waarbinnen de variabele werd gedeclareerd.
Zolang je in de scope van een variabele bent, kan je geen nieuwe variabele met dezelfde naam aanmaken:
Volgende code is dus niet toegestaan:
int getal = 0;
{
int getal = 5; //Deze lijn is niet toegestaan
}
Je krijgt de foutboodschap: "A local variable named 'getal' cannot be declared in this scope because it would give a different meaning to 'getal', which is already used in a 'parent or current' scope to denote something else."
Enkel de tweede variabele een andere naam geven is toegestaan in het voorgaande geval.
In volgende voorbeeld is dit dus wel geldig, daar de scope van de eerste variabele afgesloten wordt door de accolades:
{
int getal = 0 ;
//....
}
//Verder in code
{
int getal = 5;
}
Een switch statement is een element om een veelvoorkomende constructie van if/if else...else eenvoudiger te schrijven. Vaak komt het voor dat we bijvoorbeeld aan de gebruiker vragen om een keuze te maken (bijvoorbeeld een getal van 1 tot 10, waarbij ieder getal een ander menu-item uitvoert van het programma), zoals:
Console.WriteLine("Kies: 1)afbreken\n2)opslaan\n3)laden:");
int option = int.Parse(Console.ReadLine());
if (option == 1)
Console.WriteLine("Afbreken gekozen");
else if (option == 2)
Console.WriteLine("Opslaan gekozen");
else if (option == 3)
Console.WriteLine("Laden gekozen");
else
Console.WriteLine("Onbekende keuze");
Met een switch kan dit eenvoudiger wat ik zo meteen demonstreer. Eerst bekijken we hoe switch juist werkt. De syntax van een switch is specialer dan de andere programma flow-elementen (if, while, enz.), namelijk als volgt:
switch (value)
{
case constant:
statements
break;
case constant:
statements
break;
default:
statements
break;
}
Laten we eens kijken welke nieuwe zaken we hier terugvinden1:
value is de testvariabele die wordt gebruikt als test in de switch (option in het voorbeeld).
Iedere mogelijke waarde van value begint met het case keyword. Gevolgd door de waarde (de case constant) die value moet hebben om in deze case te springen.
Na het dubbelpunt volgt vervolgens de code die moet uitgevoerd worden in deze case. Deze code mag bestaan uit meerdere lijnen code. Accolades zijn hier trouwens niet verplicht.
Iedere case moet afgesloten worden met het break keyword.
Tijdens de uitvoer zal de switch de inhoud van de testvariabele (value) vergelijken met iedere case constant. Dit gebeurt van boven naar beneden. Wanneer een gelijkheid wordt gevonden dan wordt die case uitgevoerd.
Indien geen case wordt gevonden die gelijk is aan value dan zal de code binnen de default-case uitgevoerd worden (de else achteraan indien alle vorige if else-tests negatief waren).
We zijn dus 4 gereserveerde keywords rijker:
switch
case
break
default
Het menu van zonet kunnen we nu herschrijven naar een switch:
Console.WriteLine("Kies: 1)afbreken\n2)opslaan\n3)laden:");
int option = int.Parse(Console.ReadLine());
switch (option)
{
case 1:
Console.WriteLine("Afbreken gekozen");
break;
case 2:
Console.WriteLine("Opslaan gekozen");
break;
case 3:
Console.WriteLine("Laden gekozen");
break;
default:
Console.WriteLine("Onbekende keuze");
break;
}
De case waarden moeten constanten zijn en mogen dus geen variabelen zijn. Constanten zijn de welgekende literals (1, "1", 1.0, 1.d, '1', enz.). Uiteraard moeten de case waarden van hetzelfde datatype zijn als die van de testwaarde.
1
Sinds C# 7 is de switch met enkele krachtige uitbreidingen vergroot. Ik heb bewust gekozen om deze niét in dit boek op te nemen omdat ze anders je eerste contact met switch nodeloos moeilijker maakt dan zou moeten.
Toch nieuwsgierig wat de nieuwe switch kan? Lees dan zeker eens thomasclaudiushuber.com/2021/02/25/c-9-0-pattern-matching-in-switch-expressions voor een mooi overzicht van alle nieuwigheden.
Helm op alsjeblieft! enum is een erg onderschat concept bij beginnende programmeurs. Enums zijn wat raar in het begin, maar van zodra je er mee weg bent zal je niet meer zonder kunnen en zal je code zoveel eleganter en stoerder worden. Zet je helm dus op en begin er aan!
Stel dat je een programma moet schrijven dat afhankelijk van de dag van de week iets anders moet doen. In een wereld zonder enums (enumeraties, letterlijk opsommingen) zou je dit kunnen schrijven op 2 zeer foutgevoelige manieren:
Met een int die een getal van 1 tot en met 7 kan bevatten.
Met een string die de naam van de dag bevat (bv. "woensdag")
Laten we tweede manier eens bekijken: de waarde van de dag bewaren we in een variabele string dagKeuze. We bewaren de dagen als "maandag", "dinsdag", enz.
if(dagKeuze == "maandag")
{
Console.WriteLine("We doen de maandag dingen");
}
else if (dagKeuze == "dinsdag")
{
Console.WriteLine("We doen de dinsdag dingen");
}
else if //enz.
De code wordt nu wel leesbaarder, maar toch is ook hier 1 groot nadeel:
De code is veel foutgevoeliger voor typefouten. Wanneer je "Maandag" i.p.v. "maandag" bewaart dan zal de if al niet werken. Iedere schrijffout of variant zal falen.
Enumeraties (enum) zijn een C# syntax dat bovenstaand probleem oplost en het beste van beide slechte oplossingen samenvoegt :
Leesbaardere code.
Minder foutgevoelige code, en dus minder potentiële bugs.
VS kan je helpen met sneller de nodige code te schrijven.
Het keyword enum geeft aan dat we een nieuw datatype maken dat maar enkele mogelijke waarden kan hebben. Nadat we dit nieuwe datatype hebben gedefinieerd kunnen we variabelen van dit nieuwe datatype aanmaken. Deze variabelen mogen enkel waarden bevatten die in het datatype werden gedefinieerd. Ook zal IntelliSense van Visual Studio je de mogelijke waarden helpen invullen.
In C# zitten al veel enum-types ingebouwd. Denk maar aan ConsoleColor: wanneer je de kleur van het lettertype van de console wilt veranderen gebruiken we een enum-type. Er werd reeds gedefinieerd wat de toegelaten waarden zijn, bijvoorbeeld: Console.ForegroundColor = ConsoleColor.Red;
Net zoals int, double enz. kan je nu ook variabelen van het type Weekdagen aanmaken. Hoe cool is dat!?
Bijvoorbeeld:
Weekdagen dagKeuze;
Weekdagen andereKeuze;
En vervolgens kunnen we waarden aan deze variabelen toewijzen als volgt:
dagKeuze = Weekdagen.Donderdag;
Kortom: we hebben variabelen zoals we gewoon zijn, het enige verschil is dat we nu beperkt zijn in de waarden die we kunnen toewijzen. Deze kunnen enkel de waarden krijgen die in het type gedefinieerd werden. De code is nu ook een pak leesbaarder geworden.
switch(dagKeuze)
{
case Weekdagen.Maandag:
Console.WriteLine("It's monday!");
break;
case Weekdagen.Dinsdag:
//enz.
}
Visual Studio houdt van enums (ik ook trouwens) en zal je helpen bij het schrijven van een switch indien de test-variabele een enum-type bevat.
Hoe?
Schrijf switch en druk op 2 maal op tab. Normaal verschijnt er nu een "prefab" switch structuur met een test-waarde genaamd switch_on die een gele achtergrond heeft.
Overschrijf switch_on met de variabele die je wilt testen (bv. dagKeuze).
Klik nu met de muis eender waar binnen de accolades van de switch.
De waarde van een enum-variabelen wordt intern als een int bewaard. In het geval van de Weekdagen zal maandag standaard de waarde 0 krijgen, dinsdag 1, enz.
Volgende conversies met behulp van casting zijn dan ook perfect toegelaten:
int keuze = 3;
Weekdagen dagKeuze = (Weekdagen)keuze;
//dagKeuze zal de waarde Weekdagen.Donderdag hebben
Wil je dus bijvoorbeeld 1 dag bijtellen dan kan je schrijven:
Weekdagen dagKeuze= Weekdagen.Dinsdag;
int extradag= (int)dagKeuze + 1;
Weekdagen nieuweDag= (Weekdagen)extradag;
//extraDag heeft de waarde Weekdagen.Woensdag
Let er wel op dat je geen extra dag op Zondag probeert bij te tellen. Dat zal niet werken.
Standaard worden de enum waarden intern dus genummerd beginnende bij 0. Je kan dit ook manueel veranderen door bij het maken van de enum expliciet aan te geven wat de interne waarde moet zijn, als volgt:
Heel vaak zal je een programma schrijven waarbij de gebruiker een keuze moet maken uit een menu of iets dergelijks. Dit menu kan je voorstellen met een enum. Het probleem is vervolgens vragen wat de keuze van de gebruiker is en deze dan verwerken. Je zou dit kunnen doen met behulp van een reeks if-testen (if(userinput=="demo") )...Maar waarom niet de kracht van enum benutten?!
Volgende code toont hoe je dit kunt doen:
enum Menu {Demo=1, Start, Einde}
static void Main(string[] args)
{
Console.WriteLine("Wat wil je doen?");
Console.WriteLine("1. Demo");
Console.WriteLine("2. Start");
Console.WriteLine("3. Einde");
int userkeuze = int.Parse(Console.ReadLine());
Menu keuze = (Menu)userkeuze;
switch (keuze)
{
//...
Sinds .NET 5 uitkwam, is er een meer gebruiksvriendelijke manier verschenen om een string te parsen naar een enum variabele. Hierbij wordt gebruikt gemaakt van generics (herkenbaar aan < >), een concept dat uit de doeken wordt gedaan in de appendix van dit boek.
Echter, zelfs zonder generics te kennen zou volgende code toch begrijpbaar moeten zijn. We gebruiken terug het eerder gedefinieerde Menu type en de nieuw beschikbare Enum.Parse< >- methode :
Menu keuze = Enum.Parse<Menu>(Console.ReadLine());
We plaatsen tussen de < > het enum datatype naar waar we willen parsen.
Optioneel kan je via een tweede argument van het type bool aangeven of de parsing hoofdlettergevoelig is (false) of niet (true) :
Menu keuze = Enum.Parse<Menu>(Console.ReadLine(), true);
Ah, de tijden zonder enum. Ik weet nog hoe we onze grotten beschilderden zonder ons druk te moeten maken in enumeraties. Om maar te zeggen: je kan perfect leven zonder enum. Vele programmeurs voor je hebben dit bewezen. Echter, van zodra ze enum ontdekten (en begrepen) zijn nog maar weinig programmeurs er terug van afgestapt.
De eerste kennismaking met enumeraties is wat bevreemdend: je kan plots je eigen datatypes aanmaken?! Van zodra je ze in de vingers hebt zal je ontdekken dat je veel leesbaardere code kunt schrijven én dat Visual Studio je kan helpen met het opsporen van bugs.
Wanneer gebruik je enum? Telkens je één of meer variabelen nodig hebt, waarvan je perfect op voorhand weet welke mogelijke waarden ze mogen hebben. Ze worden bijvoorbeeld vaak gebruikt in finite state machines.
Bij game development willen we bijhouden in welke staat het programma zich bevindt: Intro, Startmenu, Ingame, Gameover, Optionsscreen, enz. Dit is een typisch enum verhaal. We definiëren hiervoor het volgende type:
En vervolgens kunnen we dan met een eenvoudige switch in ons hoofdprogramma snel de relevante code uitvoeren:
//Bij opstart:
gamestate playerGameState= gamestate.Intro;
// ...
//later
switch(playerGameState)
{
case gamestate.Intro:
//show fancy movie
break;
case gamestate.Startmenu:
//show start menu
break;
//enz.
Een ander typisch voorbeeld is schaken. We maken een enum om de speelstukken voor te stellen (Pion, Koning, Toren enz.) en kunnen hen dan laten bewegen en vechten in uiterst leesbare code:
In het vorige hoofdstuk hebben we geleerd hoe we onze code konden vertakken (branching) door beslissingen te nemen. Dit stelde ons in staat om verschillende stukken code uit te voeren, afhankelijk van de waarde van bepaalde variabelen of de invoer van de gebruiker.
Wat we nog niet konden was terug naar een vorige plek in het algoritme gaan. Soms willen we dat een heel stuk code 2 of meerdere keren moet uitgevoerd worden tot aan een bepaalde conditie wordt voldaan: "Voer volgende code uit tot dat de gebruiker 666 invoert."
Herhalingen (loops) creëer je wanneer bepaalde code een aantal keer moet herhaald worden. Hoe vaak de herhaling moet duren is afhankelijk van de conditie die je hebt bepaald. Elke keer dat de code binnen de loop wordt uitgevoerd, noemen we dit een iteratie. Dit betekent dat de loop bij elke iteratie zijn codeblok opnieuw doorloopt, totdat de gestelde conditie niet meer voldoet.
Door herhalende code met loops te schrijven maken we onze code korter en bijgevolg ook minder foutgevoelig en beter onderhoudbaar.
Definite of counted loop: een loop waarbij het aantal herhalingen vooraf bekend is. Bijvoorbeeld: alle getallen van 0 tot en met 100 tonen.
Indefinite of sentinel loop: een loop waarvan op voorhand niet kan gezegd worden hoe vaak deze zal uitgevoerd worden. Invoer van de gebruiker of een interne test bepaalt wanneer de loop stopt. Bijvoorbeeld: "Voer getallen in, voer -1 in om te stoppen" of "Bereken de grootste gemene deler".
Oneindige loop: een loop die nooit stopt. Soms gewenst (bv. de game loop) of, vaker, een bug.
Er zijn 3 standaard manieren om loops te maken in C#:
while: zal 0 of meerdere keren uitgevoerd worden.
do while: zal minimaal 1 keer uitgevoerd worden.
for: een alternatieve, iets compactere manier om loops te beschrijven wanneer je exact weet hoe vaak de loop zal moeten herhalen.
Daarnaast zullen we in hoofdstuk 9 een speciale loopvariant leren kennen wanneer we arrays en objecten bespreken:
foreach: een leesbaardere manier van loopen, die vooral nuttig is wanneer je met objecten werkt.
De 3 categorieën loops die we net bespraken kunnen in principe met eender welk looptype in C# geschreven worden. Toch raad ik je aan om vanaf nu steeds wel doordacht na te denken welk looptype het best bij je probleem past. Samengevat kan je het volgende zeggen:
Looptype
Definite loop
Indefinite loop
Oneindige loop
While en do while
x
x
x
For
x
Foreach
x
Deze tabel suggereert dat we met while en do while meer kunnen, wat ook zo is. Je zal echter gauw ontdekken dat je vaak terugvalt op code met een for omdat:
Deze compactere code oplevert.
Veel problemen met een definite loop kunnen opgelost worden.
while (conditie)
{
// code zal uitgevoerd worden zolang de conditie waar is
}
Net als bij een if-statement wordt de conditie hier uitgedrukt als een booleaanse expressie met één of meerdere relationele operatoren. Zolang de conditie true is zal de code binnen de accolades uitgevoerd worden. Indien de conditie reeds vanaf het begin false is dan zal de code binnen de loop nooit worden uitgevoerd.
Telkens wanneer het programma aan het einde van het while codeblock komt springt het terug naar de conditie bovenaan en zal de test wederom uitgevoerd worden. Is deze weer true dan wordt de code weer uitgevoerd. Van zodra de test false is zal de code voorbij het codeblock springen en na het while codeblok doorgaan. De flowchart is duidelijk:
Een voorbeeld van een eenvoudige while loop:
int tellertje = 0;
while (tellertje < 100)
{
tellertje++;
Console.WriteLine(tellertje);
}
Zolang tellertje kleiner is dan 100 (tellertje < 100) zal het met 1 verhoogd worden en op het scherm worden getoond. We krijgen met dit programma dus alle getallen van 1 tot en met 100 op het scherm onder elkaar te zien. Daar de test gebeurt aan het begin van de loop wil dit zeggen dat het getal 100 nog wel getoond zal worden. Begrijp je waarom? Test dit zelf!
Zodra je dezelfde lijn(en) code meerdere keren onder elkaar ziet staan, is de kans groot dat je dit korter kunt schrijven met behulp van loops (of methoden, wat we in het volgende hoofdstuk zullen bespreken).
Code onder elkaar kopiëren en plakken is dus vaak een duidelijke indicator dat je loops kan gebruiken.
Indien de loop-conditie nooit false wordt dan heb je een oneindige loop gemaakt. Soms is dit gewenst gedrag. Maar vaker is dit een bug en zal je dit moeten debuggen.
Volgende twee voorbeelden tonen dit:
Een bewust oneindige loop:
while(true)
{
//"To infinity and beyond!"
}
Een bug die een oneindige loop veroorzaakt:
int teller = 0;
while(teller<10)
{
Console.WriteLine(teller);
teller--; //oeps, dit had teller++ moeten zijn
}
Zorg er altijd voor dat de variabele(n) die je in je testconditie gebruikt, ook effectief in de loop worden aangepast. Als deze in de loop niet verandert dan zal ook de test-conditie dezelfde blijven en heb je dus een oneindige loop gemaakt.
Let er op dat de scope van variabelen bij loops zeer belangrijk is. Indien je een variabele binnen de loop definieert dan zal deze steeds terug "gereset" worden wanneer de volgende iteratie van de loop start.
Volgende code toont bijvoorbeeld foutief hoe je de som van de eerste 10 getallen (1+2+3+...+10) zou maken:
int teller = 1;
while(teller <= 10)
{
int som = 0;
som = som+teller;
teller++;
}
Console.WriteLine(som); //deze lijn zal een fout genereren
Voorgaande code zal volgende VS foutboodcshap geven: The name 'som' does not exist in the current context.
De correcte manier om dit op te lossen is te beseffen dat de variabele som enkel binnen de accolades van de while-loop gekend is. Op de koop toe wordt deze steeds terug op 0 gezet en er kan dus geen som van alle teller-waarden bijgehouden worden. Hier de oplossing:
int teller = 1;
int som = 0;
while(teller <= 10)
{
som = som+teller;
teller++;
}
Console.WriteLine(som);
In tegenstelling tot een while loop, zal een do while loop sowieso minstens 1 keer uitgevoerd worden. De reden is eenvoudig: de stopconditie gecontroleerd wordt na iedere iteratie getest. Bij een while gebeurt dit voor dat er een nieuwe iteratie wordt gestart.
Vergelijk volgende flowchart van de do while met die van de while:
De syntax van een do while is eveneens eenvoudig:
do{
//code zal uitgevoerd worden zolang de conditie waar is
} while (conditie);
Merk op dat achteraan de testconditie een puntkomma na het ronde haakje staat. Deze vergeten is een véél voorkomende fout. Bij een while is dit niet!
Het volgende eenvoudige aftelprogramma toont de werking van de do while loop:
int i = 10;
do
{
i--;
Console.WriteLine(i);
} while (i > 0);
Begrijp je wat dit programma zal doen? Inderdaad, dit zal alle getallen van 9 tot en met 0 onder elkaar op het scherm zetten.
Dankzij loops kunnen we nu ook eenvoudiger omgaan met foutieve input van de gebruiker. Stel dat we volgende vraag hebben gesteld aan de gebruiker:
Console.WriteLine("Geef uw keuze in: a, b of c");
string input = Console.ReadLine();
Met een loop kunnen we nu deze vragen blijven stellen tot de gebruiker een geldige input (a,b of c) geeft:
string input;
do
{
Console.WriteLine("Geef uw keuze in: a, b of c");
input = Console.ReadLine();
}while(input != "a" && input != "b" && input != "c");
Zolang (while) de gebruiker niet "a", "b" of "c" invoert zal de loop zichzelf blijven herhalen.
Merk op dat we de variabele string inputvoor de do while moeten aanmaken. Zouden we die in de loop pas aanmaken dan zou de variabele niet als test kunnen gebruikt worden aan het einde van de loop. De reden? Wederom de scope van variabelen. De accolades van de do while creëren een duidelijke scope die iedere iteratie verdwijnt en terug wordt aangemaakt, inclusief dus variabelen die binnen deze accolades worden aangemaakt.
Ik herhaal voorgaande nog eens nadrukkelijk omdat hier vaak fouten op gemaakt worden: je ziet dat de test achteraan (while(input...);) buiten de accolades van de loop ligt en dus een andere scope heeft.
De booleaanse expressie input != "a" && input != "b" && input != "c" kan ook anders geschreven met dezelfde interne logica (en dus werking) als:
!(input == "a" || input == "b" || input == "c")
Sommige mensen prefereren deze tweede vorm. Maar dat is persoonlijke smaak.
Voorgaande logica is een gevolg van de Wetten van De Morgan (ook wel dualiteit van De Morgan genoemd) die het verband leggen tussen de logische operatoren EN, OF en de negatie.
Deze wetten zeggen dat (uitgedrukt even in C# voor de duidelijkheid):
!(A && B ) is hetzelfde als !A || !B.
!(A || B ) is hetzelfde als !A && !B .
Zie je hoe ik de tweede wet gebruikt heb in het voorgaande voorbeeld om de alternatieve logica te vinden?
Een veelvoorkomende manier van while-loops gebruiken is waarbij je een bepaalde teller bijhoudt die je telkens met een bepaalde waarde verhoogt. Wanneer de teller een bepaalde waarde bereikt moet de loop afgesloten worden.
Bijvoorbeeld volgende code om alle even getallen van 0 tot 10 te tonen:
int i = 0;
while(i<11)
{
Console.WriteLine(i);
i = i + 2;
}
Met een for-loop kunnen we deze veel voorkomende code-constructie verkort schrijven.
for (setup; finish test; update)
{
//code die zal uitgevoerd worden zolang de finish test true geeft
}
setup: Hier zetten we de "wachter-variabele" op de beginwaarde. De wachter-variabele is de variabele die we tijdens de loop in het oog zullen houden en die zal bepalen hoe vaak de loop moet uitgevoerd worden (bv. int i = 0;).
finish test: Hier plaatsen we een booleaanse expressie die de wachter-variabele gebruikt om te testen of een volgende iteratie moet worden uitgevoerd (bv. i<11).
update: Hier plaatsen we wat er moet gebeuren na iedere iteratie. Meestal zullen we hier de wachter-variabele verhogen of verlagen (bv. i = i + 2).
Voor de setup-variabele kiest men meestal i, maar dat is niet noodzakelijk.
Gebruiken we deze kennis, dan kunnen we de eerder vermelde code om de even getallen van 0 tot en met 10 tonen als volgt:
for (int i = 0; i < 11; i += 2)
{
Console.WriteLine(i);
}
Deze code zal telkens i met 2 verhogen(update), startende bij 0 (setup). Het blijft dit doorlopen zolang i kleiner is dan 11 (finish test). Als output krijgen we:
0
2
4
6
8
10
for-tab-tab
Als je in Visual Studio for typt en dan tweemaal op [tab] duwt krijg je een kant en klare for-loop:
Telkens je vervolgens op [tab] duwt verspringt je cursor tussen i en length. Op die manier kan je dus snel een for schrijven.
Het continue keyword laat toe om in een loop de huidige iteratie te eindigen en weer naar de start van de volgende iteratie te gaan. In het volgende voorbeeld gebruiken we continue om alle getallen van 1 tot 10 te tonen waarbij we het getal 5 zullen overslaan:
for (int i = 1; i <= 10; i++)
{
if (i == 5)
{
continue;
}
Console.WriteLine(i);
}
Met break kan je loops altijd vroegtijdig stopzetten. Je springt dan als het ware ogenblikkelijk uit de loop. Je ziet het aankomen zeker? Yups, daar is ie....
Olla!? Wat denken we dat we aan het doen zijn? Gelieve die keywords ogenblikkelijk terug uit je code te verwijderen. Bedankt.
break en continue zijn de subtielere vrienden van goto. Ze werken net als goto in de schemerzone tussen wat wenselijk is en wat niet. Dit maakt ze extra gevaarlijk. Voordat je break als oplossing gebruikt, probeer eerst of je de loop netjes kunt afsluiten door bijvoorbeeld de juiste booleaanse expressie in de testconditie te gebruiken. Hetzelfde geldt voor continue, dat ook snel goto-achtige bugs kan veroorzaken.
Ik heb gemerkt dat beginnende C#-programmeurs vaak te lui zijn om een deftige stopconditie voor hun loop te schrijven. En dan maar break als oplossing hanteren.
Wanneer we 1 of meerdere loops in een andere loop plaatsen dan spreken we over geneste loops.
Geneste loops komen vaak voor, maar zijn wel een ander paar mouwen wanneer je deze zaken wilt debuggen en correct schrijven.
We spreken steeds over de outer loop als de omhullende of "grootste" loop. Waarbij de binnenste loop de inner loop is.
Volgende code toont bijvoorbeeld 2 loops die genest werden:
Om te tellen hoe vaak de inner code zal uitgevoerd worden dien je te weten hoe vaak iedere loop afzonderlijk wordt uitgevoerd. Vervolgens vermenigvuldig je al deze getallen met elkaar.
Een voorbeeld: Hoe vaak zal het woord "Hallo" op het scherm verschijnen bij volgende code?
for (int i = 0; i < 10; i++)
{
for (int j = 0; j < 5; j++)
{
Console.WriteLine("Hallo");
}
}
De outer loop wordt 10 keer uitgevoerd (waarbij i de waarden 0 tot en met 9 aanneemt). De inner loop wordt bij elke iteratie van de outer loop 5 keer uitgevoerd (waarbij j de waarden 0 tot en met 4 aanneemt). In totaal zal dus 50 keer "Hallo" op het scherm verschijnen (5x10).
Let er op dat break je enkel uit de huidige loop zal halen. Indien je dit dus gebruikt in de inner loop dan zal de outer loop nog steeds voortgaan. Nog een reden om zéér voorzichtig om te gaan met break. Of beter nog: gewoon niet gebruiken!
"I will always choose a lazy person to do a difficult job. Because, he will find an easy way to do it."
Bill Gates, oprichter van Microsoft.
Het is je misschien nog niet opgevallen, maar sinds het vorige hoofdstuk zijn we de jacht begonnen op zo weinig mogelijk code te schrijven met zoveel mogelijk rendement. Loops waren een eerste stap in de goede richting. De volgende zijn methoden! Tijd om nog luier te worden.
Veel code die we hebben geschreven wordt meerdere keren, al dan niet op verschillende plaatsen, gebruikt. Dit verhoogt natuurlijk de foutgevoeligheid. Door het gebruik van methoden kunnen we de foutgevoeligheid van de code verlagen omdat de code maar op 1 plek staat én maar 1 keer dient geschreven te worden. Echter, ook de leesbaarheid en dus onderhoudbaarheid van de code wordt verhoogd.
Beeld je eens dat we geen gebruik konden maken van de vele .NET bibliotheken. Stel je voor dat Console.WriteLine niet bestond? Telkens als we dan iets in C# naar het scherm wilden sturen moesten we de volledige interne code van WriteLine uitschrijven. Voor de geïnteresseerden, dat zou er (ongeveer) als volgt uitzien:
fixed (byte* p = bytes)
{
if (useFileAPIs)
{
int numBytesWritten;
Interop.Kernel32.WriteFile(hFile, p, bytes.Length, out numBytesWritten, IntPtr.Zero));
}
else
{
//enz.
Dat is aardig wat bizarre code he? En ik toon maar een stuk. Kortom: we mogen blij zijn dat methoden bestaan. Tijd om ze eens van dichterbij te bekijken!
Trouwens. Het is heel normaal dat voorgaande code je zenuwachtig maakt. Negeer ze maar1
Een methode (ook wel functie genoemd) is in C# een blok code dat specifieke taken uitvoert. Een methode bestaat uit één of meerdere statements, kan herhaaldelijk worden aangeroepen met of zonder extra parameters, en kan een resultaat teruggeven. Methoden kunnen vanuit elk deel van je code worden aangeroepen.
Je gebruikt al sinds les 1 methoden. Telkens je Console.WriteLine() gebruikt, roep je een methode aan (genaamd WriteLine).
Methoden in C# zijn herkenbaar aan de ronde haakjes achteraan, al dan niet met actuele parameters tussen. Alles wat je nu gaat zien heb je al gebruikt. Het grote verschil zal zijn dat we nu ook zelf methoden gaan definiëren, en niet enkel bestaande methoden gebruiken.
Methoden hebben als voordeel dat je herbruikbare stukken code kunt gebruiken en dus niet steeds deze code overal moet kopiëren en plakken. Daarnaast zullen methoden je code ook overzichtelijker maken.
De basis-syntax van een methode ziet er als volgt uit (de werking van het keyword static leg ik uit in hoofdstuk 11):
static returntype MethodeNaam(optioneel_parameters)
{
//code van methode
}
De eerste lijn noemen we de methode-signatuur. Deze lijn verteld alles dat je moet weten om met de methode te werken (returntype, naam en eventuele parameters).
Vervolgens kan je deze methode elders oproepen als volgt, indien de methode geen parameters vereist:
MethodeNaam();
Dat is een mondvol. We gaan daarom de methoden even stapsgewijs leren kennen. Let's go!
Beeld je in dat je een applicatie moet maken waarin je op verschillende plaatsen de naam van je programma moet tonen. Zonder methoden zou je telkens moeten schrijven Console.WriteLine("Timsoft XP");
Als je later de naam van het programma wilt veranderen naar iets anders (bv. Timsoft 11) dan zal je manueel overal de titel moeten veranderen in je code. Met een methode hebben we dat probleem niet meer. We schrijven daarom een methode ToonTitel als volgt:
Zoals je misschien al begint te vermoeden is dus de Main waar we steeds onze code schrijven ook een methode. Een console-applicatie heeft een startpunt nodig en daarom begint ieder programma in deze methode, maar in principe kan je even goed je programma op een andere plek laten starten.
string[] args is een verhaal apart en zullen we in het volgende hoofdstuk bekijken. Ik verklap alvast dat je via deze args opstartparameters aan je programma kan meegeven tijdens het opstarten (bijvoorbeeld explorer.exe google.com) zodat je code hier iets mee kan doen.
Voorgaande methode gaf niets terug. Dat kon je zien aan het keyword void (letterlijk: leegte).
Vaak willen we echter wel dat de methode iets teruggeeft. Bijvoorbeeld het resultaat van een berekening.
Het returntype van een methode geeft aan wat het type is van de data die de methode als resultaat teruggeeft bij het beëindigen ervan. Eender welk datatype kan hiervoor gebruikt worden (int, string, char, float, enz.). Ook enum datatypes kunnen als returntype in methoden gebruikt worden (en later ook objecten, wat we in hoofdstuk 10 zullen ontdekken).
Het is belangrijk dat in je methode het resultaat ook effectief wordt teruggegeven, dit doe je met het keyword return gevolgd door de variabele die moet teruggeven worden.
Denk er dus aan dat deze variabele van het type is dat je hebt opgegeven als zijnde het returntype. Van zodra je return gebruikt zal je op die plek uit de methode 'vliegen'.
Wanneer je een methode maakt die iets teruggeeft (dus een ander returntype dan void) is het ook de bedoeling dat je het resultaat van die methode opvangt en gebruikt. Je kan bijvoorbeeld het resultaat van de methode in een variabele bewaren. Dit vereist dat die variabele dan van hetzelfde returntype is!
Volgend voorbeeld bestaat uit een methode die de naam van de auteur van je programma teruggeeft:
Een mogelijke manier om deze methode in je programma te gebruiken zou nu kunnen zijn:
string myName = VerkrijgAuteurNaam();
Maar ook dit zal werken:
Console.WriteLine(VerkrijgAuteurNaam());
Of verderop misschien als volgt:
Console.WriteLine($"Auteur van dit boek: {VerkrijgAuteurNaam()}");
Je mag zowel literals als variabelen en zelfs andere methode-aanroepen plaatsen achter het return keyword. Zolang het maar om een expressie gaat die een resultaat heeft kan dit. Voorgaande methode kunnen we dus ook schrijven als:
De faculteit van een getal n schrijven we als n!. Het is het product van alle positieve getallen van 1 tot en met n, waarbij 0! gelijk is aan 1. Hier een voorbeeld van een methode die de faculteit van 5 berekent, 5!. We willen dus 1*2*3*4*5 berekenen, wat 120 is. De oproep van de methode gebeurt vanuit de Main-methode:
internal class Program
{
static int FaculteitVan5()
{
int resultaat = 1;
for (int i = 1; i <= 5; i++)
{
resultaat *= i;
}
return resultaat;
}
static void Main(string[] args)
{
Console.WriteLine($"Faculteit van 5 is {FaculteitVan5()}");
}
}
Indien je methode niets teruggeeft wanneer de methode eindigt (bijvoorbeeld indien de methode enkel tekst op het scherm toont) dan dien je dit ook aan te geven. Hiervoor gebruik je het keyword void.
Een voorbeeld:
static void ToonVersie()
{
Console.WriteLine("Dit is versie 8.31 ");
}
Deze methode moet je dus als volgt aanroepen:
ToonVersie();
Volgende 2 manieren werken niet bij een methode met void als returntype:
string result = ToonVersie(); //MAG NIET!!
Console.WriteLine(ToonVersie()); // MAG NIET!
Je mag het return keyword eender waar in je methode gebruiken. Weet wel dat van zodra een statement met return wordt bereikt de methode ogenblikkelijk afsluit en het resultaat achter return teruggeeft.
Soms is dit handig zoals in volgende voorbeeld:
static string WindRichting()
{
Random r = new Random();
switch (r.Next(0,4))
{
case 0:
return "noord";
break;
case 1:
return "oost";
break;
case 2:
return "zuid";
break;
case 3:
return "west";
break;
}
return "onbekend";
}
Merk op dat de onderste lijn (19) nooit zal bereikt worden. Toch vereist C# dit!
Dacht je nu echt dat ik weg was?! Het is me opgevallen dat je niet altijd de foutboodschappen in VS leest. Ik blijf alvast uit jouw buurt als je zo doorgaat. Doe jezelf (en mij) dus een plezier en probeer die foutboodschappen in de toekomst te begrijpen. Er zijn er maar een handvol en bijna altijd komen ze op hetzelfde neer. Neem nou de volgende:Not all code paths return a value
Die ga je nog vaak tegenkomen!
Bovenstaande foutboodschap zal je vaak krijgen en geeft altijd aan dat er bepaalde delen binnen je methode zijn waar je kan komen zonder dat er een return optreedt. Het einde van de methode wordt met andere woorden bereikt zonder dat er iets uit de methoden terug komt (wat enkel bij void mag).
Foutboodschappen hebben de neiging om gecompliceerder te klinken dan de effectieve fout die ze beschrijven. Een beetje zoals een lector die lesgeeft over iets waar hij zelf niets van begrijpt.
Methoden zijn handig vanwege de herbruikbaarheid. Wanneer je een methode hebt geschreven om de sinus van een hoek te berekenen, dan is het echter ook handig dat je de hoek als parameter kunt meegeven zodat de methode kan gebruikt worden voor eender welke hoekwaarde.
Indien er wel parameters nodig zijn dan geef je die mee als volgt:
MethodeNaam(parameter1, parameter2, …);
Je hebt dit ook al geregeld gebruikt. Wanneer je tekst op het scherm wilt tonen dan roep je de WriteLine methode aan en geef je 1 parameter mee, namelijk hetgeen dat op het scherm moet komen.
Om zelf een methode te definiëren die 1 of meerdere parameters aanvaardt, dien je per parameter het datatype en een tijdelijk naam (identifier) te definiëren (formele parameters) in de methode-signatuur
Als volgt:
static returntype MethodeNaam(type parameter1, type parameter2)
{
//code van methode
}
Deze formele parameters zijn nu beschikbaar binnen de methode om mee te werken naar believen.
Stel bijvoorbeeld dat we onze FaculteitVan5 willen veralgemenen naar een methode die voor alle getallen werkt, dan zou je volgende methode kunnen schrijven:
static int BerekenFaculteit(int grens)
{
int resultaat = 1;
for (int i = 1; i <= grens; i++)
{
resultaat *= i;
}
return resultaat;
}
De naam grens kies je zelf. Maar we geven hier dus aan dat de methode BerekenFaculteit enkel kan aangeroepen worden indien er 1 actuele parameter van het type int wordt meegegeven.
Aanroepen van de methode gebeurt dan als volgt:
int getal = 5;
int resultaat = BerekenFaculteit(getal);
Of sneller:
int resultaat = BerekenFaculteit(5);
Als we even later resultaat dan zouden gebruiken zal er de waarde 120 in zitten.
Parameters worden "by value" meegegeven (zie het hoofdstuk over Arrays hierna) wat wil zeggen dat een kopie van de waarde wordt meegegeven. Als je dus in de methode de waarde van de parameter aanpast, dan heeft dit géén invloed op de waarde van de originele parameter waar je de methode aanriep.
Je zou nu echter de waarde van getal kunnen aanpassen (door bijvoorbeeld aan de gebruiker te vragen welke faculteit moet berekend worden) en je code zal nog steeds werken.
Veel beginnende programmeurs zijn soms verward dat de naam van de parameter in de methode (bv. grens) niet dezelfde moet zijn als de naam van de variabele (of literal) die we bij de aanroep meegeven.
Het is echter logisch dat deze niet noodzakelijk gelijk moeten zijn: het enige dat er gebeurt is dat de methodeparameter de waarde krijgt die je meegeeft, ongeacht van waar de parameter komt.
En wat als je de faculteiten wenst te kennen van alle getallen tussen 1 en 10? Dan zou je schrijven:
for (int i = 1; i < 11; i++)
{
Console.WriteLine($"Faculteit van {i} is {BerekenFaculteit(i)}" );
}
Dit zal als resultaat geven:
Faculteit van 1 is 1
Faculteit van 2 is 2
Faculteit van 3 is 6
Faculteit van 4 is 24
Faculteit van 5 is 120
Faculteit van 6 is 720
Faculteit van 7 is 5040
Faculteit van 8 is 40320
Faculteit van 9 is 362880
Faculteit van 10 is 3628800
Merk op dat dankzij je methode, je véél code maar één keer moet schrijven, wat de kans op fouten verlaagt.
De volgorde waarin je je parameters meegeeft bij de aanroep van een methode is belangrijk. De eerste variabele wordt aan de eerste parameter toegekend, enz. Het volgende voorbeeld toont dit.
Deze 2 aanroepen zullen dus een andere output geven:
ToonDeling(3.5 , 2.1 );
ToonDeling(2.1 , 3.5 );
Zeker wanneer je met verschillende types als formele parameters werkt is de volgorde belangrijk. Het verschil met de vorige methode is hier wel dat VS jou zal helpen wanneer je volgorde niet klopt.
Stel dat we volgende methode hebben gemaakt:
static void ToonInfo(string name, int age)
{
Console.WriteLine($"{name} is {age} old");
}
Parameters kunnen op 2 manieren worden doorgegeven aan een methode:
By value : hierbij wordt een kopie gemaakt van de huidige waarde. Het is die kopie die wordt meegegeven.
by reference: het adres (pointer of reference) naar de actuele parameter wordt meegegeven. Aanpassingen aan de actuele parameter in de methode zal daardoor ook zichtbaar zijn binnen de scope van de originele variabele. Parameters by reference komen pas vanaf hoofdstuk 9 van pas2.
2
Het tweede punt mag je volledig negeren als je geen flauw benul had wat er net werd gezegd. Ik kom hier later in de volgende hoofdstukken nog uitgebreid op terug!
Het effect van manier 1 is hopelijk duidelijk: wanneer je in een methode de inhoud van een actuele parameter aanpast, dan heeft dat geen gevolg op de originele variabele die we meegaven bij de methode-aanroep!
Dit zien we in dit programma:
static void JaartjeOuder(int leeftijd)
{
leeftijd++;
Console.WriteLine($"Hoera. Je bent {leeftijd} jaar geworden.");
}
static void Main(string[] args)
{
int mijnLeeftijd = 40;
Console.WriteLine($"Je bent {mijnLeeftijd} jaar.");
JaartjeOuder(mijnLeeftijd);
Console.WriteLine($"Je bent {mijnLeeftijd} jaar.");
}
In de output zien we dat mijnLeeftijd niet werd aangepast in de methode:
Je bent 40 jaar.
Hoera. Je bent 41 jaar geworden.
Je bent 40 jaar.
In het begin ga je vooral vanuit je Main methoden aanroepen, maar dat is geen verplichting. Je kan ook vanuit methoden andere methoden aanroepen. Je kan zelfs vanuit die aangeroepen methode weer andere aanroepen, enz.
Volgende (nutteloze) programma'tje toont dit in actie:
Deze code heeft een methode die zichzelf aanroept, zonder dat deze ooit afsluit. Hierdoor komen we dus in een oneindige aanroep van de methode SchrijfNaam. Dit programma zal een leeg scherm tonen (daar er nooit aan de tweede lijn in de methode wordt geraakt) en dan crashen wanneer het werkgeheugen van de computer op is.
Sinds C# 7.0 kan je methoden definiëren binnenin een andere methode. Dit noemt men lokale functies (local functions). Alhoewel ze zeker hun nut hebben, is het in deze fase van C# leren geen goed idee om lokale functies te gebruiken.
Het is veel belangrijker dat je eerst goed leert methoden schrijven. Beginnende programmeurs schrijven soms per ongeluk een lokale functies. Dan ontdekken ze dat ze die methode nergens kunnen aanroepen. Lokale functies zijn alleen oproepbaar binnen de methode waarin ze zijn gedefinieerd.
Even ingrijpen en je wijzen op recursie zodat je code niet in je gezicht blijft ontploffen.
Recursie is een geavanceerd programmeerconcept wat niet in dit boek wordt besproken (enkel in hoofdstuk 18 gaan we recursie nog kort ontmoeten), maar laten we het hier kort toelichten. Recursieve methoden zijn methoden die zichzelf aanroepen maar wél op een gegeven moment stoppen wanneer dat moet gebeuren. Volgend voorbeeld is een recursieve methode om de som van alle getallen tussen start en stop te berekenen:
static int BerekenSomRecursief(int start, int stop)
{
int som = start;
if(start < stop)
{
start++;
return som += BerekenSomRecursief(start, stop);
}
return som;
}
Je herkent recursie aan het feit dat de methode zichzelf aanroept. Maar een controle voorkomt dat die aanroep blijft gebeuren zonder dat er ooit een methode wordt afgesloten. We krijgen 6 terug (1+2+3) als we de methode als volgt aanroepen:
Het is aan te raden om steeds boven een methode een nieuwe vorm van commentaar te plaatsen als volgt (dit werkt enkel bij methoden): ///
Visual Studio zal dan automatisch de parameters verwerken van je methode zodat je vervolgens enkel nog het doel van iedere parameter moet schrijven.
Stel dat we een methode hebben geschreven die de macht van een getal berekent (wat dom is...er bestaat al zoiets als Math.Pow). We zouden dan volgende commentaar toevoegen:
/// <summary>
/// Berekent de macht van een getal.
/// </summary>
/// <param name="grondtal">Het getal dat je tot macht wilt verheffen</param>
/// <param name="exponent">De exponent van de macht</param>
/// <returns></returns>
static int Macht(int grondtal, int exponent)
{
int result = grondtal;
for (int i = 1; i < exponent; i++)
{
result *= grondtal;
}
return result;
}
Wanneer we nu elders de methode Macht gebruiken dan krijgen we automatische extra informatie:
Laten we eens kijken naar de vele methoden die reeds ingebouwd zitten in .NET en hoe we ze nu beter kunnen gebruiken.
Sommige methoden vereisen dat je een aantal parameters meegeeft. De parameters dien je tussen de ronde haakjes te zetten. Hierbij weten we nu dat het uiterst belangrijk dat je de volgorde respecteert die de ontwikkelaar van de methode heeft gebruikt.
Maar wat als je niet weet in welke volgorde je arguementen moet meegeven? Intellisense is dan de oplossing! Typ de methode in je code en stop met typen na het eerste ronde haakje. Vervolgens zal Intellisense alle mogelijke manieren tonen waarop je deze methoden kan oproepen. Met de omhoog- en omlaagpijltjes van het toetsenbord kan je alle mogelijke manieren bekijken.
In de voorgaande screenshot zien we dat Intellisense telkens duidelijke de methode-signatuur beschrijft:
Het return type (in dit geval void).
Gevolgd door de naam van de methode.
Finaal de formele parameters en hun datatype(s).
Merk trouwens op dat je de WriteLine-methode ook mag aanroepen zonder parameters, dit zal resulteren in een lege lijn in de console.
Met behulp van de F1-toets kunnen we meer info over de methode in kwestie tonen. Hiervoor dien je je cursor op de Methode in je code te plaatsen, en vervolgens op F1 te drukken. Je komt dan op de online documentatie van de methode waar erg veel informatie terug te vinden is over het gebruik ervan. Scroll naar de overload list, daar zien we de verschillende manieren waarop je de methode in kwestie kan aanroepen (het concept overloaden bespreek ik in de volgende sectie). Je kan vervolgens op iedere methode klikken voor meer informatie en een codevoorbeeld.
Wat kan deze .NET bibliotheek eigenlijk? is een veelgestelde vraag. Zeker wanneer je de basis van C# onder de knie hebt en je stilletjes aan met bestaande .NET bibliotheken wilt gaan werken. Wat volgt is een essentieel onderdeel van VS dat veel gevloek en tandengeknars zal voorkomen.
De online documentatie van VS is zeer uitgebreid en dankzij IntelliSense krijg je ook aardig wat informatie tijdens het typen van de code zelf. IntelliSense is de achterliggende technologie in VS die ervoor zorgt dat je minder moet typen. Als een soort assistent probeert IntelliSense een beetje te voorspellen wat je gaat typen en zal je daarmee helpen.
Type eens het volgende in:
System.Console.
Wacht nu even en er zal na het punt (.) een lijst komen van methoden en fields die beschikbaar zijn. Dit is IntelliSense in actie. Als er niets verschijnt of iets dat je niet had verwacht, dan is de kans groot dat er je een schrijffout hebt gemaakt.
Je kan door deze lijst met de muis doorheen scrollen en zo zien welke methoden allemaal bij de Console bibliotheek horen. Indien gewenst kan je vervolgens de gewenste methode selecteren en op spatie duwen zodat deze in je code verschijnt.
Vaak moet je code schrijven waarin je een getal aan de gebruiker vraagt:
Console.WriteLine("Geef leeftijd");
int leeftijd = int.Parse(Console.ReadLine());
Als deze constructie op meerdere plekken in een project voorkomt dan is het nuttig om deze twee lijnen naar een methode te verhuizen die er dan zo kan uitzien:
static int VraagInt(string zin)
{
Console.WriteLine(zin);
return int.Parse(Console.ReadLine());
}
De code van zonet kan je dan nu herschrijven naar:
int leeftijd = VraagInt("Geef leeftijd");
Het voorgaande voorbeeld toont ook ineens aan waarom methoden helpen om je code leesbaarder en onderhoudbaarder te maken. Je Main blijft gevrijwaard van veel repeterende lijnen code en heeft aanroepen naar methoden met een duidelijke naam die ieder een specifiek ding doen. Dit maakt het debuggen ook eenvoudiger: je ziet in één oogopslag wat een methode doet.
Nu we methoden in de vingers krijgen, is het tijd om naar enkele gevorderde aspecten te kijken. Je hebt vermoedelijk al door dat methoden een erg fundamenteel concept zijn van een programmeertaal en dus hoe beter we ermee kunnen werken, hoe beter. 1
Wanneer je een methode aanroept is de volgorde van je actuele parameters belangrijk: deze moeten meegeven worden in de volgorde zoals de methode ze verwacht.
Met behulp van named parameters kan je echter expliciet aangeven welke actuele parameters aan welke formele parameter moet meegegeven worden.
Stel dat we een methode hebben met volgende signatuur:
Zonder named parameters zou een aanroep van deze methode als volgt kunnen zijn:
PrintDetails("Gift Shop", 31, "Red Mug");
We kunnen named parameters aangeven door de naam van de parameter gevolgd door een dubbel punt en de waarde. Als we dus bovenstaande methode willen aanroepen kan dat ook als volgt met named parameters:
Je mag echter ook een combinatie gebruiken van named en gewone parameters, maar dan is de volgorde belangrijk: je moet je dan houden aan de volgorde van de methode-signatuur. Je verbetert hiermee de leesbaarheid van je code, maar krijgt niet het voordeel van een eigen volgorde te hanteren. Enkele geldige voorbeelden:
Soms wil je dat een methode een standaardwaarde voor een parameter gebruikt indien de programmeur in z'n aanroep geen waarde meegaf. Dat kan met behulp zogenaamde van optionele of default parameters. Je geeft aan dat een parameter optioneel is door deze een default waarde te geven in de methode-signatuur. Deze waarde zal dan gebruikt worden indien de parameter geen waarde van de aanroeper heeft gekregen.
Let op: Optionele parameters worden steeds achteraan de parameterlijst van de methode geplaatst.
In het volgende voorbeeld maken we een nieuwe methode aan en geven aan dat de laatste twee parameters (optName en age) optioneel zijn door er met de toekenningsoperator een default waarde aan te geven:
static void BookFile(int required, string optName = "unknown", int age = 10)
Wanneer nu een parameter niet wordt meegegeven, dan zal deze default waarde in de plaats gebruikt worden:
BookFile(15, "tim", 25);
BookFile(20, "dams"); //age zal 10 zijn, optName "dams"
BookFile(35); //optName zal "unknown" en age zal 10 zijn
De inhoud van argumenten wordt bij iedere aanroep:
required
optName
age
Lijn 1
15
"tim"
25
Lijn 2
20
"dams"
10
Lijn 3
35
"unknown"
10
Je mag enkel de optionele parameters van achter naar voor weglaten. Volgende aanroep is dus niet geldig:
BookFile(3, 4); //daar de tweede param een string moet zijn
Met optionele parameters kunnen we dit omzeilen. Volgende aanroep is wel geldig:
Method overloading wil zeggen dat je een methode met dezelfde naam en returntype meerdere keren definieert maar met andere formele parameters qua datatype en/of aantal. De compiler zal dan zelf bepalen welke versie moet aangeroepen worden, gebaseerd op het aantal en type actuele parameters dat je meegeeft.
Volgende methoden zijn overloaded:
static int BerekenOpp(int lengte, int breedte)
{
int opp = lengte*breedte;
return opp;
}
static int BerekenOpp(int straal)
{
int opp = (int)(Math.PI*straal*straal);
return opp;
}
Afhankelijk van de aanroep zal dus de ene of andere methode uitgevoerd worden. Volgende code zal dus werken:
Indien de compiler twijfelt tijdens de overload resolution zal de betterness rule worden gehanteerd: de best passende methode zal aangeroepen worden.
Stel dat we volgende overloaded methoden hebben:
static int BerekenOpp(int straal) //versie A
{
int opp = (int)(Math.PI*straal*straal);
return opp;
}
static int BerekenOpp(double straal) //versie B
{
int opp = (int)(Math.PI * straal * straal);
return opp;
}
Volgende aanroepen zullen dus als volgt uitgevoerd worden, gebaseerd op de betterness rule:
Console.WriteLine($"Cirkel 1: {BerekenOpp(7)}"); //versie A
Console.WriteLine($"Cirkel 2: {BerekenOpp(7.5)}"); //versie B
Console.WriteLine($"Cirkel 3: {BerekenOpp(7.3f)}"); //versie B
Volgende tabel geeft de betternes rule weer. In de linkse kolom staat het datatype van de parameter die wordt meegegeven. De rechtse kolom toont welk datatype het argument in de methodesignatuur meer voorkeur heeft van links naar rechts indien dus het originele type niet beschikbaar is.
Als je bijvoorbeeld een parameter van het type int meegeeft bij een methode-aanroep (eerste kolom), dan zal een methode waar het argument een long verwacht geprefereerd worden boven een methode die voor datzelfde argument een float verwacht, enz.
Indien de betterness rule niet werkt, dan zal de eerste parameter bepalen wat er gebruikt wordt. Dat zien we in volgende voorbeeld:
static void Main(string[] args)
{
Toonverhouding(5, 3.4); //versie A
Toonverhouding(6.2, 3); //versie B
}
static void Toonverhouding(int a, double b) //versie A
{
Console.WriteLine($"{a}/{b}");
}
static void Toonverhouding(double a, int b) //versie B
{
Console.WriteLine($"{a}/{b}");
}
Indien ook die regel niet werkt dan zal volgende foutmelding verschijnen:
static void Main(string[] args)
{
Toonverhouding(5.6, 3.4);
}
static void Toonverhouding(int a, double b)
{
Console.WriteLine($"{a}/{b}");
}
static void Toonverhouding(double a, int b)
{
Console.WriteLine($"{a}/{b}");
}
Herinner je je dat ik in hoofdstuk 4 debuggen uitlegde en zei dat we één knopje later gingen bekijken? Wel die tijd is nu gekomen. Tijd om de step in knop toe te lichten.
Wanneer je een breakpoint zet in je code en in debugermode komt dan kan je doorheen je code stappen, wat je hopelijk al geregeld hebt gedaan. Het nadeel was dat je niet in een methode ging wanneer je daar over stapte. Wel, met de "step in" knop kan je dat nu wel. Wanneer je aan een lijn met een eigen geschreven methode komt dan zorgt deze knop ervoor dat je in de methode gaat en vervolgens daar verder kunt stappen over de verschillende lijnen code.
Het klinkt simpel, maar oefen het toch best een paar keer!
Arrays zijn een veelgebruikt principe in vele programmeertalen. Het grote voordeel van arrays is dat je één enkele variabele kunt hebben die een grote groep waarden voorstelt van eenzelfde type. Hierdoor wordt je code leesbaarder en eenvoudiger in onderhoud. Arrays zijn een zeer krachtig hulpmiddel, maar er zitten wel enkele venijnige addertjes onder het gras.
Op papier zijn arrays eenvoudig...helaas programmeren we zelden nog op papier. Eigenlijk is een array niets meer dan een verzameling waarden van hetzelfde datatype. Deze aparte waarden kunnen benaderd worden via 1 enkele variabele, de array zelf. Door middel van een index kan ieder afzonderlijk element uit de array aangepast of uitgelezen worden.
Een nadeel van arrays is dat, eens we de lengte van een array hebben ingesteld, deze lengte niet meer kan veranderd worden. In het hoofdstuk 12 zullen we leren werken met lists en andere collections die dit nadeel niet meer hebben.
De nadelen zullen we echter met plezier erbij nemen wanneer we programma's beginnen schrijven die werken met véél data van dezelfde soort: eenvoudigweg kan je stellen dat van zodra je 3 of meer variabelen hebt die dezelfde soort data bevatten (en dus van hetzelfde datatype zijn), een array bijna altijd de oplossing zal zijn.
Maar wat als je plots de neerslag van een heel jaar wenst te bewaren. Of een hele eeuw? Of een millennium?! Van zodra je een bepaalde soort informatie hebt die je veelvuldig wenst te bewaren dan zijn arrays dus de oplossing.
Voorgaande lijst van 7 aparte variabelen kunnen we eenvoudiger definiëren met 1 array (we bespreken de details verderop), genaamd regen:
Dat lijkt niet veel beter...Integendeel. We zitten nu ook nog met een hoop vierkante haakjes ([]) in onze code.
De kracht van arrays komt nu: het getal tussen die vierkante haakjes (de index) kan je als een variabele beschouwen en dus ook dynamisch genereren in een loop. Volgend voorbeeld toont hoe we bijvoorbeeld een langere array van elementen met een for-loop overlopen om de som van alle elementen te berekenen:
int[] regen = {34, 45, 0, 34, 12, 0, 23, 7, 20, 34, 7, 42}; //aanmaken array
double som = 0;
for(int i = 0; i<regen.Length;i++)
{
som += regen[i]; //element per element uit array optellen
}
double gemiddelde = som/regen.Length;
Sorry dat we weer even in het diepe water zijn gedoken. Het leek ons nuttig om even het totaalplaatje van arrays alvast uit de doeken te doen, zodat je snapt waarom er hier zo enthousiast over arrays wordt gedaan.
A propos, kijk eens achterom! Schrik je van hé. Je hebt al een aardige weg afgelegd als we vergelijken met de eerste keer toen ik je in het zwembad gooide.
Alles wordt kinderspel, als je maar lang genoeg met iets bezig bent. Zelfs de code die we net toonden met die arrays zou je niet meer zo erg mogen afschrikken als die eerste keer. Ok, er staan wat nieuwe termen tussen, maar al bij al zouden de grote lijnen van het algoritme en de werking ervan duidelijk moeten zijn.
Blijf dus maar hier lekker in het diep dobberen en ontdek verder waarom arrays zo'n krachtig concept zijn.
De eenvoudigste variant is deze waarbij je een array variabele aanmaakt, maar deze nog niet initialiseert. Je maakt enkel een identifier aan, maar zet er nog niets in. De syntax is als volgt:
type[] arraynaam;
Type kan eender welk bestaand datatype zijn dat je reeds kent. De [] (vierkante haken of square brackets) duiden aan dat het om een array gaat.
Voorbeelden van array declaraties kunnen dus bijvoorbeeld zijn:
Op dit punt bestaan de arrays nog niet . Hun lengte ligt nog niet vast. In het geheugen is enkel een klein stukje geheugen gereserveerd voor een toekomstige referentie (of pointer) naar een array (wat we zo meteen gaan uitleggen).
Stel dat je een array van strings wenst waarin je verschillende kleuren zal plaatsen dan schrijf je:
string[] myColors;
Vervolgens kunnen we later waarden toekennen aan de array:
Ook hier zal na lijn 1 je array een vaste lengte van 5 elementen hebben.
Merk op dat deze manier dus enkel werkt indien je reeds weet welke waarden in de array moeten. In manier 1 kunnen we perfect een array aanmaken en pas veel later in het programma ook effectief waarden toekennen (bijvoorbeeld door ze stuk per stuk door een gebruiker te laten invoeren).
Nog een andere manier om arrays aan te maken is diegene waarbij je aangeeft hoe groot de array moet zijn. We gaan echter nog niet effectief waarden in de array plaatsen.
string[] myColors;
myColors = new string[5];
Uiteraard kan dit ook in 1 stap:
string[] myColors = new string[5];
We geven hier aan dat de array vanaf z'n prille bestaan 5 elementen kan bevatten. Deze elementen zullen allemaal de defaultwaarde van hun datatype krijgen. In het geval van string hier zal de array dus 5 lege string-elementen bevatten ("" of string.Empty).
Ook hier geldt dat de lengte vanaf dan vastligt en niet meer kan veranderen.
Er is een essentieel verschil tussen manier 1 en 3. Wanneer je bij de sectie "Geheugengebruik bij arrays" bent zal je dit ontdekken. Spoiler: in manier 1 wordt er nooit een array aangemaakt in de eerste lijn. In manier 3 wél, dankzij het new keyword.
Van zodra er waarden in een array staan of moeten bijgeplaatst worden kan je deze benaderen met de zogenaamde array accessor notatie. Deze notatie is heel eenvoudigweg de volgende:
myColors[2]; //element met index 2
We plaatsen de naam van de array, gevolgd door vierkante haakjes waarbinnen een getal, 2 in dit voorbeeld, aangeeft het hoeveelste element we wensen te benaderen (lezen en/of schrijven). Deze nummering start vanaf 0.
De index van een C#-array start steeds bij 0. Indien je dus een array aanmaakt met lengte 5 dan heb je de indices 0 tot en met 4.
Veelgemaakte fouten bij arrays gebeuren op de lengte en indexering ervan.
Het gebeurt vaak dat beginnende programmeurs verward geraken omtrent het aanmaken van een array aan de hand van de lengte en het indexeren erna. Maar niet getreurd, ik zal je hier extra tips geven.
De regels zijn duidelijk:
Bij het maken van een array is de lengte van een array gelijk aan het aantal elementen dat er in aanwezig is. Dus een array met 5 elementen heeft als lengte 5.
Bij het schrijven en lezen van individuele elementen uit de array (zie hierna) gebruiken we een indexering die start bij 0. Bijgevolg is 4 de index van het laatste element in een array met lengte 5.
Je weet nu hoe je individuele waarden in een array kan benaderen. Ze gebruiken is exact hetzelfde zoals we in het verleden al met eender welke andere variabele hebben gedaan. Het enige verschil is dat de identifier vierkante haken met een index in bevat om aan te geven welke element we nodig hebben van de array.
Wanneer je dus het tweede element van een array wenst te gebruiken kan dit bijvoorbeeld als volgt:
Console.WriteLine(myColors[1]);
of ook
string kleurkeuze = myColors[1];
of zelfs
if(myColors[1] == "pink")
Kortom, alles wat je al kon, kan ook met arrays. Je kan ze zelfs als parameters aan methoden meegeven of terugkrijgen (zie verder). De individuele elementen in een array zijn gewone variabelen (enkel hun naamgeving is gekoppeld aan die van de array en de index van het element in de array).
Een array proberen te tonen als volgt gaat niet:
Console.WriteLine(myColors);
De enige manier alle elementen van een array te tonen is door manueel ieder element individueel naar het scherm te sturen. Bijvoorbeeld:
for(int i = 0 ; i<myColors.Length;i++)
{
Console.WriteLine($"{myColors[i]}");
}
Stel dat we een array van getallen hebben, dan kunnen we bijvoorbeeld 2 waarden uit die array optellen en opslaan in een andere variabele als volgt:
int[] numbers = {5, 10, 30, 45};
int som = numbers[0] + numbers[1];
De variabele som zal vervolgens de waarde 15 bevatten (5+10).
Stel dat we alle elementen uit de array numbers met 5 willen verhogen, dan kunnen we schrijven:
Maar eigenlijk zijn we dan het voordeel van arrays niet aan het gebruiken. Met loops maken we bovenstaande oplossing beter zodat deze zal werken, ongeacht het aantal elementen in de array1:
Ook schrijven van waarden naar een array gebruikt dezelfde notatie. Enkel moet je dus deze keer de array accessor-notatie links van de toekenningsoperator plaatsen. Stel dat we bijvoorbeeld de waarde van het eerste element uit de myColors array willen veranderen van red naar indigo, dan gebruiken we volgende notatie:
myColors[0] = "indigo";
Als we bij aanvang nog niet weten welke waarden de individuele elementen moeten hebben in een array, dan kunnen we deze eerst definiëren, en vervolgens individueel toekennen:
Een veel gestelde vraag wanneer een programmeur het nut van arrays nog niet 100% ziet is het volgende. Stel dat je deze code hebt;
int dag1 = 34;
int dag2 = 45;
int dag3 = 0;
int dag4 = 34;
int dag5 = 12;
int dag6 = 0;
int dag7 = 23;
"Kan ik die namen (dag1, dag2, enz.) met een loop genereren/bereiken zodat ik iets kan doen als volgt?"OPGELET! Hier komt een zeer fout voorbeeld aan...
for(int i=1; i<=7; i++)
dagi = ...
Dat gaat niet! De code op lijn 2 is verboden: van zodra je van plan bent om variabele-namen "dynamisch" in je code te proberen aan te roepen, moeten er tal van alarmbelletjes afgaan. De kans is dan héél groot dat je probleem beter met een array wordt opgelost dan met een boel variabelen met soortgelijke namen.
Soms kan het nodig zijn dat je in een later stadium van je programma de lengte van je array nodig hebt. De Length-eigenschap van iedere array geeft dit weer. Volgend voorbeeld toont dit:
De Length-eigenschap wordt vaak gebruikt in for/while loops waarmee je de hele array wenst te doorlopen. Door de Length-eigenschap te gebruiken als grenscontrole verzekeren we er ons van dat we nooit buiten de grenzen van de array zullen lezen of schrijven:
//Alle elementen van een array tonen
for (int i = 0; i < getallen.Length; i++)
{
Console.WriteLine(getallen[i]);
}
Elementen benaderen buiten de range van een array geeft erg dikke errors. Het jammer is dat VS dit soort subtiele 'out of range' bugs niet kan detecteren tijdens het compileren. Je zal ze pas ontdekken bij de uitvoer. Volgende code zal perfect gecompileerd worden, maar bij de uitvoer zal er op lijn 2 een foutboodschap verschijnen en het programma zal stoppen:
Dit zal resulteren in een "Out of Range exception".
Hackers misbruiken dit soort fouten in code om toegang tot delen van het geheugen te krijgen waar ze eigenlijk niet mochten zijn. Dit zijn zogenaamde buffer overflow attacks.
Sorry dat ik je al weer lastig val. Maar ik wil je nog eens extra goed naar bovenstaande fout (exception) laten kijken. Prent die Out of Range fout goed in je hoofd.
Deze fout zegt exact wat er mis is: je probeert elementen in een array te benaderen die niet bestaan omdat je buiten het bereik (range) van de array bent gegaan.
Momenteel werken we aan een gebouw met 3 verdiepingen (.Length is dus 3). Het is hetzelfde als wanneer ik tegen mijn personeel zeg: "ga jij de muur alvast metsen op de zesde verdieping (gebouw[5])". Hij zal dan vermoedelijk van het gebouw vallen en nog net kunnen roepen: "Out of Range exception!!!!".
Met al de voorgaande informatie is het nu mogelijk om vlot complexere programma's te schrijven, die veel data moeten kunnen verwerken. Meestal gebruikt men een for-loop om een bepaalde operatie over de hele array toe te passen.
Het volgende programma zal een array van integers aanmaken die alle gehele getallen van 0 tot 99 bevat. Vervolgens zal ieder getal met 3 vermenigvuldigd worden. Finaal tonen we enkel die getallen die een veelvoud van 4 zijn na de bewerking.
//Array aanmaken
int[] getallen = new int[100];
//Array vullen
for (int i = 0; i < getallen.Length; i++)
{
getallen[i] = i;
}
//Alle elementen met 3 vermenigvuldigen
for (int i = 0; i < getallen.Length; i++)
{
getallen[i] = getallen[i] * 3;
}
//Enkel veelvouden van 4 op het scherm tonen
for (int i = 0; i < getallen.Length; i++)
{
if(getallen[i] % 4 == 0)
Console.WriteLine(getallen[i]);
}
Begrijp je nu wat string[] args wil zeggen in je Main? Iedere Main heeft volgende methode-signatuur:
static void Main(string[] args)
De args arrays kunnen we in ons programma uitlezen om eventuele opstartparameters te verwerken die de gebruiker meegaf bij de opstart van het programma. Ik heb dit nog nooit in-depth uitgelegd, maar laten we eens kijken hoe je dit doet.
Volg daarom volgende stappenplan:
Maak een nieuw console-project aan genaamd argstest.
Voeg volgende code toe in je Main:
for (int i = 0; i < args.Length; i++)
{
Console.WriteLine(args[i]);
}
if (args.Length>=2 && args[2]=="cool")
{
Console.WriteLine("Ik ga akkoord!");
}
Compileer je programma. Run het gerust al eens, je zal zien dat het programma nog niet veel doet. Waarom? Omdat we geen opstartparameters hebben meegegeven. Laten we dat oplossen!
Ga via je verkenner naar je project-folder (vanuit VS kan dit snel door in de solution Explorer te rechterklikken op je project en dan de optie "Open folder in Explorer" te kiezen).
Open de bin folder, en open daarin dan de debug folder, gevolgd door de net8.0 folder (die laatste kan mogelijk anders zijn, afhankelijk van welke .NET versie je gebruikt). Hier staat je gecompileerde programma. In principe kan je hier dubbelklikken op je applicatie, maar dat zal niet veel doen, daar we nog steeds geen opstartparameters hebben meegegeven.
Nu goed opletten: klik in je verkenner bovenaan in de adresbalk, rechts van de tekst (niet er op). Je kan nu zelf iets intypen. Typ nu cmd in en druk enter.
Cool he. Je zit nu in een shell in de juiste folder.
Nu kan je je programma runnen mét opstartparameters. Kijk maar eens wat er gebeurt als je typt: argstest ziescherp is cool
Inderdaad. De spaties gelden als "splitsing" tussen ieder argument. En dus ieder woord zal een apart element in de args array worden. Je zou nu bijvoorbeeld code kunnen schrijven die iets doet afhankelijk van de parameter, enz.
Let er zeker op dat je steeds met args.Length test of er wel genoeg opstartargumenten werden meegegeven. Daarom dat we args.Length>=2 && args[2]=="cool" schreven.
De volgorde van operanden bij een && operator zijn belangrijk. Kijk wat er gebeurt als we de operanden omwisselen in de vorige if:
if ( args[2]=="cool" && args.Length>=2)
Als je deze versie uitvoeren met minder dan 3 opstartparameters, dan zal de applicatie crashen. Waarom? De &&-operator werkt van links naar echts en zal stoppen met testen indien de linkse operand reeds false teruggeeft. Door dus éérst te testen of de lengte klopt, komen we enkel bij de args[2]-code als die ook effectie kan aangeroepen worden.
Kortom: denk ook steeds goed na in welke volgorde je je conditionele testen beschrijft.
Met arrays komen we voor het eerst iets dichter tot één van de sterktes van C#, namelijk het aspect referenties. Vanaf het volgende hoofdstuk zullen we hier ongelooflijk veel mee doen, maar laten we nu alvast eens kijken waarom arrays met referenties werken.
We zagen reeds bij methoden dat variabelen eigenlijk op 2 manier kunnen doorgegeven worden, by reference of by value. We herhalen dat hier nog eens:
Value types: deze variabelen bevatten effectief de waarde die de variabele moet hebben. Als we schrijven int age = 5, dan bewaren we de binaire voorstelling voor het geheel getal 5 in het geheugen.
Reference types: deze variabelen bewaren een geheugenadres naar een andere plek in het geheugen waar de effectieve waarde(n) van de variabele te vinden is. Reference types zijn als het ware een wegwijzer en worden ook soms pointers genoemd.
Alle datatypes die we tot nog toe zagen - string is een speciaal geval en negeren we om nachtmerries te vermijden- werken steevast by value. Momenteel zijn het enkel arrays die we kennen die by reference werken in C#. In het volgende hoofdstuk zullen we zien dat er echter nog een hele hoop andere mysterieuze dingen (genaamd objecten) zijn die ook by reference werken.
Arrays worden steeds by reference in een variabele bewaard! Dat wil dus zeggen dat we niet de array zelf toekennen aan een variabele, maar wel het geheugenadres naar de array. Dit heeft natuurlijk gevolgen op de manier dat bijvoorbeeld de toekennings-operator (=) werkt bij arrays.
In getallen bewaren enkel een geheugenadres bewaren dat wijst naar de plek waar de effectieve waarden staan elders in het geheugen. Terwijl in age effectief de waarde "5" zal bewaard worden. De afbeelding op volgende pagina geeft dit weer.
Het gevolg van voorgaande is dat volgende code niet zal doen wat je vermoedelijk wenst:
De situatie wanneer lijn 2 werd uitgevoerd is de volgende:
Zonder het bestaan van references zou je verwachten dat op lijn 3 nieuwePloegen een kopie krijgt van de inhoud van ploegen. Dat is dus niet zo.
Lijn 3 zal perfect werken. Wat er echter is gebeurd, is dat we de referentie naar ploegen ook in nieuwePloegen hebben geplaatst. Bijgevolg verwijzen beide variabelen naar dezelfde array, namelijk die waar ploegen al naar verwees. We hebben een soort alias gemaakt en kunnen nu op twee manieren de array met de Antwerpse voetbalploegen benaderen. De nieuwe situatie na lijn 3 is dus de volgende geworden:
Als je vervolgens schrijft:
nieuwePloegen[1] = "Beerschot";
Dan is dat hetzelfde als onderstaande schrijven daar beide variabele naar dezelfde array-inhoud verwijzen. Het effect zal dus hetzelfde zijn.
ploegen[1] = "Beerschot";
En waar staan de ploegen in de nieuwePloegen array ("Anderlecht" en "Brugge")? Die array in het geheugen is niet meer bereikbaar (de garbage collector zal deze ten gepaste verwijderen, wat in hoofdstuk 10 zal toegelicht worden).
Je moet manueel ieder individueel element van de ene naar de andere array kopiëren als volgt:
for(int i = 0; i < ploegen.Length; i++)
{
nieuwePloegen[i] = ploegen[i];
}
Er is een ingebouwde methode in de Array-bibliotheek (deze bibliotheek zien we in de volgende sectie) die ook toelaat om arrays te kopiëren genaamd Copy.
Wanneer je met arrays van objecten (zie hoofdstuk 12) werkt dan zal bovenstaande mogelijk niet het gewenste resultaat geven daar we nu ook de individuele referenties van een object kopiëren!
Je kan de System.Array bibliotheek gebruiken om je array-code te vereenvoudigen. Deze bibliotheek bevat naast de .Length eigenschap, ook enkele nuttige methoden zoals BinarySearch(), Sort(), Copy en Reverse(). Het gebruik hiervan is bijna steeds hetzelfde zoals volgende voorbeelden tonen.
Om arrays te sorteren roep je de Sort()-methode op en geef je als parameter de array mee die gesorteerd moet worden. Volgend voorbeeld toont hier het gebruik van:
string[] myColors = {"red", "green", "yellow", "orange", "blue"};
Array.Sort(myColors); //Sorteren maar
//Toon resultaat van sorteren
for (int i = 0; i < myColors.Length; i++)
{
Console.WriteLine(myColors[i]);
}
Wanneer je de Sort-methode toepast op een array van strings dan zullen de elementen alfabetisch gerangschikt worden. Uiteraard werkt dit ook op arrays van andere datatypes. Zolang C# maar weet hoe dit type gesorteerd moet worden, zal dit werken. Het zal getallen van klein naar groot sorteren, tekst volgens de regels van het alfabet, enums volgens hun interne voorstelling, enz.
Met de Array.Reverse()-methode kunnen we dan weer de volgorde van de elementen van de array omkeren (dus het laatste element vooraan zetten en zo verder):
Een array volledig leegmaken waarbij alle elementen op hun standaard waarde zetten (bv. 0 bij int, enz.) doe je met de Array.Clear()-methode, als volgt:
Array.Clear(myColors,0, myColors.Length);
Hierbij geeft de tweede parameter aan vanaf welke index moet leeggemaakt worden, en de derde hoeveel elementen vanaf die index.
De .Copy() behelst iets meer werk, daar deze methode:
een reeds aangemaakte, nieuwe array nodig heeft, waar naar gekopiëerd moet worden.
moet meekrijgen hoe lang de bronarray (source) is, of hoeveel elementen uit de bronarray moeten gekopiëerd worden.
Volgend voorbeeld toont hoe we alle elementen uit myColors kunnen kopiëren naar een nieuwe array copyColors. De eerste parameter is de bron-array, dan de doel-array en finaal het aantal elementen dat moet gekopiëerd worden:
Willen we enkel de eerste twee elementen kopiëren dan zou dat er als volgt uitzien:
Array.Copy(myColors, copyColors, 2);
Bekijk zeker ook de overloaded versies die de .Copy() methode heeft. Zo kan je ook een bepaald stuk van een array kopiëren en ook bepalen waar in de doel-array dit stuk moet komen.
De BinarySearch-methode maakt het mogelijk om te zoeken naar de index van een gegeven element in een array.
De BinarySearch-methode werkt enkel indien de elementen in de array gesorteerd staan!
Je geeft aan de methode 2 parameters mee: enerzijds de array in kwestie en anderzijds het element dat we zoeken. Als resultaat wordt de
index van het gevonden element teruggegeven. Indien niets wordt gevonden zal het resultaat negatief zijn.
Volgende code zal bijvoorbeeld de index teruggeven van de kleur "red" indien deze in de array myColors staat:
int indexRed = Array.BinarySearch(myColors, "red");
Volgend voorbeeld toont het gebruik van deze methode:
int[] metingen = {224, 34, 156, 1023, -6};
Array.Sort(metingen); //anders zal BinarySearch niet werken
Console.WriteLine("Welke meting zoekt u?");
int keuze = int.Parse(Console.ReadLine());
int index = Array.BinarySearch(metingen, keuze);
if(index >= 0)
Console.WriteLine($"{keuze} gevonden op {index}");
else
Console.WriteLine("Niet gevonden");
Omdat arrays ongelooflijk groot kunnen worden, is het nuttig dat je algoritmes kunt schrijven die vlot met arrays kunnen werken. Je wilt niet dat je programma er 3 minuten over doet om gewoon te ontdekken of een bepaalde waarde in een array voorkomt of niet1. We zullen nu 2 typische algoritmen bespreken die vaak voorkomen als je met loops en arrays aan de slag gaat gaan.
1
Bij jobsollicaties voor programmeurs word je soms gevraagd om dergelijke algoritmes zonder hulp uit te schrijven.
Twee maar!? Er zijn tal van andere algoritmes. Denk maar aan de verschillende manieren om arrays te sorteren (bijvoorbeeld de fameuze bubblesort en quicksort algoritmes). Al deze algoritmes hier bespreken zou een boek apart vereisen. Ik toon er daarom enkele ter illustratie.
Het nadeel van BinarySearch is dat deze vereist dat je array-elementen gesorteerd staan. Uiteraard is dit niet altijd gewenst. Stel je voor dat je een simulatie maakt voor een fietswedstrijd en wilt weten of een bepaalde wielrenner in de top 5 staat.
Het zoeken in arrays kan met behulp van loops tamelijk snel. Volgende applicatie gaat zoeken of het getal 12 aanwezig is in de array (de wielrenners werken met rugnummers). Indien ja dan wordt de index bewaard van de positie in de array waar het getal staat:
int teZoekenGetal = 12;
int[] top5 = { 5, 10, 12, 25, 16 };
bool gevonden = false;
int index = 0;
do
{
if (top5[index] == teZoekenGetal)
{
gevonden = true;
}
index++;
} while ( !gevonden && index < top5.Length);
if (gevonden)
{
Console.WriteLine($"Nr. {teZoekenGetal} op plek {index}");
}
Ik toon nu een voorbeeld van hoe je kan zoeken in een array wanneer we bijvoorbeeld 2 arrays hebben die 'synchroon' zijn. Daarmee bedoel ik: de eerste array bevat bijvoorbeeld producten, de tweede array bevat de prijs van ieder product. De prijs van de producten staat steeds op dezelfde index in de andere array (de prijs van peren is dus 6.2, meloenen 2.9, enz.) :
Het type string is niet meer dan een arrays van karakters, char[]. Het is dan ook logisch dat we dit erg belangrijke datatype even apart toelichten en enkele nuttige methoden tonen om strings te manipuleren.
Ook de omgekeerde weg is mogelijk. De werking is iets anders en maakt gebruik van new string(). Let vooral op hoe we de char array doorgeven als argument bij het aanmaken van een nieuwe string in lijn 3:
Deze methode geeft een int terug die de index bevat waar de string die je als parameter meegaf begint. Je kan deze index gebruiken om te ontdekken of een bepaald woord bijvoorbeeld in een grote lap tekst voorkomt zoals volgend voorbeeld toont:
string boek = "Ik ben Reinhardt";
int index = boek.IndexOf("ben");
Console.WriteLine(index);
Er zal 3 verschijnen op scherm. De substring "ben" start op positie 3. "ik" staat op positie 0 en 1, gevolgd door een spatie op positie 2. Indien de string niet gevonden werd, zal index de waarde -1 krijgen.
Trim() verwijdert alle onnodige spaties en andere onzichtbare tekens vooraan en achteraan de string. Deze methode geeft de opgekuiste string terug als resultaat. Dit resultaat moet je dus bewaren als je er nog iets mee wilt doen. In het volgende voorbeeld overschrijven we de originele string met z'n opgekuiste versie:
string boek = " Ik ben Reinhardt ";
Console.WriteLine(boek);
boek = boek.Trim();
Console.WriteLine(boek);
Dit zal de output op het scherm zijn (de spaties achteraan op lijn 1 zie je niet, maar zijn er dus wel):
Replace(string old, string news) zal in de string alle substrings die gelijk zijn aan old vervangen door de meegegeven news string. Vervolgens zal de nieuwe string als resultaat worden teruggeven.
Volgende voorbeeld toont dit en zal "Mercy" vervangen door "Reinhardt":
string boek = "Ik ben Mercy";
boek = boek.Replace("Mercy","Reinhardt");
Console.WriteLine(boek);
Replace kan je ook misbruiken om bijvoorbeeld alle woorden uit een stuk tekst te verwijderen door deze te vervangen door een lege string met de waarde "". Volgende code zal alle "e"'s uit de tekst verwijderen:
Remove(int start, int lengte) zal op de index start alle lengte volgende karakters in de string verwijderen en een nieuwe, kortere string als resultaat geven.
Volgend voorbeeld zal het stukje "ben " uit de string weghalen:
string boek = "Ik ben Mercy";
boek = boek.Remove(3,4);
Console.WriteLine(boek);
Output op het scherm:
Ik Mercy
In voorgaande voorbeeld gaven we de methode Remove de opdracht: "verwijder alles vanaf het element met index 3 (de b) en dit gedurende 4 tekens (dus tot en mét de spatie na ben)".
Zoals alle datatypes kan je ook arrays van eender welk datatype als parameter gebruiken bij het schrijven van een methode. Lees nu volgende waarschuwing extra aandachtig, a.u.b:"
Herinner je dat arrays by reference werken. Je werkt dus steeds met de origineel meegegeven array (of beter, de referentie er naar), ook in de methode. Als je dus aanpassingen aan de array aanbrengt in de methode, dan zal dit ook gevolgen hebben op de array van waaruit we de methode aanriepen.
Stel dat je bijvoorbeeld een methode hebt die als parameter 1 array van ints meekrijgt. De methode zou er dan als volgt uitzien:
static void LeesData(int[] inArray)
{
}
Om deze methode aan te roepen volstaat het om een bestaande array als parameter mee te geven:
Een array als parameter meegeven kan dus, maar een ander aspect waar rekening mee gehouden moet worden is dat je niet kan ingeven in de parameterlijst hoe groot de array is. Je zal dus in je methode steeds de grootte van de array moeten uitlezen met de .Length-eigenschap.
Een array kan ook gebruikt worden als het returntype van een methode. Hiervoor zet je gewoon het type array als returntype in de methodesignatuur. Ook hier mag geen grootte aangeven.
Stel bijvoorbeeld dat je een methode hebt die een int-array aanmaakt van een gegeven grootte waarbij ieder element van de array reeds een beginwaarde heeft die je ook als parameter meegeeft:
static int[] MaakArray(int lengte, int beginwaarde)
{
int[] resultArray = new int[lengte];
for (int i = 0; i < lengte; i++)
{
resultArray[i] = beginwaarde;
}
return resultArray;
}
De aanroep van deze methode vereist dan dat je het resultaat opvangt in een nieuwe variabele, als volgt:
int[] mijnNieuweArray = MaakArray(4,666);
Snel, zet je helm op, voor er ongelukken gebeuren! Ik had al enkele keren gezegd dat arrays by reference worden meegegeven, maar wat is daar nu het gevolg van? Wel, laten we eens naar volgende programmaatje kijken dat ik heb geschreven om de nummering van de appartementen in een flatgebouw aan te passen.
Zoals je weet is het gelijkvloers in sommige landen 0, terwijl in andere dit 1 is. Volgende programma past het nummer van het gelijkvloers aan:
Daar de methode nu werkt met een kopie, zal de aanpassing in de methode dus geen invloed hebben op de origineel meegegeven int (ongeacht dat die deel uitmaakt van een array).
Voorlopig hebben we enkel met zogenaamde 1-dimensionale arrays gewerkt. Je kan echter ook meerdimensionale arrays maken. Denk maar aan een n-bij-m array om een matrix voor te stellen. Ik bespreek meerdimensionale arrays maar kort om de eenvoudige reden dat je die in de praktijk minder vaak zal nodig hebben.
Stel je het voorbeeld aan het begin van dit hoofdstuk voor, waarin we de regenval gedurende 7 dagen wilden meten. Wat als we dit gedurende 4 weken wensen te doen, maar wel niet alle data in één lange array willen plaatsen? We zouden dan een 2-dimensionale array kunnen maken als volgt:
De arrays die we nu behandelen zullen steeds "rechthoekig" zijn. Daarmee bedoelen we dat ze steeds per rij of kolom evenveel elementen zullen bevatten als in de andere rijen of kolommen.
Arrays die per rij of kolom een andere hoeveelheid elementen hebben zijn zogenaamde jagged arrays, welke we verderop kort zullen bespreken.
Ook om nu effectief een array aan te maken gebruiken we de komma-notatie, alleen moeten we nu ook de effectieve groottes aangeven. Voor een 5 bij 10 array bijvoorbeeld schrijven we (merk op dat dit dus een 2D-array is):
int[,] matrix = new int[5,10];
Om een array ook onmiddellijk te initialiseren met waarden gebruiken we de volgende uitdrukking :
Merk op dat we dus nu een 3 bij 4 array maken maar dat dit dus nog steeds een 2D-array is. Iedere rij bestaat uit 3 elementen. We maken letterlijk een array van arrays.
Zoals je ziet worden meerdimensionale arrays snel een kluwen van komma's, accolades en haakjes. Probeer dus je dimensies te beperken. Je zal zelden een 3 -of meer dimensionale array nodig hebben.
De regel is eenvoudig: als je een 7-dimensionale array nodig hebt, is de kans groot dat je een volledig verkeerd algoritme hebt verzonnen ... of dat je nog niet aan hoofdstuk 9 bent geraakt ... of dat je een topwetenschapper in CERN bent. Choose your reason!
Stel dat we uit de boeken-array de auteur van het derde boek wensen te tonen dan kunnen we schrijven:
Console.WriteLine(boeken[2, 1]);
Dit zal Mike Pastore op het scherm zetten.
En bij de temperaturen:
Console.WriteLine(temperaturen[2, 0, 1]);
Dit zal 27 teruggeven. We vragen van de laatste array ([2]), daarbinnenin de eerste array (rij [0]) en daarvan het tweede element(kolom [1]).
Indien je de lengte opvraagt van een meer-dimensionale array dan krijg je de som van iedere lengte van iedere dimensie. Dit is logisch: in het geheugen van een computer worden arrays altijd als 1 dimensionale arrays voorgesteld. De boeken array zal lengte 12 hebben (3*4) en temperaturen toevallig ook (3x2x2).
Je kan echter de lengte van iedere aparte dimensie te weten komen met de .GetLength() methode die iedere array heeft. Als parameter geef je de dimensie mee waarvan je de lengte wenst:
int arrayRijen = boeken.GetLength(0); //geeft 4
int arrayKolommen = boeken.GetLength(1); //geeft 3
Het aantal dimensies van een array wordt trouwens weergegeven door de .Rank eigenschap die ook iedere array heeft. Bijvoorbeeld:
Jagged arrays (letterlijk gekartelde arrays) zijn arrays van arrays maar van verschillende lengte. De arrays die we totnogtoe zagen moesten steeds rechthoekig zijn. Jagged arrays, zoals de naam doet vermoeden, hoeven dat niet te zijn:
Ik ga niet al te diep in deze arrays ingaan omdat deze, alhoewel erg nuttig, vaak omslachtige, meer foutgevoelige code zullen creëren. Meestal zijn er gezondere alternatieven te gebruiken zoals de verschillende collectie-klassen uit hoofdstuk 12.
De indexering blijft dezelfde, maar ook hier dus niet met komma's, maar met vierkante haken (bijvoorbeeld tickets[0][1]).
Uiteraard moet je er wel rekening mee houden dat niet eender welke index binnen een bepaalde sub-array zal werken, het is dan ook aangeraden om zeker de Length-methode te gebruiken om de sub-arrays op hun lengte te bevragen. Wanneer je .Length bevraagt van de tickets array dan zal je 3 als antwoord krijgen, daar deze 2D array uit 3 sub-arrays bestaat.
Wil je vervolgens de lengte kennen van de middelste sub-array (met dus index 1) dan gebruik je tickets[1].Length.
Tot nu toe heb je vooral geleerd om gestructureerd te programmeren - soms ook wel procedureel programmeren genoemd - een programmeerconcept uit de jaren zestig. Hierbij schrijf je code gebruik makend van methoden, loops en beslissingsstructuren.
Hoewel gestructureerd programmeren erg nuttig blijft, wordt het bij complexere applicaties vaak minder intuïtief en soms nodeloos complex. Een middelgroot project verzandt al gauw in moeilijk te onderhouden spaghetti code.
Er is echter een alternatief: object georiënteerd Programmeren (OOP, Object Oriented Programming). OOP bouwt voort op gestructureerd programmeren, maar maakt het mogelijk om veel krachtigere applicaties te ontwikkelen.
Bij OOP draait alles rond klassen en objecten die intern nog steeds gestructureerde code bevatten. Alle bekende concepten zoals loops, methoden en beslissingsstructuren blijven bestaan. We gaan ze echter verpakken in handige, kleinere aparte klassen. Met OOP wordt onze code modulair, leesbaarder en onderhoudsvriendelijker. Bovendien wordt de code krachtiger en kunnen we complexere problemen eenvoudiger oplossen.
Ik zet "oplossen" tussen aanhalingstekens. Net zoals alles binnen dit domein ben jij als programmeur uiteindelijk degene die het boeltje moet oplossen. Code, programmeerparadigma's en bibliotheken zijn niet meer dan nuttig gereedschap in jouw arsenaal van programmeertools. Als jij beslist om een hamer als zaag te gebruiken... Tja, dan houd ik m'n hart vast voor het resultaat.
Dit geldt ook voor de technieken die je nog in dit boek gaat leren: ze zijn "een tool", niets meer. Jij zal ze nog steeds zo optimaal mogelijk moeten leren gebruiken. Uiteraard is het doel van dit boek je zo duidelijk mogelijk het verschil én de bruikbaarheid van de verschillende nieuwe technieken aan te leren.
Toen C# werd ontwikkeld in 2001 was één van de hoofddoelen van de programmeertaal om "een eenvoudige, moderne, objectgeoriënteerde programmeertaal voor algemene doeleinden" te worden. C# is van de grond af opgebouwd met het OOP paradigma als primaire drijfveer. Een paradigma is een algemeen geaccepteerde manier van denken en doen binnen een bepaald vakgebied, in dit geval binnen de programmeerwereld.
Wanneer we nieuwe programma's in C# ontwikkelden dan zagen we hier reeds bewijzen van. Zo zagen we steeds het keyword class bovenaan staan, telkens we een nieuw project aanmaakten:
namespace WorldDominationTool
{
internal class Program
{
De klasse Program zorgt ervoor dat ons programma voldoet aan de C# afspraken die zeggen dat alle C# code in klassen moet staan.
Duizend mammoeten en sabeltandtijgers! Ik dacht dat ik nu wel mee zou zijn met alles wat C# me zou voorschotelen. Helaas, wolharige neushoorn-kaas, niet dus. Ik ga een voorspelling doen: van alle hoofdstukken in dit boek, wordt dit hoofdstuk hetgene waar je het meest je tanden op gaat stuk bijten. Hou dus vol, geef niet te snel op en kom geregeld hier terug. Succes gewenst!
Om de kracht van OOP te demonstreren gaan we een applicatie van lang geleden (deels) herschrijven gebruik makende van de kennis van de vorige 8 hoofdstukken. We gaan de arcadehal klassieker "Pong" deels namaken, waarbij we als doel hebben om een balletje alvast op het scherm te laten botsen. Een rudimentaire oplossing zou de volgende kunnen zijn:
Console.CursorVisible = false;
int balX = 20;
int balY = 20;
int vX = 2;
int vY = 1;
while (true)
{
//vX van richting veranderen aan de randen
if (balX + vX >= Console.WindowWidth || balX+vX < 0)
{
vX = -vX;
}
balX = balX + vX; //X positie updaten
//vY van richting veranderen aan de randen
if (balY + vY >= Console.WindowHeight || balY+vY < 0)
{
vY = -vY;
}
balY = balY + vY; //Y positie updaten
//Output naar scherm sturen
Console.SetCursorPosition(balX, balY);
Console.Write("O");
System.Threading.Thread.Sleep(50); //50 ms wachten
Console.Clear();
}
Hopelijk begrijp je deze code. Test ze maar eens in een programma. Zoals je zal zien krijgen we een balletje ("O") dat over het scherm vliegt en telkens van richting verandert wanneer het aan de randen van het applicatievenster komt. De belangrijkste informatie zit in de variabelen balX, balY die de huidige positie van het balletje bevatten. Voorts zijn ook vX en vY belangrijk: hierin houden we bij in welke richting (en met welke snelheid) het balletje beweegt (een zogenaamde bewegingsvector).
Dit soort applicatie in C# schrijven met behulp van gestructureerde programmeer-concepten is redelijk eenvoudig. Maar wat als we nu 2 balletjes nodig hebben? Laten we arrays even links laten liggen en het gewoon eens naïef oplossen. Al na enkele lijnen kopiëren merken we dat onze code ongelooflijk rommelachtig gaat worden en we bijna iedere lijn moeten dupliceren:
Console.CursorVisible = false;
int balX = 20;
int balY = 20;
int vX = 2;
int vY = 1;
int bal2X = 10;
int bal2Y = 8;
int v2X = 2;
int v2Y = -1;
while (true)
{
if (balX + vX >= Console.WindowWidth || balX+ vX < 0)
{
vX = -vX;
}
if (bal2X + v2X >= Console.WindowWidth || bal2X + v2X < 0)
{
v2X = -v2X;
}
balX = balX + vX;
bal2X = bal2X + v2X;
//enzovoort
Bijna iedere lijn code moeten we verdubbelen. Arrays zouden dit probleem deels kunnen oplossen, maar we krijgen dan in de plaats de complexiteit van werken met arrays op ons bord. Dat is voor 2 balletjes misschien wat overdreven. Het zal op de koop toe onze terug minder leesbaar maakt.
Uiteraard zijn we nu eventjes gestructureerd programmeren aan het demoniseren, dit is echter een bekend 21e eeuws trucje om je punt te maken.
Wanneer we Pong met het OOP paradigma willen aanpakken dan is het de bedoeling dat we werken met klassen en objecten.
Net zoals aan de start van dit boek ga ik je ook nu even in het diepe gedeelte van het bad gooien. Wees niet bang, ik zal je er tijdig uithalen! Je zal versteld staan hoeveel code je eigenlijk zult herkennen.
Om Pong in OOP te maken hebben we eerst een klasse nodig waarin we ons balletje gaan beschrijven, zonder dat we al een balletje hebben. En dat ziet er zo uit:
internal class Balletje
{
//Eigenschappen
public int X { get; set; }
public int Y { get; set; }
public int VX { get; set; }
public int VY { get; set; }
//Methoden
public void Update()
{
if (X + VX >= Console.WindowWidth || X + VX < 0)
{
VX = -VX;
}
X = X + VX;
if (Y + VY >= Console.WindowHeight || Y + VY < 0)
{
VY = -VY;
}
Y = Y + VY;
}
public void TekenOpScherm()
{
Console.SetCursorPosition(X, Y);
Console.Write("O");
}
}
De code voor een nieuwe klasse schrijf je best in een apart bestand in je project. Klik bovenaan in de menu balk op "Project" en kies dan "Add class...". Geef het bestand de naam "Balletje.cs".
Bijna alle code van zonet hebben we hier geïntegreerd in een class Balletje, maar er zit duidelijk een nieuw sausje over. Vooral aan het begin zien we onze 4 variabelen terugkomen in een nieuw kleedje: namelijk als eigenschappen oftewel properties (herkenbaar aan de get en set keywords).
Maar al bij al lijkt de code grotendeels op wat we al kenden. En dat is goed nieuws. OOP gooit de vorige hoofdstukken niet in de vuilbak, het gaat als het ware een extra laag over het geheel leggen. Let ook op het essentiële woordje class bovenaan, daar draait alles natuurlijk om: klassen en objecten.
Een klasse is een blauwdruk van een bepaalde soort 'dingen' of objecten. Objecten zijn de "echte" dingen die werken volgens de beschrijving van de klasse. Ja ik heb zonet 2x hetzelfde verteld, maar het is essentiëel dat je het verschil tussen de termen klasse en object goed begrijpt.
Laten we eens een balletje-object in het leven roepen. In de main schrijven we daarom dit:
Ok, interessant. Die new heb je al gezien wanneer je met Random ging werken en de code erna is ook nog begrijpbaar: we stellen eigenschappen van het nieuwe bal1 object in. En nu komt het! Kijk hoe eenvoudig onze volledig main nu is geworden:
Dit is de volledige code om 2 balletjes te hebben. Hoe mooi is dat?!
De kracht van OOP zit hem in het feit dat we de logica IN DE OBJECTEN ZELF plaatsen. De objecten zijn met andere woorden verantwoordelijk om hun eigen gedrag uit te voeren gebaseerd op externe impulsen en hun eigen interne toestand. In onze main zeggen we aan beide balletjes "update je zelf eens", gevolgd door "teken je zelf eens".
Wanneer we 3 of meer balletjes zouden nodig hebben dan zullen we best arrays in de mix moeten gooien. Onze code blijft echter véél eenvoudiger én krachtiger dan wanneer we in het voorgaande enkel de kennis gebruikten die we totnogtoe hadden. Omdat we toch al in het diepe eind zitten, zal ik hier toch al eens tonen hoe we 100 balletjes op het scherm kunnen laten botsen (we gaan Random gebruiken zodat er wat willekeurigheid in de balletjes zit):
const int AANTAL_BALLETJES = 100;
Random r = new Random();
Balletje[] veelBalletjes = new Balletje[AANTAL_BALLETJES];
for (int i = 0; i < veelBalletjes.Length; i++) //balletjes aanmaken
{
veelBalletjes[i] = new Balletje();
veelBalletjes[i].X = r.Next(10, 20);
veelBalletjes[i].Y = r.Next(10, 20);
veelBalletjes[i].VX = r.Next(-2, 3);
veelBalletjes[i].VY = r.Next(-2, 3);
}
while (true)
{
for (int i = 0; i < veelBalletjes.Length; i++)
{
veelBalletjes[i].Update(); //update alle balletjes
}
for (int i = 0; i < veelBalletjes.Length; i++)
{
veelBalletjes[i].TekenOpScherm(); //teken alle balletjes
}
System.Threading.Thread.Sleep(50);
Console.Clear();
}
De reden dat we nu twee loops gebruiken, is omdat we in de updatefase eerst alle objecten willen bijwerken (soms in relatie tot andere objecten) voordat we alles opnieuw op het scherm tekenen. Anders kan het zijn dat je vreemde effecten te zien krijgt als je bijvoorbeeld balletjes tegen elkaar wil laten wegbotsen.
Ok, zwem maar snel naar de kant. We gaan al het voorgaande van begin tot einde uit de doeken doen! Leg die handdoek niet te ver weg, we gaan hem nog nodig hebben.
Een elementair aspect binnen OOP is het verschil begrijpen tussen een klasse en een object.
Wanneer we meerdere objecten gebruiken van dezelfde soort dan kunnen we zeggen dat deze objecten allemaal deel uitmaken van een zelfde klasse. Het OOP paradigma houdt ook in dat we de echte wereld gaan proberen te modeleren in code. OOP laat namelijk toe om onze code zo te structureren zoals we dat ook in het echte leven doen. Alles om ons heen behoort tot een bepaalde klasse die alle objecten van dat type beschrijven.
Neem eens een kijkje aan een druk kruispunt waar fietsers, voetgangers, auto's en verkeerslichten samenkomen1. Het is een erg hectisch geheel, toch kan je alles dat je daar ziet classificeren. We zien bijvoorbeeld allemaal mens-objecten die tot de klasse van de Mens behoren, maar ook:
Alle mensen hebben gemeenschappelijke eigenschappen (binnen deze beperkte context van een kruispunt): ze bewegen of staan stil (gedrag), ze hebben een bepaalde kleur van jas (eigenschap).
Alle auto's behoren tot een klasse Auto. Ze hebben gemeenschappelijke zaken zoals: een bouwjaar (eigenschap), ze werken op een bepaalde vorm van energie (eigenschap) en ze staan stil of bewegen (gedrag).
Ieder verkeerslicht behoort tot de klasse VerkeersLicht.
Fietsers behoren tot de klasse Fietser.
1
Dit voorbeeld is gebaseerd op de inleiding van het inzichtvolle boek "Handboek objectgeoriënteerd programmeren" door Jan Beurghs (EAN: 9789059406476).
Volgende 2 definities druk je best af op een grote poster die je boven je bed hangt:
Een klasse is als een blauwdruk (of prototype) dat het gedrag en toestand beschrijft van alle objecten van deze klasse.
Een individueel object is een instantie van een klasse en heeft een eigen toestand, gedrag en identiteit.
Objecten zijn instanties met een eigen levenscyclus die wordt gekenmerkt door:
Gedrag: deze wordt beschreven door de methoden in de klasse.
Toestand: deze kan wijzigen door zijn eigen gedrag, of door externe impulsen en wordt bepaald door datavelden die beschreven staan in de klasse (properties en instantievariabelen).
Identiteit : een unieke naam van object zodat andere objecten ermee kunnen interageren.
Je zou dit kunnen vergelijken met het grondplan voor een huis dat tien keer in een straat zal gebouwd worden. Het plan is de klasse. De effectieve huizen die we bouwen aan de hand van dit plan zijn de instanties of objecten van deze klasse. Ieder huis heeft een eigen toestand (ander type bakstenen, wel of geen zonnepannelen) en gedrag (rolluiken gaan open als de zon opkomt).
De klasse beschrijft het algemene gedrag van de individuele objecten. Dit gedrag wordt meestal bepaald door de interne staat van ieder object op zichzelf, de zogenaamde eigenschappen. Nemen we het voorbeeld van de klasse Auto: de huidige snelheid van een individueel auto-object is mogelijks gebaseerd op het merk (eigenschap) van die auto, alsook welke energiebron (eigenschap) die auto heeft.
Voorts kunnen objecten ook beïnvloed worden door 'de buitenwereld': naast de interne staat van ieder object, leven de objecten natuurlijk in een bepaalde context, zoals een druk kruispunt. Andere objecten op dat kruispunt kunnen invloed hebben op wat een auto-object doet.
Met andere woorden: we kunnen 'van buiten uit' vaak ook het gedrag en de interne staat van een object aanpassen. We hebben dit reeds zien gebeuren in het Pong-voorbeeld: de interne staat van ieder individueel balletjes-object is z'n positie alsook z'n richtingsvector. De buitenwereld, in dit geval onze Main methode kon echter de objecten manipuleren:
Het gedrag van een balletje konden we aanpassen met behulp van de Update en TekenOpScherm methode.
De interne staat via de eigenschappen die zichtbaar zijn aan de buitenwereld (dankzij het public keyword) .
Wanneer je later de specificaties voor een opdracht krijgt en snel wilt ontdekken wat potentiële klassen zijn, dan is het een goede tip om op zoek te gaan naar de zelfstandige naamwoorden (substantieven) in de tekst. Dit zijn meestal de objecten en/of klassen die jouw applicatie zal nodig hebben.
95% van de tijd zullen we in dit boek de voorgaande definitie van een klasse beschrijven, namelijk de blauwdruk voor de objecten die er op gebaseerd zijn. Je zou kunnen zeggen dat de klasse een fabriekje is dat objecten kan maken.
Echter, wanneer we het static keyword zullen bespreken gaan we ontdekken dat heel af en toe een klasse ook als een soort object door het leven kan gaan. Heel vreemd allemaal!
Een belangrijk concept bij OOP is het Black-box principe waarbij we de afzonderlijke objecten en hun werking als zwarte dozen gaan beschouwen.
Neem het voorbeeld van de auto: deze is in de echte wereld ontwikkeld volgens het blackbox-principe. De werking van de auto kennen tot in het kleinste detail is niet nodig om met een auto te kunnen rijden. De auto biedt een aantal zaken aan de buitenwereld aan (het stuur, pedalen, het dashboard), wat we de "interface" noemen. De interface kan je gebruiken om de interne staat van de auto uit te lezen of te manipuleren. Stel je voor dat je moest weten hoe een auto volledig werkte voor je ermee op de baan kon...
Binnen OOP wordt dit blackbox-concept abstractie en encapsulatie genoemd. Het doel van OOP is programmeurs zoveel mogelijk af te schermen van de interne werking van je klasse code. Vergelijk het met de methoden uit hoofdstuk 7: "if it works, it works" en dan hoef je niet in de code van de methode te gaan zien wat er juist gebeurt telkens je de methode wil gebruiken.
Bij encapsulatie bedoelen we dat we alle zaken die samen horen bij een auto samenvoegen tot één geheel. De motor, de banden, ieder componentje in de motor, enz. Al deze zaken encapsuleren we in één geheel. Vervolgens gaan we met de hulp van abstractie de complexiteit naar de buitenwereld toe kunnen vereenvoudigen.
Kortom: hoe minder de buitenwereld moet weten om met een object te werken, hoe beter.
Beeld je in dat je 10 lijnen code nodig had om een random getal te genereren. Niemand zou de klasse Random nog gebruiken. Dankzij de ontwikkelaar van deze klasse hoeven we maar 2 zaken te kunnen:
Een Random-object aanmaken met new/
De Next-methode aanroepen om een getal uit het object te krijgen
Wat er nu juist in die methode gebeurt boeit ons niet. It just works! Met dank aan abstractie en de kracht van OOP.
Een truukje om de belangrijkste concepten van OOP te onthouden is het acroniem A PIE, dat staat voor:
Abstractie
Polymorfisme
Inheritance, oftewel overerving
Encapsulatie
Abstractie (het vereenvoudigen van de complexe, interne structuur van een klasse) en encapsulatie (alle aspecten die in de klasse horen) hebben we net besproken. Polymorfisme zullen we pas in hoofdstuk 16 aanpakken. Inheritance komt al in hoofdstuk 13 in actie. Nog even geduld dus.
Steve Jobs, de oprichter van Apple, was een fervent fan van OOP. In een interview in 1994 voor het Rolling Stone magazine gaf hij volgende uitleg:
"Objects are like people. They’re living, breathing things that have knowledge inside them about how to do things and have memory inside them so they can remember things. And rather than interacting with them at a very low level, you interact with them at a very high level of abstraction, like we’re doing right here.
Here’s an example: If I’m your laundry object, you can give me your dirty clothes and send me a message that says, "Can you get my clothes laundered, please." I happen to know where the best laundry place in San Francisco is. And I speak English, and I have dollars in my pockets. So I go out and hail a taxicab and tell the driver to take me to this place in San Francisco. I go get your clothes laundered, I jump back in the cab, I get back here. I give you your clean clothes and say, "Here are your clean clothes."
You have no idea how I did that. You have no knowledge of the laundry place. Maybe you speak French, and you can’t even hail a taxi. You can’t pay for one, you don’t have dollars in your pocket. Yet, I knew how to do all of that. And you didn’t have to know any of it. All that complexity was hidden inside of me, and we were able to interact at a very high level of abstraction. That’s what objects are. They encapsulate complexity, and the interfaces to that complexity are high level."
Vooral die laatste zin verdient het om nog eens in vet herhaald te worden: "They encapsulate complexity, and the interfaces to that complexity are high level."
Ik zie dat je gereedsschapkist al aardig gevuld is. Zoals je misschien al gemerkt hebt aan deze sectie, zullen we vanaf nu ook geregeld minder "praktische" en eerder "filosofische" zaken tegenkomen. Maar wees gerust, je zal toch een grotere gereedsschapkist nodig hebben. Echter, net zoals een voorman niet alleen moet kunnen metsen en timmeren, maar ook stabiliteitsplannen begrijpen, zal ook jij moeten begrijpen wat de grotere ideeën achter bepaalde concepten zijn.
Zet nu je helm maar op, want in de volgende sectie gaan we wel degelijk onze handen lekker vuil maken!
In C# kunnen we geen objecten aanmaken zonder eerst een klasse te definiëren. Een klasse beschrijft de algemene eigenschappen (properties en instantievariabelen) en het gedrag (methoden) van die objecten.
De naam die je een klasse geeft moet voldoen aan de identifier regels uit hoofdstuk 2. Het is echter een goede gewoonte om klassenamen altijd met een hoofdletter te laten beginnen.
Volgende code beschrijft de klasse Auto in C#
class Auto
{
}
Binnen het codeblock dat bij deze klasse hoort zullen we verderop dan de werking via properties en methoden beschrijven.
Je kan "eender waar" een klasse aanmaken in een project, maar het is een goede gewoonte om per klasse een apart bestand te gebruiken. Dit kan op 2 manieren.
Manier 1:
In de solution Explorer, rechterklik op je project.
Kies "Add".
Kies "Class..".
Geef een goede naam voor je klasse.
Manier 2:
Klik in de menubalk bovenaan op "Project".
Kies "Add class..." .
Je zal zien dat nieuw toegevoegde klassen in Visual Studio ook nog het keyword internal voor class krijgen. Dit is een zogenaamde access modifier en leg ik zo meteen uit.
Je kan nu objecten aanmaken van de klasse die je hebt gedefinieerd. Dit kan op alle plaatsen in je code waar je in het verleden ook al variabelen kon declareren, bijvoorbeeld in een methode of je Main-methode.
Je doet dit door eerst een variabele te definiëren en vervolgens een object te instantiëren met behulp van het new keyword. De variabele heeft als datatype Auto:
Auto mijnEersteAuto = new Auto();
Auto mijnAndereAuto = new Auto();
We hebben nu twee objecten aangemaakt van het type Auto die we verderop zouden kunnen gebruiken.
Let goed op dat je dus op de juiste plekken dit alles doet:
Klassen maak je aan als aparte bestanden in je project.
Objecten creëer je in je code op de plekken waar je deze nodig hebt, bijvoorbeeld in je Main methode bij een Console-applicatie.
In het volgende hoofdstuk leg ik uit wat er allemaal gebeurt in het geheugen wanneer we een object met new aanmaken. Het is echter nu al belangrijk te beseffen dat objecten niet kunnen gemaakt worden zonder new.
De new operator vereist dat je aangeeft van welke klasse (het type) je een object wilt aanmaken, gevolgd door ronde haakjes. Bijvoorbeeld:
new Student();
Deze lijn code doet niets nuttig. We roepen hier weliswaar een constructor aan (zie verder) die het object in het geheugen zal aanmaken. Vervolgens geeft new een adres terug waar het object zich bevindt. We doen nog niets met dit adres.
Het is dit adres dat we vervolgens kunnen bewaren in een variabele die links van de toekenningsoperator (=) staat:
Student hetEersteStudentObject = new Student();
Test eens wat er gebeurt als je volgende code probeert te compileren:
Auto mijnEersteAuto = new Auto();
Auto mijnAndereAuto;
Console.WriteLine(mijnEersteAuto);
Console.WriteLine(mijnAndereAuto);
Je zal een "Use of unassigned local variable mijnAndereAuto" foutboodschap krijgen. Inderaad, je hebt nog geen object aangemaakt met new en mijnAndereAuto is dus voorlopig een lege doos (het heeft de waarde null).
Dit concept is dus fundamenteel verschillend van de klassieke valuetypes die we al kenden (int, double, enz.). Daar zal volgende code wél werken:
In hoofdstuk 2 leerden we dat er allerlei datatypes bestaan. We maakten vervolgens variabelen aan van een bepaald datatype zodat deze variabele als inhoud enkel zaken kon bevatten van dat ene datatype.
Zo leerden we toen volgende categorieën van datatypes:
Valuetypes zoals int, char en bool.
Het enum keyword liet ons toe om een nieuw datatype te maken dat maar een eindig aantal mogelijke waarden (values) kon hebben. Intern bewaarden variabelen van zo'n enum-datatype hun waarde als een int.
Arrays waren het laatste soort datatypes. Je ontdekte dat je arrays kon maken van eender welk datatype (valuetypes en enums).
Wel nu, klassen zijn niet meer dan een nieuw soort datatypes. Kortom: telkens je een klasse aanmaakt, kunnen we in dat project variabelen en arrays aanmaken met dat datatype. We noemen variabelen die een klasse als datatype hebben objecten.
Het grote verschil dat deze objecten zullen hebben is dat ze vaak veel complexer zijn dan de eerdere datatypes die we kennen:
Ze zullen meerdere "waarden" tegelijk kunnen bewaren (een int variabele kan maar één waarde tegelijkertijd in zich hebben).
Ze zullen methoden hebben die we kunnen aanroepen om het object voor ons te laten werken.
Het blijft ingewikkeld hoor. Heel boeiend om de theorie van een speer te leren, maar ik denk dat ik toch beter een paar keer met een speer naar een mammoet werp om echt te voelen wat OOP is.
Ik onthoud nu alvast "klassen zijn gewoon een nieuwe vorm van complexere datatypes" dan diegene die ik totnogtoe heb geleerd? Ok?
Correct. Er verandert dus niet veel. Enkel je variabelen worden krachtiger!
Stel dat we een klasse willen maken die ons toelaat om objecten te maken die verschillende mensen voorstellen. We willen aan iedere mens kunnen zeggen "Praat eens".
We maken een nieuwe klasse Mens en plaatsen in de klasse een methode Praat:
internal class Mens
{
public void Praat()
{
Console.WriteLine("Ik ben een mens!");
}
}
We zien twee nieuwe aspecten:
Het keyword static mag je niet voor een methode signatuur zetten (later ontdekken we wanneer dat soms wel moet) .
Voor de methode plaatsen we public : dit is een access modifier die aangeeft dat de buitenwereld deze methode op het object kan aanroepen.
Je kan nu elders objecten aanmaken en ieder object z'n methode Praat aanroepen:
Mens joske = new Mens();
Mens alfons = new Mens();
joske.Praat();
alfons.Praat();
Er zal twee maal Ik ben een mens! op het scherm verschijnen. Waarbij joske en alfons zelf verantwoordelijk hiervoor waren dat dit gebeurde.
De access modifier geeft aan hoe zichtbaar een bepaald deel van de klasse en de klasse zelf is. Wanneer je niet wilt dat "van buiten" een bepaalde methode kan aangeroepen worden, dan dien je deze als private in te stellen. Wil je dit net wel dat moet je er expliciet public of internal voor zetten.
Test in de voorgaande klasse eens wat gebeurt wanneer je public vervangt door private. Inderdaad, je zal de methode Praat niet meer op de objecten kunnen aanroepen.
Wanneer je geen access modifier voor een methode of klasse zet in C# dan zal deze als private beschouwd worden. Dit geldt voor alle zaken waar je access modifiers voor kan zetten: niets ervoor zetten wil zeggen private.
Volgende twee methoden-signaturen zijn dus identiek:
Het is een héél slechte gewoonte om géén access modifiers voor iedere methode te zetten. Maak er dus een gewoonte van dit steeds ogenblikkelijk te doen.
Test volgende klasse eens, kan je de methode VertelGeheim vanuit de Main op joske aanroepen?
internal class Mens
{
public void Praat()
{
Console.WriteLine("Ik ben een mens!");
}
private void VertelGeheim()
{
Console.WriteLine("Ik ben verliefd op Anneke");
}
}
Access modifiers hebben een volgorde van de mate waarin ze beschermen. Aan het ene uiterste heb je private en aan de andere kant public. Daartussen zitten er nog enkele andere, allemaal met hun specifieke bestaansreden.
Klassen zijn ofwel public oftewel internal. Indien je niets voor de klasse zet dan is deze internal. Concreet wil dit zeggen dat een internal klasse enkel binnen het huidige project (de assembly) kunt gebruiken.
Onderdelen (hoofdzakelijk methoden en datavelden) in een klasse kunnen volgende modifiers hebben:
private: het meest beschermdend. Enkel zichtbaar in de klasse zelf. Dit is de standaardwaarde als je geen access modifier expliciet schrijft.
protected: enkel zichtbaar voor overgeërfde klassen (zie hoofdstuk 16).
public : het meest open. Iedereen kan hier aan...en dat raden we ten stelligste af.
Er zijn er nog enkele andere (protected internal, private internal en file), maar die bespreken we niet in dit boek.
De code binnenin een klasse kan overal aan binnen de klasse zelf. Stel dat je dus een erg complexe publieke methode hebt, en je wil deze opsplitsen in meerdere delen, dan ga je die andere delen private maken. Dit voorkomt dat programmeurs die je klasse later gebruiken, stukken code aanroepen die helemaal niet bedoeld zijn om rechtstreeks aan te roepen.
Volgende voorbeeld toont hoe je binnenin een klasse andere zaken van de klasse kunt aanroepen: we roepen in de methode Praat de methode VertelGeheim aan. Dit kan want private geldt enkel voor de buitenwereld van de klasse, maar dus niet voor de code binnen de Praat-methode zelf.
internal class Mens
{
public void Praat()
{
Console.WriteLine("Ik ben een mens!");
VertelGeheim();
}
private void VertelGeheim()
{
Console.WriteLine("Ik ben verliefd op Anneke");
}
}
Als we nu elders een object laten praten als volgt:
Mens rachid = new Mens();
rachid.Praat();
Dan zal de uitvoer worden:
Ik ben een mens!
Ik ben verliefd op Anneke
Met behulp van de dot-operator (.) kunnen we aan alle informatie die ons object aanbiedt aan de buitenwereld. Ook dit zag je reeds toen je een Random-object hadden: we konden maar een handvol zaken aanroepen op zo'n object, waaronder de Next methode.
Het is natuurlijk een beetje vreemd dat nu al onze objecten zeggen dat ze verliefd zijn op Anneke. Dit is niet het smurfendorp met maar 1 meisje! Dit gaan we verderop oplossen. Stay tuned!
Voorlopig doen alle objecten van het type Mens hetzelfde. Ze kunnen praten en zeggen hetzelfde.
We weten echter dat objecten ook een interne staat hebben die per object individueel is (we zagen dit reeds toen we balletjes over het scherm lieten botsen: ieder balletje onthield z'n eigen richtingsvector en positie). Dit kunnen we dankzij instantievariabelen (ook wel datavelden of datafields genoemd) oplossen. Dit zullen variabelen zijn waarin zaken kunnen bewaard worden die verschillen per object.
Stel je voor dat we onze mensen een geboortejaar willen geven. Ieder object zal zelf in een instantievariabele bijhouden wanneer ze geboren zijn (het vertellen van geheimen zullen we verderop behandelen):
internal class Mens
{
private int geboorteJaar = 1970; //instantievariabele
public void Praat()
{
Console.WriteLine("Ik ben een mens! ");
Console.WriteLine($"Ik ben geboren in {geboorteJaar}.");
}
}
Enkele belangrijke concepten:
De instantievariabele geboorteJaar zetten we private: we willen niet dat de buitenwereld het geboortejaar van een object kan aanpassen. Beeld je in dat dat in de echte wereld ook kon. Dan zou je naar je kameraad kunnen roepen "Hey Adil, jouw geboortejaar is nu 1899! Ha!" Waarop Adil vloekend verandert in een steenoud mannetje.
We geven de variabele een beginwaarde 1970. Alle objecten zullen dus standaard in het jaar 1970 geboren zijn wanneer we deze met new aanmaken.
We kunnen de inhoud van de instantievariabelen lezen en veranderen vanuit andere delen in de code. Zo gebruiken we geboorteJaar in de tweede lijn van de Praat methode. Als je die methode nu zou aanroepen dan zou het geboortejaar van het object dat je aanroept mee op het scherm verschijnen.
Ik moet ook dringend enkele extra niet-officiële identifier regels in het leven roepen:
Klassenamen en methoden in klassen beginnen altijd met een hoofdletter.
Alles dat public is in een klasse begint ook met een hoofdletter.
Alles dat private is begint met een kleine letter (of liggend streepje), tenzij het om een methode gaat, die begint altijd met een hoofdletter.
Dit zijn geen officiële regels, maar afspraken die veel programmeurs onderling hebben gemaakt. Het maakt de code leesbaarder.
Wat?! Ik ben hier niet voor jou? Omdat je geen goto hebt gebruikt?! Flink hoor. Maar daarvoor ben ik hier niet. Ik zag je wel denken: "Als ik nu die instantievariabele ook eens public maak." Niet doen. Simpel! Instantievariabele mogen NOOIT public gezet worden.
De C# standaard laat dit weliswaar toe, maar dit is één van de slechtste programmeerdingen die je kan doen. Wil je toch de interne staat van een object kunnen aanpassen dan gaan we dat via properties en methoden kunnen doen, wat we zo meteen gaan uitleggen. Zie dat ik hier niet te vaak tussenbeide moet komen. Dank!
Ok, we zullen maar luisteren naar meneer de agent. Stel nu dat we een verjongingsstraal hebben. Hiermee kunnen we het geboortejaar van de mensen steeds met 1 jaar kunnen verhogen. We maken ze met andere woorden telkens een jaartje jonger!
internal class Mens
{
private int geboorteJaar = 1970;
public void Praat()
{
Console.WriteLine("Ik ben een mens! ");
Console.WriteLine($"Ik ben geboren in {geboorteJaar}.");
}
public void StartVerjongingskuur()
{
Console.WriteLine("Jeuj. Ik word jonger!");
geboorteJaar++;
}
}
Zoals al gezegd: Ieder object zal z'n eigen geboortejaar hebben.
Die laatste opmerking is een kernconcept van OOP: ieder object heeft z'n eigen interne staat die kan aangepast worden individueel van de andere objecten van hetzelfde type. We zullen dit testen in volgende voorbeeld waarin we 2 objecten maken en enkel 1 ervan verjongen. Kijk wat er gebeurt:
Mens elvis = new Mens();
Mens bono = new Mens();
elvis.StartVerjongingskuur();
elvis.Praat();
bono.Praat();
Als je voorgaande code zou uitvoeren zal je zien dat het geboortejaar van Elvis verhoogd en niet die van Bono wanneer we StartVerjongingskuur aanroepen. Zoals het hoort!
De uitvoer zal zijn:
Jeuj. Ik word jonger!
Ik ben een mens!
Ik ben geboren in 1971.
Ik ben een mens!
Ik ben geboren in 1970.
"Ja maar, nu pas je toch het geboortejaar van buiten aan via een methode, ook al gaf je aan dat dit niet de bedoeling was want dan zou je Adil ogenblikkelijk erg jong kunnen maken."
Correct. Maar dat was dus maar een voorbeeld. De hoofdreden dat we instantievariabelen niet zomaar public mogen maken is om te voorkomen dat de buitenwereld instantievariabelen waarden geeft die de werking van de klasse zouden stuk maken. Stel je voor dat je dit kon doen: adil.geboortejaar = -12000;
Dit kan nefaste gevolgen hebben voor de klasse.
Daarom gaan we de toegang tot instantievariabelen als het ware controleren door deze enkel via properties en methoden toe te laten. We zouden dan bijvoorbeeld het volgende kunnen doen:
internal class Mens
{
private int geboorteJaar = 1970;
public void VeranderGeboortejaar(int geboorteJaarIn)
{
if(geboorteJaarIn >= 1900)
geboorteJaar = geboorteJaarIn;
}
//...
Mooi he. Zo voorkomen we dus dat de buitenwereld illegale waarden aan een variabele kan geven. In dit voorbeeld kunnen mensen dus niet voor het jaar 1900 geboren zijn. Objecten zijn verantwoordelijk voor zichzelf en moeten zichzelf dus ook beschermen zodat de buitenwereld niets met hen doet dat hun eigen werking om zeep helpt.
We kunnen nu het probleem oplossen dat al onze mensen verliefd zijn op Anneke. Volgende code toont dit:
internal class Mens
{
private string lief = "niemand";
public void VeranderLief(string nieuwLief)
{
lief = nieuwLief;
}
public void Praat()
{
Console.WriteLine("Ik ben een mens!");
VertelGeheim();
}
private void VertelGeheim()
{
if( lief != "niemand")
Console.WriteLine($"Ik ben verliefd op {lief}.");
else
Console.WriteLine("Ik ben op niemand verliefd.");
}
}
Nu kunnen we dus "Temptation Island - de OOP editie" beginnen:
Mens deelnemer1 = new Mens();
Mens deelnemer2 = new Mens();
deelnemer1.Praat();
deelnemer2.Praat();
deelnemer2.VeranderLief("Phoebe");
deelnemer1.Praat();
deelnemer2.Praat();
deelnemer1.VeranderLief("Camilla");
deelnemer1.Praat();
deelnemer2.Praat();
De uitvoer van voorgaande code zal zijn:
Ik ben een mens!
Ik ben op niemand verliefd.
Ik ben een mens!
Ik ben op niemand verliefd.
Ik ben een mens!
Ik ben op niemand verliefd.
Ik ben een mens!
Ik ben verliefd op Phoebe.
Ik ben een mens!
Ik ben verliefd op Camilla.
Ik ben een mens!
Ik ben verliefd op Phoebe.
Veel beginnende programmeurs maken fouten op het correct kunnen onderscheiden wat de klassen en wat de objecten in hun opgave juist zijn. Het is altijd belangrijk te begrijpen dat een klasse weliswaar beschrijft hoe alle objecten van dat type werken, maar op zich gaat die beschrijving steeds over 1 object uit de verzameling. Say what now?!
Als je een klasse Student hebt, dan zal deze eigenschappen hebben zoals Punten, Naam en Geboortejaar. Als je een klasse Studenten daarentegen hebt, dan is dit vermoedelijk een klasse die beschrijft hoe een groep studenten moet werken in je applicatie. Mogelijk zal je dan properties hebben zoals KlasNaam, AantalAfwezigen, enz. Kortom, eigenschappen over de groep, niet over 1 student.
Een andere veelgemaakte fout is klassen te schrijven die maar exact één object kan en moet creëren. Dit soort klasse noemt een singleton. Stel je voor dat je een spel maakt waarin verschillende levels zijn. Een logische keuze zou dan zijn om een klasse Level te maken (niét Levels) die properties heeft zoals MoeilijkheidsGraad, HeeftGeheimeGrotten, AantalVijanden, enz.
Vervolgens kunnen we dan instanties maken: 1 object stelt 1 level in het spel voor. De speler kan dan van level naar level gaan en de code start dan bijvoorbeeld telkens de BeginLevel methode:
Level level1 = new Level();
level1.BeginLevel();
Wat dus niet mag zijn klassen met namen zoals level1, level2, enz. Vermoedelijk hebben deze klasse 90% gelijkaardige code en is er dus een probleem met wat we de architectuur van je code noemen. Of duidelijker: je snapt niet wat het verschil is tussen klassen en objecten!
Objecten met namen zoals level1 en level2 zijn wél dus toegestaan, daar ze dan vermoedelijk allemaal van het type Level zijn. Maar opgelet: als je variabelen hebt die genummerd zijn (bv. bal1, bal2, enz.) dan is de kans groot dat je eigenlijk een array van objecten nodig hebt (wat ik in hoofdstuk 12 zal uitleggen).
We zagen zonet dat instantievariabelen nooit public mogen zijn om te voorkomen dat de buitenwereld onze objecten 'vult' met slechte zaken. Het voorbeeld waarbij we vervolgens een methode StartVerjongingskuur gebruikten om op gecontroleerde manier toch aan de interne staat van objecten te komen is één oplossing, maar een nogal oldschool oplossing.
Deze manier van werken - methoden gebruiken om instantievariabelen aan te passen of uit te lezen - is wat voorbij gestreefd binnen C#. Onze programmeertaal heeft namelijk het concept properties (eigenschappen) in het leven geroepen die toelaten op een eenvoudigere manier aan de interne staat van objecten te geraken.
Properties (eigenschappen) zijn de C# manier om objecten hun interne staat in en uit te lezen. Ze zorgen voor een gecontroleerde toegang tot de interne structuur van je objecten.
In het Star Wars universum heb je goede oude "Darth Vader". Hij behoort tot de mysterieuze klasse van de Sith Lords. Deze Lords lopen met een geheim rond: ze hebben een Sithnaam. Deze naam mogen de Lords enkel bekend maken aan andere Sith Lords. Voorts heeft een Sith Lord ook een hoeveelheid energie (The Force) waarmee hij kattekwaad kan uithalen. Deze energie kan nooit onder nul gezet worden.
We kunnen voorgaande als volgt schrijven:
internal class SithLord
{
private int energie;
private string sithName;
}
Het is uit den boze dat we eenvoudige instantievariabelen (energie en name) public maken. Zouden we dat wel doen dan kunnen externe objecten deze geheime informatie uitlezen!
SithLord palpatine = new SithLord();
Console.WriteLine(palpatine.sithName); //zal niet compileren!
We willen echter wel van buiten uit het energie-level van een sithLord kunnen instellen. Maar ook hier hetzelfde probleem: wat als we de energie-level op -1000 instellen? Terwijl energie nooit onder 0 mag gaan.
Full properties: deze stijl van properties verplicht ons véél code te schrijven, maar we hebben ook volledige controle over wat er gebeurt.
Auto-properties: deze zijn exact het omgekeerde van full properties. Je moet niet veel code schrijven, maar je hebt ook weinig (eigenlijk géén) controle over wat er gebeurt.
Ik behandel eerst full properties, omdat auto-properties een soort afgeleide van full properties zijn. Bepaalde aspecten van full properties worden bij auto-properties achter de scherm verstopt zodat jij als programmeur er geen last van hebt.
1
In één van de volgende versies van C# (normaal versie 11) zal er nog een derde type verschijnen: semi-auto properties. Een propertytype dat zich tussen beide bestaande types zal bevinden. De details en exacte gebruik ervan worden nog besproken op github.com door de ontwikkelaars, dus het is nog te vroeg om deze al op te nemen in dit boek.
Properties herken je aan de get en set keywords in een klasse. Een property is een beschrijving van wat er moet gebeuren indien je informatie uit (get) een object wilt halen of informatie in (set) een object wilt plaatsen.
In volgende voorbeeld maken we een property, genaamd Energie aan. Deze doet niets anders dan rechtstreeks toegang tot de instantievariabele energie te geven:
internal class SithLord
{
private int energie;
public int Energie
{
get
{
return energie;
}
set
{
energie = value;
}
}
}
Dankzij voorgaande code kunnen we nu buiten het object de property Energie gebruiken als volgt:
SithLord Vader = new SithLord();
Vader.Energie = 20; //set
Console.WriteLine($"Vaders energie is {Vader.Energie}"); //get
De eerste lijn van een full property beschrijft de naam (identifier) en datatype van de property: public int Energie
Een property is altijd public daar dit de essentie van een property net is "de buitenwereld gecontroleerde toegang tot de interne staat van een object geven".
Vervolgens zeggen we wat voor datatype de property moet zijn en geven we het een naam die moet voldoen aan de identifier regels van weleer. Voor de buitenwereld zal een property zich gedragen als een gewone variabele, met de naam Energie van het type int.
Indien je de property gaat gebruiken om een instantievariabele naar buiten beschikbaar te stellen, dan is het een goede gewoonte om dezelfde naam als dat veld te nemen maar nu met een hoofdletter (dus Energie i.p.v. energie).
Indien je wenst dat de property data naar buiten kan sturen, dan schrijven we de get-code. Binnen de accolades van de get schrijven we wat er naar buiten moet gestuurd worden.
get
{
return energie;
}
Dit werkt dus identiek aan een methode met een returntype. Het element dat je met return teruggeeft in de get code moet uiteraard van hetzelfde type zijn als waarmee je de property hebt gedefinieerd (int in dit geval).
We kunnen nu van buitenaf toch de waarde van energie uitlezen via de property en het get-gedeelte, bijvoorbeeld int uitgelezen = palpatine.Energie;.
We mogen eender wat doen in het get-gedeelte (net zoals bij methoden) zolang er finaal maar iets uitgestuurd wordt m.b.v. return. Ik zal hier verderop meer over vertellen, want soms is het handig om getters te schrijven die de data transformeren voor ze uitgestuurd wordt.
In het set-gedeelte schrijven we de code die we moeten hanteren indien men van buiten een waarde aan de property wenst te geven om zo een instantievariabele aan te passen.
set
{
energie = value;
}
De waarde die we van buiten krijgen (als een parameter zeg maar) zal altijd in een lokale variabele value worden bewaard binnenin de set-code. Deze zal van het type van de property zijn.
Deze value parameter is een geserveerd keyword van de set syntax en kan je niet hernoemen of voor iets anders gebruiken.
Vervolgens kunnen we value toewijzen aan de interne variabele indien gewenst: energie = value;. Uiteraard kunnen we die toewijzing dus ook gecontroleerd laten gebeuren, wat ik zo meteen uitleg.
We kunnen vanaf nu van buitenaf waarden toewijzen aan de property en zo energie toch bereiken: palpatine.Energie = 50;.
Je bent niet verplicht om een property te maken wiens naam overeen komt met een bestaande instantievariabele (maar dit wordt wel aangeraden).
Dit mag dus ook:
internal class Auto
{
private int benzinePeil;
public int FuelLevel
{
get { return benzinePeil; }
set { benzinePeil = value; }
}
}
Visual Studio heeft een ingebouwde snippet om snel een full property, inclusief een bijhorende private instantievariabele, te schrijven. Typ "propfull" gevolgd door twee maal op de tab-toets te duwen.
De full property Energie heeft nog steeds het probleem dat we negatieve waarden kunnen toewijzen (via de set) die dan vervolgens zal toegewezen worden aan energie.
Properties hebben echter de mogelijkheid om op te treden als wachters van en naar de interne staat van objecten.
We kunnen in de set code extra controles inbouwen. Aangezien de variabele value de waarde krijgt die we extern aan de property toewijzen, kunnen we deze controleren en zo nodig de toewijzing voorkomen. Volgende voorbeeld zal enkel de waarde toewijzen indien deze groter of gelijk aan 0 is:
public int Energie
{
get
{
return energie;
}
set
{
if(value >= 0)
energie = value;
}
}
Volgende lijn zal dus geen effect hebben:
palpatine.Energie = -1;
We mogen de code binnen set en get zo complex maken als we zelf willen.
Probeer wel steeds de OOP-principes te hanteren wanneer je met properties werkt: in de get en set van een property mogen enkel die dingen gebeuren die de verantwoordelijkheid van de property zelf zijn. Je gaat dus bijvoorbeeld niet controleren of een andere property geen illegale waarden krijgt, daar is die andere property voor verantwoordelijk.
Dit soort properties zijn handig indien je informatie naar een object wenst te sturen dat niet mag of moet uitgelezen kunnen worden. Het meest typische voorbeeld is een property Pincode van een klasse BankRekening.
public int Energie
{
set
{
if(value >= 0)
energie = value;
}
}
We kunnen dus enkel energie een waarde geven, maar niet van buiten uitlezen.
Letterlijk het omgekeerde van een write-only property. Deze gebruik je vaak wanneer je informatie uit een object wil kunnen uitlezen uit een instantievariabele dat NIET door de buitenwereld mag aangepast worden.
public int Energie
{
get
{
return energie;
}
}
We kunnen enkel energie van buiten uitlezen, maar niet aanpassen.
Het readonly keyword heeft andere doelen en wordt NIET gebruikt in C# om een readonly property te maken.
Soms gebeurt het dat we van enkel voor de buitenwereld de property read-only willen maken. We willen in de klasse zelf nog steeds controleren dat er geen illegale waarden aan private instantievariabelen worden gegeven. Op dat moment definiëren we een read-only property met een private setter:
public int Energie
{
get
{
return energie;
}
private set
{
if(value >= 0)
energie = value;
}
}
Van buiten zal enkel code werken die de get van deze property aanroept, bijvoorbeeld:
Console.WriteLine(palpatine.Energie);
Code die de set van buiten nodig heeft (bv. palpatine.Energie = 65;) zal een fout geven ongeacht of deze geldig is of niet.
Het is een goede gewoonte om altijd via de properties je interne variabele aan te passen en niet rechtstreeks via de instantievariabele zelf. Dit is zo'n nuttige tip dat we op de volgende pagina de voorman hier ook nog even over aan het woord gaan laten.
Lukt het een beetje? Properties zijn in het begin wat overweldigend, maar geloof me: ze zijn zowat dé belangrijkste bewoners in de .NET/C# wereld.
Nu even goed opletten: indien we in het object de instantievariabelen willen aanpassen dan is het een goede gewoonte om ook dat via de property te doen (ook al zit je in het object zelf en heb dus eigenlijk de property niet nodig). Zo zorgen we ervoor dat de bestaande controle in de property niet wordt omzeilt. Kijk zelf naar volgende slechte codevoorbeeld:
internal class SithLord
{
private int energie;
private string sithName;
public void ResetLord(int resetWaarde)
{
energie = resetWaarde;
}
public int Energie
{
get
{
return energie;
}
private set
{
if(value >= 0)
energie = value;
}
}
}
De nieuw toegevoegde methode ResetLord willen we gebruiken om de lord z'n energie terug te verlagen. Als we deze methode met een negatieve waarden aanroepen zullen we alnsog energie op een verkeerde waarde instellen. Nochtans is dit een illegale waarde volgens de set-code van de property.
We moeten dus in de methode ook expliciet via de property gaan om bugs te voorkomen en dus gaan we in ResetLordschrijven naar de property Energie én niet rechtstreeks naar de instantievariabele energie:
public void ResetLord(int resetWaarde)
{
Energie = resetWaarde; // Energie i.p.v. energie
}
Je bent uiteraard niet verplicht om voor iedere instantievariabele een bijhorende property te schrijven. Omgekeerd ook: mogelijk wil je extra properties hebben voor data die je 'on-the-fly' kan genereren dat niet noodzakelijk uit een instantievariabele komt. Stel dat we volgende klasse hebben:
internal class Persoon
{
public string Voornaam {get;set;}
public string Achternaam {get;set;}
}
We willen echter ook soms de volledige naam of emailadres krijgen, beide gebaseerd op de inhoud van de instantievariabelen voornaam en achternaam. Via een read-only property die transformeert kan dit:
internal class Persoon
{
public string Voornaam {get;set;}
public string Achternaam {get;set;}
public string VolledigeNaam
{
get
{
return $"{Voornaam} {Achternaam}";
}
}
public string Email
{
get
{
return $"{Voornaam}@ziescherp.be";
}
}
}
Methode of property?
Een veel gestelde vraag bij beginnende OOP-ontwikkelaars is: "Moet dit in een property of in een methode geplaatst worden?"
De regels zijn niet in steen gebeiteld, maar ruwweg kan je stellen dat:
Betreft het een actie of gedrag: iets dat het object moet doen (tekst tonen, iets berekenen of aanpassen, enz.) dan plaats je het in een methode.
Betreft het een eigenschap van het object, dan gebruik je een property indien het om data gaat die snel verkregen of berekend kan worden. Gaat het om data die zwaardere en/of langere berekeningen vereist dan is een methode nog steeds aangeraden.
{% hint style='info' %}
Nieuw in C# 14: Het field keyword
Vroeger was je verplicht om full properties te schrijven als je validatie wou toevoegen. Sinds C# 14 kan dit veel korter met het field keyword.
Lees er meer over in de appendix
Automatische eigenschappen (automatic properties, auto-implemented properties, soms ook autoprops genoemd) laten toe om snel properties te schrijven zonder dat we de achterliggende instantievariabele moeten beschrijven.
Een auto-property herken je aan het feit dat ze een pak korter zijn qua code, omdat er veel meer (onzichtbaar) achter de schermen wordt opgelost:
public string Voornaam { get; set; }
Heel vaak wil je heel eenvoudige variabelen aan de buitenwereld van je klasse beschikbaar stellen. Omdat je instantievariabelen echter niet public mag maken, moeten we dus properties gebruiken die niets anders doen dan als doorgeefluik fungeren. auto-properties doen dit voor ons: het zijn vereenvoudigde full properties waarbij de achterliggende instantievariabele onzichtbaar voor ons is. Je kan echter bij auto-properties ook geen verdere controle op de in-of uitvoer doen.
Zo kan je eenvoudig de volgende klasse Persoon herschrijven met behulp van auto-properties. De originele klasse mét full properties:
internal class Person
{
private string voornaam;
public string Voornaam
{
get { return voornaam; }
set { voornaam = value; }
}
private int geboorteJaar;
public int Geboortejaar
{
get { return geboorteJaar; }
set { geboorteJaar = value; }
}
}
De herschreven klasse met auto-properties wordt:
internal class Person
{
public string Voornaam { get; set; }
public int Geboortejaar { get; set; }
}
Beide klassen hebben exact dezelfde functionaliteit, echter is de laatste klasse aanzienlijk korter en dus eenvoudiger om te lezen. De private instantievariabelen zijn niét meer aanwezig. C# gaat die voor z'n rekening nemen. Alle code zal dus via de properties moeten gaan.
Het is belangrijk te benadrukken dat de achterliggende instantievariabele onzichtbaar is in auto-properties en onmogelijk kan gebruikt worden. Alles gebeurt via de auto-property, altijd. Je hebt dus enkel een soort publieke variabele. Maar wel eentje die conform de afspraken is ("maak geen instantievariabelen publiek!"). Gebruik dit dus enkel wanneer je 100% zeker bent dat de auto-property geen waarden kan krijgen die de interne werking van je klasse kan verstoren.
Vaak zal je nieuwe klassen eerst met auto-properties beschrijven. Naarmate de specificaties dan vereisen dat er bepaalde controles of transformaties moeten gebeuren, zal je stelselmatig auto-properties vervangen door full properties.
Dit kan trouwens automatisch in VS: selecteer de autoprop in kwestie en klik dan vooraan op de schroevendraaier en kies "Convert to full property".
Opgelet: Merk op dat de syntax die VS gebruikt om een full property te schrijven anders is dan wat ik hier uitleg. Wanneer je VS laat doen krijg je een oplossing met allerlei => tekens. Dit is heet Expression Bodied Member syntax (EBM). Ik behandel deze nieuwere C# syntax in de appendix.
Wil je toch je autoproperties omzetten naar full properties volgens de "klassieke" syntax die we hier uitleggen, ga dan naar je instellingen.
Tools->Options->Text Editor->C#->Code Style->General->Expression Preferences. Zet daar de items Use expression body for accessors en Use expression body for properties op "Never".
Merk op dat je auto-properties dus enkel kan gebruiken indien er geen extra logica in de property (bij de set of get) aanwezig moet zijn.
Stel dat je bij de setter van geboorteJaar wil controleren op een negatieve waarde, dan zal je dit zoals voorheen moeten schrijven en kan dit niet met een automatic property:
set
{
if( value > 0)
geboorteJaar = value;
}
Voorgaande property kan dus NIET herschreven worden met een automatic property. auto-properties zijn vooral handig om snel klassen in elkaar te knutselen, zonder je zorgen te moeten maken om andere vereisten. Vaak zal een klasse in het begin met auto-properties gevuld worden. Naarmate je project vordert zullen die auto-properties meer en meer omgezet worden in full properties.
Je kan auto-properties ook gebruiken om bijvoorbeeld een read-only property met private setter te definiëren. Als volgt:
public string Voornaam { get; private set; }
Een andere manier die ook kan wanneer we enkel een read-only property nodig hebben, is als volgt:
public string Voornaam { get; } = "Tim";
Hierbij zijn we dan wel verplicht om ogenblikkelijk deze property een beginwaarde te geven, daar we deze op geen enkele andere manier nog kunnen aanpassen.
Als je in Visual Studio in je code prop typt en vervolgens twee keer de tabtoets indrukt dan verschijnt al de nodige code voor een automatic property.
Via propg gevolgd door twee maal de tabtoets krijg je een auto-property met private setter.
Doe die zwembroek maar weer aan! We gaan nog eens zwemmen.
Zoals je vermoedelijk al doorhebt hebben we met properties en methoden nog maar een tipje van de klasse-ijsberg besproken. Vreemde dingen zoals constructors, static methoden, overerving en arrays van objecten staan ons nog allemaal te wachten.
Om je toch al een voorsmaakje van de kracht van klassen en objecten te geven, gaan we eens kijken naar één van de vele klassen die je tot je beschikking hebt in C#. Je hebt al leren werken met de Random klasse. Maar ook al met enkele speciale static klassen zoals de Math- en Console-bibliotheek. Waarom zijn dit static klassen? Wel, je kan ze gebruiken zonder dat je er objecten van moet aanmaken.
Nog zo'n handige ingebouwde klasse is de DateTime klasse1. Je raadt het nooit ... een klasse die toelaat om de tijd en datum als een object voor te stellen. De DateTime klasse is de ideale manier om te leren werken met objecten.
1
Technisch gezien is DateTime een struct, niet een class. Dit onderscheid is in dit handboek niet relevant. Meer informatie over struct vind je in de appendix terug.
Er zijn 2 manieren om DateTime objecten aan te maken:
DateTime huidigeTijd = DateTime.Now;
DateTime specialeDag = new DateTime(2017,4,21);
Lijn 1: Door aan de klasse de huidige datum en tijd te vragen via DateTime.Now.
Lijn 2: Door manueel de datum en tijd in te stellen met het new keyword en de klasse-constructor (een concept dat we in hoofdstuk 11 uit de doeken gaan doen)
De constructor van een klasse laat toe om bij het maken van een nieuw object, beginwaarden voor bepaalde instantievariabelen of properties mee te geven. De DateTime klasse heeft meerdere constructors gedefiniëerd zodat je bijvoorbeeld een object kan aanmaken dat bij de start reeds de geboortedatum van de auteur bevat:
DateTime verjaardag = new DateTime(1981, 3, 18); //jaar, maand, dag
Ook is er een constructor om startdatum én -tijd mee te geven bij de objectcreatie:
Van zodra je een DateTime object hebt gemaakt zijn er tal van nuttige methoden die je er op kan aanroepen. Visual Studio is zo vriendelijk om dit te visualiseren wanneer we de dot-operator typen achter een object:
Deze methoden kan je gebruiken om een bepaalde aantal dagen, uren, minuten op te tellen bij de huidige tijd en datum van een object. De ingebouwde methoden noemen allemaal AddX, waar bij X dan vervangen wordt door het soort element dat je wilt toevoegen: AddDays, AddHours, AddMilliseconds, AddMinutes, AddMonths, AddSeconds, AddTicks2, AddYears.
2
Een tick is 100 nanoseconden, oftewel 1 tien miljoenste van een seconden. Dat lijkt een erg klein getal (wat het voor ons ook is) maar voor computers is dit het soort tijdsintervals waar ze mee werken.
Het object zal voor ons de "berekening" hiervan doen en vervolgens een nieuw DateTime object teruggeven dat je moet bewaren wil je er iets mee doen.
In volgende voorbeeld wil ik ontdekken wanneer de wittebroodsweken van m'n huwelijk eindigen (pakweg 5 weken na de trouwdag).
Dit hoofdstuk heeft al aardig wat woorden verspild aan properties, en uiteraard heeft ook de DateTime klasse een hele hoop interessante properties die toelaten om de interne staat van een DateTime object te bewerken of uit te lezen.
Enkele nuttige properties van DateTime zijn: Date, Day, DayOfWeek, DayOfYear, Hour, Millisecond, Minute, Month, Second, Ticks, TimeOfDay, Today, UtcNow, Year.
Alle properties van DateTime zijn read-only en hebben dus een private setter die we niet kunnen gebruiken.
Een voorbeeld:
Console.WriteLine($"Einde in maand nr: {eindeWitteBroodsweken.Month}.");
Console.WriteLine($"Dat is een {eindeWitteBroodsweken.DayOfWeek}.");
Dit geeft op het scherm:
Je wittebroodsweken eindigen in maand nummer: 5.
Dat is een Friday.
Sommige methoden zijn static dat wil zeggen dat je ze enkel rechtstreeks op de klasse kunt aanroepen. Vaak zijn deze methoden hulpmethoden waar de individuele objecten niets aan hebben. We hebben dit reeds gebruikt bij de Math en Console-klassen.
We behandelen static uitgebreid verderop in het boek.
Parsen laat toe dat je strings omzet naar een DateTime object. Dit is handig als je bijvoorbeeld de gebruiker via Console.ReadLine() tijd en datum wilt laten invoeren in de Belgische notatie:
Indien je nu dit programma'tje zou uitvoeren en als gebruiker "8/11/2016" zou intypen, dan zal deze datum geparsed worden en in het object datumVerwerkt komen.
Zoals je ziet roepen we Parse aan op DateTime en dus niet op een specifiek object. Dat was ook zo reeds bijvoorbeeld bij int.Parse wat dus doet vermoeden dat zelfs het int datatype eigenlijk een klasse is!
Je kan DateTime objecten ook van elkaar aftrekken (optellen gaat niet!). Het resultaat van deze bewerking geeft echter niet een DateTime object terug, maar een TimeSpan object. Dit is nieuwe object van het type TimeSpan (wat dus een andere klasse is) dat aangeeft hoe groot het verschil is tussen de 2 DateTime objecten kunnen we als volgt gebruiken:
DateTime vandaag = DateTime.Today;
DateTime geboorteDochter = new DateTime(2009,6,17);
TimeSpan verschil = vandaag - geboorteDochter;
Console.WriteLine($"{verschil.TotalDays} dagen sinds geboorte dochter.");
Je zal de DateTime klasse in véél van je projecten kunnen gebruiken waar je iets met tijd, tijdsverschillen of datums wilt doen. We hebben de klasse in deze sectie echter geen eer aangedaan. De klasse is veel krachtiger dan ik hier doe uitschijnen. Het is een goede gewoonte als beginnende programmeur om steeds de documentatie van nieuwe klassen er op na te slaan.3
3
Wanneer je in je browser zoekt op "C#" gevolgd door de naam van de klasse dan zal je zo goed als zeker als eerste hit de officiële .NET documentatie krijgen op docs.microsoft.com.
Gaat het nog?! Dit was een stevig hoofdstuk he. We hebben zo maar eventjes 4 heel grote fasen doorlopen:
Eerst keken we hoe OOP ons kan helpen in een real-life voorbeeld, Pong. We schreven code die hier en daar herkenbaar was, maar op andere plaatsen totaal nieuw was.
Vervolgens namen we de mammoet bij de horens en bekeken we de theorie van OO, die ons vooral verwarde.
Gelukkig gingen we dan ogenblikkelijk naar de praktijk over en zagen we dat methoden en properties de kern van iedere klasse blijkt te zijn.
Als afsluiter gooiden we dan de DateTime klasse open om een voorproefje te krijgen van hoe krachtig een goedgeschreven klasse kan zijn.
Voor je verder gaat raad ik je aan om dit alles goed te laten bezinken én maximaal de komende oefeningen te maken. Het zal de beste manier zijn om de ietwat bizarre wereld van OOP snel eigen te maken.
Dit hoofdstuk gaat een beetje overal over. In de eerste, en belangrijkste, plaats gaan we eens kijken wat er allemaal achter de schermen gebeurt wanneer we met objecten programmeren. Je zal namelijk ontdekken dat er een fundamenteel verschil is in het werken met bijvoorbeeld een object van het type Student tegenover werken met een eenvoudige variabele van het type int.
Vervolgens gaan we kort de keywords using en namespace bekijken. Die tweede heb je al bij iedere project bovenaan je code zien staan, nu wordt het tijd om toe te lichten waarom dat is.
Finaal lijkt het ons een goed moment om je robuustere, minder crashende, code te leren schrijven. Exception handling, de naam zegt het al, gaat ons helpen om die typische uitzonderingen (zoals deling door 0) in algoritmes op een elegante manier op te vangen (en dus niet door een nest van if structuren te schrijven in de hoop dat je iedere mogelijke uitzondering kunt opvangen).
In hoofdstuk 8 deed ik reeds uit de doeken dat variabelen op 2 manieren in het geheugen kunnen leven:
Value types: waren variabelen wiens waarde rechtstreeks op de geheugenplek stonden waar de variabele naar verwees. Dit gold voor alle bestaande, ingebakken datatypes zoals int, bool, char enz. alsook voor enum types.
Reference types: deze variabelen bevatten als inhoud een geheugenadres naar een andere plek in het geheugen waar de effectieve waarde van deze variabele stond. We zagen dat dit voorlopig enkel bij arrays gebeurde.
Ook objecten zijn reference types. Hoofdstuk 8 liet uitschijnen dat vooral value type variabelen veelvuldig in programma's voorkwamen. Wel je zal nu ontdekken dat reference types véél meer voorkomen: simpelweg omdat alles in C# een object is (en dus ook arrays van objecten én zelfs valuetypes, enz.).
Om goed te begrijpen waarom reference types zo belangrijk zijn, zullen we nu eerst eens inzoomen op hoe het geheugen van een C# applicatie werkt.
In hoofdstuk 8 toonde ik ook hoe alle variabelen in één grote "wolk geheugen" zitten, ongeacht of ze nu value types of reference types zijn. Dat klopt niet helemaal. Eigenlijk zijn er 2 soorten geheugens die een C# applicatie tot z'n beschikking heeft.
Wanneer een C# applicatie wordt uitgevoerd krijgt het twee soorten geheugen toegewezen dat het 'naar hartelust' kan gebruiken, namelijk:
Het kleine, maar snelle stack geheugen.
Het grote, maar tragere heap geheugen.
Afhankelijk van het soort variabele wordt ofwel de stack, ofwel de heap gebruikt. Het is uitermate belangrijk dat je weet in welk geheugen de variabele zal bewaard worden! Je hebt hier geen controle over, maar het beïnvloedt wel de manier waarop je code zal werken.
Volgende tabel vat samen welke type in welk geheugen wordt bewaard:
Waarom plaatsen we niet alles in de stack? De reden hiervoor is dat bij het compileren van je applicatie er reeds zal berekend worden hoeveel geheugen de stack zal nodig hebben. Wanneer je programma dus later wordt uitgevoerd weet het OS perfect hoeveel geheugen het minstens moet reserveren bij het besturingssysteem.
Er is echter een probleem: de compiler kan niet alles perfect berekenen of voorspellen. Van een variabele van het type int is perfect geweten hoe groot die zal zijn (32 bit). Maar wat met een string die je aan de gebruiker vraagt? Of wat met een array waarvan we pas tijdens de uitvoer de lengte gaan berekenen gebaseerd op runtime informatie?
Het zou nutteloos (en zonde) zijn om reeds bij aanvang een bepaalde hoeveelheid stackgeheugen voor een array te reserveren als we niet weten hoe groot die zal worden. Beeld je in dat alle applicaties op je computer voor alle zekerheid een halve gigabyte aan geheugen zouden vragen. Je computer zou enkele terabyte aan geheugen nodig hebben. Het is dus veel realistischer om enkel het geheugen te reserveren waar de compiler 100% zeker van is dat deze zal nodig zijn.
De heap laat ons toe om geheugen op een wat minder gestructureerde manier in te palmen. Tijdens de uitvoer van het programma fungeert de heap als een grote speelplaats waar je overal dingen kunt neerzetten, zolang er maar ruimte vrij is. De stack daarentegen is het kleine bankje naast de zandbak: handig, snel, en met een precies bekende grootte.
Value type variabelen worden in de stack bewaard. De effectieve waarde van de variabele wordt in de stack bewaard.
Dit zijn alle gekende, 'eenvoudige' datatypes die we totnogtoe gezien hebben:
Wanneer we een value-type willen kopiëren gebruiken we de =-operator die de waarde van de rechtse operand zal uitlezen en zal kopiëren naar de linkse operand:
int getal = 3;
int anderGetal = getal;
Vanaf nu zal anderGetal de waarde 3 hebben. Als we nu één van beide variabelen aanpassen dan zal dit geen effect hebben op de andere variabelen.
We zien hetzelfde effect wanneer we een methode maken die een parameter van het value type aanvaardt:
void VerhoogParameter(int a)
{
a++;
Console.WriteLine($"In methode {a}");
}
Bij de aanroep geven we een kopie van de variabele mee:
int getal = 5;
VerhoogParameter(getal);
Console.WriteLine($"Na methode {getal}");
De parameter a zal de waarde 5 gekopieerd krijgen. Maar wanneer we nu zaken aanpassen in a zal dit geen effect hebben op de waarde van getal.
Reference types worden in de heap bewaard. De effectieve waarde wordt in de heap bewaard, en in de stack zal enkel een referentie of pointer naar de data in de heap bewaard worden. Een referentie is niet meer dan het geheugenadres naar waar verwezen wordt (bv. 0xA3B3163).
Concreet zijn dit alle zaken die vaak redelijk groot zullen zijn of waarvan op voorhand niet kan voorspeld worden hoe groot ze at runtime zullen zijn (denk maar aan arrays, instanties van complexe klassen, enz.).
We zien dit gedrag bij alle reference types, zoals objecten:
Student stud = new Student();
Wat gebeurt er hier?
new Student() : new roept de constructor van Student aan. Deze zal met behulp van een constructor een object in de heap aanmaken en vervolgens de geheugenlocatie ervan teruggeven.
Een variabele stud wordt in de stack aangemaakt en mag enkel een referentie naar een object van het type Student bewaren.
De geheugenlocatie uit de eerste stap wordt vervolgens in stud opgeslagen in de stack.
Laten we eens inzoomen op voorgaande door de code even in 2 delen op te splitsen:
Student stud;
stud = new Student();
Het geheugen na lijn 1 ziet er zo uit:
Merk op dat de variabele stud eigenlijk de waarde null heeft. We leggen later uit wat dit juist wil zeggen.
Lijn 2 gaan we nog trager bekijken: Eerst zal het gedeelte rechts van de =-operator uitgevoerd worden. Er wordt dus in de heap een nieuw Student-object aangemaakt:
Vervolgens wordt de toekenning toegepast en wordt het geheugenadres van het object in de variabele stud geplaatst:
Ik ga nogal licht over het new-keyword en de constructor. Maar zoals je merkt is dit een ongelooflijk belangrijk mechanisme in de wereld van de objecten. Het brengt letterlijk objecten tot leven (in de heap) en zal als resultaat laten weten op welke plek in het geheugen het object staat.
Student a = new Student("Abba");
Student b = new Student("Queen");
Geeft volgende situatie in het geheugen:
Schrijven we dan het volgende:
b = a;
Console.WriteLine(a.Naam);
Dan zullen we in dit geval dus Abba op het scherm zien omdat zowel b als a naar hetzelfde object in de heap verwijzen. Het originele "Queen"-object zijn we kwijt en zal verdwijnen (zie Garbage Collector verderop).
De meeste klassen zullen met value type-properties en instantievariabelen werken in zich, toch worden deze ook samen met het gehele object in de heap bewaard en niet in de stack. Kortom het hele object ongeacht de vorm (datatypes) van z'n inhoud wordt in de heap bewaard.
Een stille held van .NET is de zogenaamde GC, de Garbage Collector. Dit is een geautomatiseerd onderdeel van ieder C# programma dat ervoor zorgt dat we geen geheugen nodeloos gereserveerd houden.
De GC zal geregeld het geheugen doorlopen en kijken of er in de heap objecten staat waar geen referenties naar verwijzen. Indien er geen referenties naar wijzen zal dit object verwijderd worden.
In dit voorbeeld zien we dit in actie:
Held supermand = new Held();
Held batmand = new Held();
batmand = supermand;
Vanaf de laatste lijn zal er geen referentie meer naar het originele object zijn waar batmand naar verwees in de heap, daar we deze hebben overschreven met een referentie naar het eerste Held object in supermand. De GC zal dus dat tweede aangemaakte Held object verwijderen. Wil je dat niet dan zal je minstens 1 variabele moeten hebben die naar de data verwijst. Volgend voorbeeld toont dit:
Held supermand = new Held();
Held batmand = new Held();
Held bewaarEersteHeld = batmand;
batmand = supermand;
De variabele bewaarEersteHeld houdt dus een referentie naar die in batmand bij en we kunnen dus later via deze variabele alsnog aan de originele data.
De GC werkt niet continue daar dit te veel overhead van je computer zou vereisen. De GC zal gewoon om de zoveel tijd alle gereserveerde geheugenplekken van de applicatie controleren en die delen verwijderen die niet meer nodig zijn.
Je kan de GC manueel de opdracht geven om een opkuisbeurt te starten met GC.Collect() maar dit is ten stelligste af te raden! De GC weet meestal beter dan ons wanneer er gekuist moet worden.
Klassen zijn "gewoon" nieuwe datatypes. Alle regels die we dus al kenden in verband met het doorgeven van variabelen als parameters in een methoden blijven gelden voor de meeste klassen (behalve static klassen die we in volgend hoofdstuk zullen aanpakken).
Het enige verschil is dat we objecten by reference meegeven aan methoden. Aanpassingen aan het object in de methode zal dus betekenen dat je het originele object aanpast dat aan de methode werd meegegeven, net zoals we bij arrays zagen. Hier moet je dus zeker rekening mee houden.
Stel dat we volgende klasse hebben waarin we temperatuurmetingen willen opslaan, alsook wie de meting heeft gedaan:
internal class Meting
{
public int Temperatuur { get; set; }
public string OpgemetenDoor { get; set; }
}
We voegen vervolgens een methode aan de klasse toe die ons toelaat om deze meting op het scherm te tonen in een bepaalde kleur.
public void ToonMetingInKleur (ConsoleColor kleur)
{
Console.ForegroundColor = kleur;
Console.WriteLine($"{Temperatuur} graden C gemeten door: {OpgemetenDoor}");
Console.ResetColor();
}
Het gebruik van deze klasse zou er als volgt kunnen uitzien:
Je kan ook methoden schrijven die meegegeven objecten aanpassen daar we deze by reference doorsturen. Een voorbeeld waarin een meting als parameter meegeven en toevoegen aan een andere meting, waarna we de originele meting "resetten":
public void VoegMetingToeEnVerwijder(Meting inMeting)
{
Temperatuur += inMeting.Temperatuur;
inMeting.Temperatuur = 0;
inMeting.OpgemetenDoor = "";
}
We zouden deze methode als volgt kunnen gebruiken (ervan uitgaande dat we 2 objecten m1 en m2 van het type Meting hebben):
Weer hetzelfde verhaal: ook klassen mogen het resultaat van een methoden zijn. Stel dat we een nieuw meting object willen maken dat de dubbele temperatuur bevat van het object waarop de methode wordt aangeroepen:
public Meting GenereerRandomMeting()
{
Meting result = new Meting();
result.Temperatuur = Temperatuur * 2;
result.OpgemetenDoor = $"{OpgemetenDoor} Junior";
return result;
}
In voorgaande voorbeeld zagen we reeds dat objecten dus objecten van het eigen type kunnen teruggeven. Laten we dat voorbeeld eens doortrekken naar hoe de bevalling van een kind in C# zou gebeuren.
Baby's zijn kleine mensjes. Het is dan ook logisch dat mensen een methode PlantVoort hebben (we houden geen rekening met het geslacht). Volgende klasse Mens is dus perfect mogelijk:
class Mens
{
public Mens PlantVoort()
{
return new Mens();
}
}
Vervolgens kunnen we het volgende doen:
Mens oermoeder = new Mens();
Mens dochter;
Mens kleindochter;
dochter = oermoeder.PlantVoort();
kleindochter = dochter.PlantVoort();
Het is een interessante oefening om deze code eens uit te tekenen in de stack en heap inclusief de verschillende referenties.
Ik ga voorgaande code over enkele pagina's nog uitbreiden om een meer realistisch voortplantingsscenario te hebben (sommige zinnen verwacht je nooit te zullen schrijven in je leven... I was wrong).
Zoals nu duidelijk is bevatten referentievariabelen steeds een referentie naar een object. Maar wat als we dit schrijven:
Student stud1;
stud1.Naam = "Marc Jansens";
Dit zal een fout geven. Het object stud1 bevat namelijk nog geen referentie. Maar wat dan wel?
Deze variabele bevat de waarde null . Net zoals bij value types die een default waarde hebben als je er geen geeft (bv. 0 bij een int ), zo bevatten reference type variabelen altijd null als standaardwaarde.
null is een waarde die je kan toekenen aan eender welk reference type. Je doet dit om aan te geven dat er nog geen referentie naar een effectief object in de variabele staat. Je kan dus ook op deze waarde testen.
Van zodra je een referentie naar een object (een bestaand of eentje dat je net met new hebt aangemaakt) aan een reference type variabele toewijst (met de = operator) zal de null waarde uiteraard overschreven worden.
Merk op dat de GC enkel op de heap werkt. Indien er in de stack dus een variabele de waarde null heeft zal de GC deze nooit verwijderen!
Een veel voorkomende foutboodschap tijdens de uitvoer van je applicatie is een NullReferenceException. Deze zal optreden wanneer je code een object probeert te benaderen wiens waarde null is (een onbestaand object met andere woorden).
Dit zal resulteren in een foutboodschap in VS bij de lijn die de uitzondering detecteert: "System.NullReferenceException: 'Object reference not set to an instance of an object'. stud1 was null".
We moeten in dit voorbeeld expliciet = null plaatsen daar Visual Studio slim genoeg is om je te waarschuwen voor eenvoudige potentiële NullReference fouten en je code anders niet zal compileren.
Objecten die niet bestaan zullen altijd null hebben. Uiteraard kan je niet altijd al je code uitvlooien waar je misschien vergeten bent een object met new aan te te maken.
Voorts kan het ook soms by design zijn dat een object voorlopig null is.
Gelukkig kan je controleren of een object null is als volgt:
if(stud1 == null)
Console.WriteLine("Oei. Object bestaat niet.")
Op die manier voorkom je een NullReferenceException. Het is uiteraard omslachtig om steeds die check te doen. Je mag daarom ook schrijven:
Console.WriteLine(stud1?.Name)
Het vraagteken direct na het object geeft aan: "Gelieve de code na dit vraagteken enkel uit te voeren indien het object voor het vraagteken niét null is".
Bovenstaande code zal dus gewoon een lege lijn op scherm plaatsen indien stud1 effectief null is, anders komt de naam op het scherm.
Uiteraard mag je ook expliciet null teruggeven als resultaat van een methode. Stel dat je een methode hebt die in een array een bepaald object moet zoeken. Wat moet de methode teruggeven als deze niet gevonden wordt? Inderdaad, we geven dan null terug.
Volgende methode zoekt in een array van studenten naar een student met een specifieke naam en geeft deze terug als resultaat. Enkel als de hele array werd doorlopen en er geen match is wordt er null teruggegeven (de werking van arrays van objecten wordt later besproken):
static Student ZoekStudent(Student[] array, string naam)
{
Student gevonden = null;
for (int i = 0; i < array.Length; i++)
{
if (array[i].Name == naam)
gevonden = array[i];
}
return gevonden;
}
Tijd om het voorbeeld van de voortplanting der mensch er nog eens bij te nemen. Beeld je nu in dat we dichter naar de realiteit willen gaan (meestal toch het doel van OOP) en de baby eigenschappen van beide willen ouders geven. Stel dat mensen een maximum lengte hebben die ze genetisch kunnen halen, aangeduid via een auto-property MaxLengte. De maximale lengte van een baby is steeds de lengte van de grootste ouder (in de echte genetica is dat natuurlijk niet).
De klasse Mens breiden we uit naar:
internal class Mens
{
public int MaxLengte {get; set;}
public Mens PlantVoort(Mens dePapa)
{
Mens baby = new Mens();
baby.MaxLengte = MaxLengte;
if(dePapa.MaxLengte >= MaxLengte)
baby.MaxLengte = papa.MaxLengte;
return baby;
}
}
Mooi toch?!
Om het nu volledig te maken zullen we er voor zorgen dat enkel een vrouw kan voortplanten. Voorts kan ze zich enkel voortplanten met behulp van een van een man (merk op dat OOP als doel heeft de realiteit te benaderen, maar ook te vereenvoudigen naargelang het probleem).
Veronderstel dat het geslacht via een enumtype (enum Geslachten {Man, Vrouw}) in een auto-property Geslacht wordt bewaard. We voegen daarom bovenaan in de PlantVoort-methode nog een kleine check in én return'n een leeg (null) object als de voortplanting faalt (we zouden ook een Exception kunnen opwerpen):
public Mens PlantVoort(Mens dePapa)
{
if(Geslacht == Geslachten.Vrouw
&& dePapa.Geslacht == Geslachten.Man)
{
Mens baby = new Mens();
baby.MaxLengte = MaxLengte;
if(dePapa.MaxLengte >= MaxLengte)
baby.MaxLengte = papa.MaxLengte;
return baby;
}
return null;
}
Volgende code produceert nu een kersverse baby:
Mens mama = new Mens();
mama.Geslacht = Geslachten.Vrouw;
mama.MaxLengte = 180;
Mens papa = new Mens();
papa.Geslacht = Geslachten.Man;
papa.MaxLengte = 169;
Mens baby = mama.PlantVoort(papa);
Hopelijk voel je bij dit voorbeeld hetzelfde enthousiasme als toen we Pong naar OOP omzetten. Probeer voorgaande voorbeeld eens te schrijven met je kennis VOOR je klassen en objecten kende? Doenbaar? Zeker. Veel werk? Dat nog meer. En daar is het ons om te doen: krachtige, makkelijker te onderhouden code leren schrijven!
Een namespace wordt gebruikt om te voorkomen dat 2 projecten die toevallig dezelfde klassenamen hebben in conflict komen. Beeld je in dat je een project van iemand anders toevoegt aan jouw project en je ontdekt dat in dat project reeds een klasse Student aanwezig is. Hoe weet C# nu welke klasse moet gebruikt worden? Want mogelijk wens je beide te gebruiken!
De namespace rondom een klasse is als het ware een extra stukje naamgeving waarmee je kan aangeven welke klasse je juist nodig hebt. In bovenstaand stukje code heb ik een project MyEpicGame gemaakt en zoals je ziet bevat het een klasse Monster. De volledige naam (of Fully Qualified Type Name) van deze klasse is MyEpicGame.Monster.
Als ik dus even later een project met volgende namespace, en zelfde klassenaam, importeer:
namespace NietZoEpicGame
{
internal class Monster
Dan kan ik deze klasse aanroepen als NietZoEpicGame.Monster en kan er dus geen verwarring optreden.
De politie uw vriend! Inderdaad. De auteur van dit boek heeft klachten gekregen over het feit dat hij het edele beroep van politie-agent ietwat besmeurd. We willen daarom even u attenderen en, zoals een goed agent betaamd, u de weg doorheen de stad wijzen.
Als u ons tegenkomt en vraagt "Waar is de Kerkstraat." Dan zullen wij u meer informatie moeten vragen. Zonder er bij te zeggen in welke gemeente u die straat zoekt, is de kans bestaande dat we u naar de verkeerde Kerkstraat sturen. Er zijn er namelijk best veel Kerkstraten in België en Nederland. Wel, namespaces zijn exact dat. Je kan ze vergelijken als een stadsnaam die essentiëel is bij een straatnaam. De stadsnaam laat toe om zonder verwarring een straat (de klasse in dit geval) te identificeren. Nog een fijne dag!
Wanneer je een bepaalde namespace nodig hebt (standaard laadt een C# 10 project er maar een handvol in) dan dien je dit bovenaan je bestand aan te geven met using. Bijvoorbeeld using System.Diagnostics. Je zegt dan eigenlijk: "Beste C#, als je een klasse zoekt en je vindt ze niet in dit project: kijk dan zeker in de System.Diagnostics-bibliotheek."
Het gebeurt soms dat je een klasse gebruikt en je weet zeker dat ze in jouw project of een bestaande .NET bibliotheek aanwezig is. Visual Studio kan je helpen de namespace van deze klasse te zoeken moest je daar te lui voor zijn.
Je doet dit door de naam van de klasse te schrijven (op de plek waar je deze nodig hebt) en dan op het lampje dat links in de rand verschijnt te klikken. Indien de klasse gekend is door VS zal je nu de optie krijgen om automatisch:
oftewel using, met de juiste namespace, bovenaan je huidige codebestand te plaatsen.
oftewel de volledige naam van de klasse uit te schrijven (dus inclusief de namespace).
Trouwens: de optie Generate type .. zal je ook vaak kunnen gebruiken. Wanneer de klasse in kwestie (Fiets hier) nog niet bestaat en je wilt deze automatische laten genereren (in een apart bestand) dan zal deze optie dat voor je doen.
Maar hoe weet C# nu welke bibliotheken allemaal beschikbaar zijn? Wel, je kan in je project via de solution explorer kijken welke bibliotheken (meestal in de vorm van DLL-bestanden) werden toegevoegd. In je solution explorer klik je hiervoor de Dependencies open. Daar kan je dan zien in welke bibliotheken VS mag zoeken als je een klasse nodig hebt die niet gekend is. Klik bijvoorbeeld eens onder Dependencies de sectie FrameWorks open en dan MicrosofT.NETCore.App. Je zal er onder andere alle System. bibliotheken zien staan.
Je kan ook extra bibliotheken toevoegen aan je Dependencies.
Rechterklik maar eens op Dependencies en zie wat je allemaal kunt doen. Vooral de NuGet packages zijn een erg nuttig en krachtig hulpmiddel.1
Helaas kan niet alles over C# en .NET in één boek verzameld worden. Weet echter dat er erg nuttige, toffe en zelfs grappige NuGet packages bestaan. Zoek bijvoorbeeld maar eens naar de Colorful.Console NuGet!
Het wordt tijd om de olifant in de kamer te benoemen. Het wordt tijd om een bekentenis te maken... Ben je er klaar voor?! Hier komt ie. Luister goed, maar zeg het niet door: ik heb al de hele tijd informatie voor je achter gehouden! Sorry, het was sterker dan mezelf. Maar ik deed het voor jou. Het was de enige manier om ervoor te zorgen dat je leerde programmeren zonder constant bugs in je code achter te laten. Dus ja, hopelijk neem je het me niet kwalijk?
Het wordt tijd om exception handling er bij te halen! Een essentiële programmeertechniek die ervoor zorgt dat je programma minder snel zal crashen indien er zich uitzonderingen tijdens de uitvoer voordoen.
Wat een dramatische start zeg. Waar was dat voor nodig?! De reden is eenvoudig: exception handling is een tweesnijdend zwaard. Je zou exception handling kunnen gebruiken om al je bugs op te vangen, zodat de eindgebruiker niet ziet hoe vaak je programma zou crashen zonder exception handling.
Maar uiteindelijk blijf je wel met slechte code zitten en een gouden regel in programmeren is dat slechte code je altijd zal achtervolgen en je ooit dubbel en hard zal straffen voor iedere bug waar je te lui voor was om op te lossen. Kortom, exception handling is de finale fase van goedgeschreven code.
Het aanroepen van data die er niet is : bijvoorbeeld een bestand dat werd verplaatst of hernoemd . Of wat denk je van het wegvallen van het wifi-signaal net wanneer je programma iets van een online database nodig heeft.
Foute invoer door de gebruiker : denk aan de gebruiker die een letter invoert terwijl het programma een getal verwacht.
Programmeerfouten : de ontwikkelaar gebruikt een object dat nog niet met de new operator werd geïnitialiseerd. Of bijvoorbeeld een deling door nul in een wiskundige berekening.
Voorgaande zaken zijn eigenlijk geen fouten, maar uitzonderingen (exceptions). Ze doen zich zelden voor, maar hebben wel een invloed op de correcte uitvoer van je programma. Je programma zal met deze uitzonderingen rekening moeten houden wil je een gebruiksvriendelijk programma hebben. Veel uitzonderingen gebeuren buiten de wil van het programma om (geen wifi , foute invoer, enz.). Door deze uitzonderingen af te handelen (exception handling), kunnen we ons programma instructies geven om alternatieve acties uit te voeren wanneer er een uitzondering optreedt.
Je hebt waarschijnlijk al eerder exceptions gezien in je eigen programma's. Als je programma plots een hele hoop tekst toont (waaronder het woord "Exception") en vervolgens direct afsluit, heb je een exception gegenereerd die niet is afgehandeld.
Je moet zelfs niet veel moeite doen om uitzonderingen te genereren. Denk maar aan volgende voorbeeld waarbij je een exception kan genereren door een 0 in te geven, of iets anders dan een getal.
Console.WriteLine("Geef een getal aub");
int noemer = Convert.ToInt32(Console.ReadLine());
double resultaat = 100/noemer;
Console.WriteLine($"100/{noemer} is gelijk aan {resultaat}");
Het mechanisme om exceptions af te handelen in C# bestaat uit 2 delen:
Een try blok: binnen dit blok staat de code die je wil controleren op uitzonderingen omdat je weet dat die hier kunnen optreden.
Een of meerdere catch-blokken: dit blok zal mogelijk exceptions die in het bijhorende try-block voorkomen opvangen. Met andere woorden: in dit blok staat de code die de uitzondering zal verwerken zodat het programma op een deftige manier verder kan of meer elegant zichzelf afsluiten (graceful shutdown).
De syntax is als volgt (let er op dat de catch blok onmiddellijk na het try-blok komt):
try
{
//code waar exception mogelijk kan optreden
}
catch
{
//exception handling code hier
}
In volgend stukje code kunnen uitzonderingen optreden zoals we zonet zagen:
string input = Console.ReadLine();
int converted = Convert.ToInt32(input)
Een FormatException zal optreden wanneer de gebruiker tekst of een kommagetal invoert. De Convert.ToInt32() methode kan niet met andere input dan gehele getallen werken.
Ik toon nu hoe we dit met exception handling kunnen opvangen1:
Indien er nu een uitzondering optreedt dan zal de tekst "Verkeerde invoer" getoond worden. Vervolgens gaat het programma verder met de code die mogelijk na het catch-blok staat.
1
Merk op dat dit probleem eleganter kan opgelost worden met TryParse wat in het appendix wordt uitgelegd.
Je kan ook zelf eender waar in je code een uitzondering opwerpen. Je doet dit met het throw keyword. De werking is quasi dezelfde als het return keyword. Alleen zal bij een throw je terug gaan tot de eerste plek waar een catch klaarstaat om de uitzondering op te vangen. Om een uitzondering op te werpen dien je eerst een Exception object aan te maken en daar de nodige informatie in te plaatsen. In hoofdstuk 14 ga ik hier nog wat dieper op in, maar hier alvast een voorbeeldje:
//Een error treedt op
throw new Exception("Wow, dit loopt fout");
Afhankelijk van het soort fout kunnen we echter ook andere soort uitzonderingen opwerpen. Draai daarom snel deze pagina om en ontdek hoe dit kan!
Exception is een klasse van het .NET framework. Er zijn van deze basis-klasse meerdere Exception-klassen afgeleid die een specifieke uitzondering behelzen. Enkele veelvoorkomende zijn:
Klasse
Omschrijving
Exception
Basisklasse
SystemException
Klasse voor uitzonderingen die niet al te belangrijk zijn en die mogelijk verholpen kunnen worden.
IndexOutOfRangeException
De index is te groot of te klein voor de benadering van een array
NullReferenceException
Benadering van een niet-geïnitialiseerd object
Je kan in het catch blok aangeven welke soort exceptions je wil vangen in dat blok. Als je bijvoorbeeld alle Exceptions wil opvangen schrijf je:
catch (Exception e)
{
}
Hiermee vangen we dus alle Exceptions op, daar alle Exceptions van de klasse Exception afgeleid zijn en dus ook zelf een Exception zijn. De identifier e kies je zelf en wordt gebruikt om vervolgens in het catch block de nodige informatie uit het opgevangen Exception object (e) uit te lezen. Ik leg dit zo meteen uit.
We kunnen nu echter ook specifieke exceptions opvangen. De truc is om de meest algemene exception onderaan te zetten en naar boven toe steeds specifieker te worden. We maken een fallthrough mechanisme (wat we ook in een switch al hebben gezien).
Stel bijvoorbeeld dat we weten dat de FormatException kan voorkomen en we willen daar iets mee doen. Volgende code toont hoe dit kan:
Indien een FormatException optreedt dan zal het eerste catch-blok uitgevoerd worden, in alle andere gevallen het tweede. Het tweede blok zal niet uitgevoerd worden indien een FormatException optreedt.
De online .NET documentatie is de manier om te weten te komen welke exceptions een methode mogelijk kan opgooien. Gaan we bijvoorbeeld naar de documentatie van de Int32.Parse-methode2 dan zien we daar een sectie "Exceptions" waar klaar en duidelijk wordt beschreven wanneer welke exception wanneer wordt opgeworpen.
De Exceptions die worden opgegooid door een methode zijn objecten van de Exception-klasse. Deze klasse bevat standaard een aantal interessante zaken, die je kan oproepen in je code.
Bovenaan de declaratie van het catch-blok geef je aan hoe het exception object in het blok zal heten. In de vorige voorbeelden was dit altijd e (standaardnaam).
Alle Exception-objecten bevatten volgende informatie:
Element
Omschrijving
Message
Foutmelding in relatief eenvoudige taal.
StackTrace
Lijst van methoden die de exception hebben doorgegeven.
TargetSite
Methode die de exception heeft gegenereerd (staat bij StackTrace helemaal bovenaan).
ToString()
Geeft het type van de exception, Message en StackTrace terug als string.
We kunnen via deze parameter meer informatie uit de opgeworpen uitzondering uitlezen en bijvoorbeeld aan de gebruiker tonen:
Vanuit een security standpunt is het zelden aangeraden om Exception informatie zomaar rechtstreeks naar de gebruiker te sturen. Mogelijk bevat de informatie gevoelige informatie en zou deze door kwaadwillige gebruikers kunnen misbruikt worden om bugs in je programma te vinden.
De plaats in je code waar je je exceptions zal opvangen, heeft invloed op de totale werking van je code.
Stel dat je volgende stukje code hebt waarin je een methode hebt die een lijst van strings zal beschouwen als urls die moeten gedownload worden. Indien er echter fouten in de string staan dan zal er een uitzondering optreden bij lijn 16. De tweede url ("http:\\www.humo.be") bevat namelijk een bewuste fout: de schuine strepen staan in de verkeerde richting.
Als sneak preview tonen we ook ineens hoe arrays van objecten werken.
static void Main(string[] args)
{
string[] urllist = new string[3];
urllist[0] = "http://www.ziescherp.be";
urllist[1] = "http:\\www.humo.be";
urllist[2] = "timdams.com";
DownloadAllUris(urllist);
}
static public void DownloadAllUris(string[] urls)
{
System.Net.WebClient webClient = new System.Net.WebClient();
for(int i = 0; i < urls.Length;i++)
{
Uri uri = new Uri(urls[i]);
string result = webClient.DownloadString(uri);
Console.WriteLine($"{uri} gedownload. Resultaat: {result}");
}
}
De WebClient-klasse laat toe te werken met online zaken, zoals websites, restful API's, webservices, enz. Je kan er bijvoorbeeld heel makkelijk een webscraper mee maken.
We bekijken nu een aantal mogelijk try/catch locaties in deze code en zien welke impact deze hebben op de totale uitvoer van het programma.
http://www.ziescherp.be gedownload!
Ongeldige URI: kan de Authority/Host niet parsen.
Met andere woorden, zolang de urls geldig zijn zal de download lukken. Bij de eerste fout die optreedt zal de volledige methode echter stoppen. Dit is waarschijnlijk enkel wenselijk indien de code erna de informatie van ALLE urls nodig heeft.
Mogelijk wil je echter dat je programma blijft werken indien er 1 of meerdere urls niet werken. We plaatsen dan de try catch niet rond de methode DownloadAllUris, maar net binnenin de methode zelf rond het gedeelte dat kan mislukken:
for(int i = 0; i < urls.Length;i++)
{
try
{
Uri uri = new Uri(urls[i]);
string result = webClient.DownloadString(uri);
Console.WriteLine($"{uri} gedownload. Resultaat: {result}");
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
Dit zal resulteren in:
http://www.ziescherp.be gedownload!
Ongeldige URI: kan de Authority/Host niet parsen.
Ongeldige URI: de indeling van de URI kan niet worden bepaald.
Met andere woorden, indien een bepaalde url niet geldig is dan zal deze overgeslagen worden en gaat de methode verder naar de volgende. Op deze manier kunnen we alsnog alle urls trachten te downloaden.
Soms zal je na een try-catch-blok ook nog een finally blok zien staan. Dit blok laat je toe om code uit te voeren die ALTIJD moet uitgevoerd worden, ongeacht of er een exception is opgetreden of niet. Je kan dit gebruiken om bijvoorbeeld er zeker van te zijn dat het bestand dat je wou uitlezen terug afgesloten wordt.
try
{
Uri uri = new Uri(urls[i]);
string result = webClient.DownloadString(uri);
Console.WriteLine($"{uri} gedownload. Resultaat: {result}");
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
finally
{
//Plaats hier zaken die sowieso moeten gebeuren.
}
Nu we weten wat er allemaal achter de schermen gebeurt met onze objecten, wordt het tijd om wat meer geavanceerde concepten van klassen en objecten te bekijken.
We hebben al ontdekt dat een klasse kan bestaan uit:
Instantievariabelen: variabelen die de toestand van het individuele object bijhouden.
Methoden: om objecten voor ons te laten werken (gedrag).
Properties: om op een gecontroleerde manier toegang tot de interne staat van de objecten te verkrijgen.
Uiteraard is dit niet alles. In dit hoofdstuk bekijken we:
Constructors: een gecontroleerde manier om de beginstaat van een object in te stellen.
static: die je de mogelijkheid geeft een (deel van je) klasse te laten werken als een object.
Object initializer syntax: een recente C# aanvulling die het aanmaken van nieuwe objecten vereenvoudigd.
Objecten die je aanmaakt komen niet zomaar tot leven. Nieuwe objecten maken we aan met behulp van de new operator zoals we al gezien hebben:
Student frankVermeulen = new Student();
De new operator doet 3 dingen:
Het maakt een object aan in het heap geheugen.
Het roept de constructor van het object aan voor eventuele extra initialisatie.
Het geeft een referentie naar het object in het heap geheugen terug.
Via de constructor van een klasse kunnen we extra code meegeven die moet uitgevoerd worden telkens een nieuw object van dit type wordt aangemaakt.
De constructor is een unieke methode die wordt aangeroepen bij het aanmaken van een object. Daarom dat we dus ronde haakjes zetten bij new Student().
Momenteel hebben we in de klasse Student de constructor nog niet expliciet beschreven. Maar zoals je aan bovenstaande code ziet bestaat deze constructor al wel degelijk.Hij doet echter niets extra. Zo krijgen de instantievariabelen gewoon hun default waarde toegekend, afhankelijk van hun datatype.
De naam "constructor" zegt duidelijk waarvoor het concept dient: het construeren van objecten. Constructors mogen maar op 1 moment in het leven van een object aangeroepen worden: tijdens hun geboorte m.b.v. new.
Je mag een constructor op geen enkel ander moment gebruiken!
Als programmeur van eigen klassen zijn er 3 opties voor je:
Je gebruikt geen zelfgeschreven constructors: het leven gaat voort zoals het is. Je kunt objecten aanmaken zoals eerder getoond. Een onzichtbare default constructor wordt voor je uitgevoerd.
Je hebt enkel een default constructor nodig: je kan nog steeds objecten met new Student() aanmaken. Maar je gaat zelf beschrijven wat er moet gebeuren in de default constructor. De default constructor herken je aan het feit dat je geen parameters meegeeft aan de constructor tijdens de new aanroep.
Je gebruikt één of meerdere overloaded constructors: hierbij zal je dan actuele parameters kunnen meegeven bij de creatie van een object. Denk maar aan new Student(24, "Jos").
Constructors zijn soms gratis, soms niet. Een lege default constructor voor je klasse krijg je standaard wanneer je een nieuwe klasse aanmaakt. Je ziet deze niet en kan deze niet aanpassen. Je kan echter daarom altijd objecten met new Student() aanmaken.Van zodra je echter beslist om zelf één of meerdere constructors te schrijven zal C# zeggen: "Ok, jij je zin, nu doe je alles zelf". De default constructor die je gratis kreeg zal ook niet meer bestaan. Heb je die nodig dan zal je die dus zelf moeten schrijven!
Een nadeel van C# is dat het soms dingen voor ons achter de schermen doet, en soms niet. Het is mijn taak je dan ook duidelijk te maken wanneer dat wél en wanneer dat net niét gebeurt. Ik vergelijk het altijd met het werken met aannemers: soms ruimen ze hun eigen rommel op nadien, maar soms ook niet. Alles hangt er van af hoe ik die aannemer heb opgetrommeld.
De default constructor is een constructor die geen extra parameters aanvaardt. Een default constructor bestaat ALTIJD uit volgende vorm:
Iedere constructor is altijd public .
Heeft geen returntype, ook niet void.
Heeft als naam de naam van de klasse zelf.
Heeft geen extra formele parameters.
Stel dat we een klasse Student hebben:
internal class Student
{
public int UurVanInschrijven {private set; get;}
}
We willen telkens een Student-object wordt aangemaakt bijhouden op welk uur van de dag dit plaatsvond. Eerst schrijven de default constructor, deze ziet er als volgt uit:
internal class Student
{
public Student()
{
// zet hier de code die bij initialisatie moet gebeuren
}
public int UurVanInschrijven {private set; get;}
}
Zoals verteld moet de constructor de naam van de klasse hebben, public zijn en geen returntype definiëren.
Vervolgens voegen we de code toe die we nodig hebben:
internal class Student
{
public Student()
{
UurVanInschrijven = DateTime.Now.Hour;
}
public int UurVanInschrijven {private set; get;}
}
Telkens we nu een object zouden aanmaken met new Student() zal de waarde in UurVanInschrijven afhangen van het moment waarop we de code uitvoeren. Beeld je in dat we dit programma uitvoeren om half twaalf 's morgens:
Student eenStudent = new Student();
Dan zal de property UurVanInschrijven van eenStudent op 11 worden ingesteld.
Constructors zijn soms nogal zwaarwichtig indien je enkel een eenvoudige auto-property een startwaarde wenst te geven. Wanneer dat het geval is mag je dit ook als volgt doen:
internal class Student
{
public int UurVanInschrijven {private set; get;} = 2;
}
Soms wil je parameters aan een object meegeven bij de creatie ervan. We willen bijvoorbeeld de bijnaam meegeven die het object moet hebben bij het aanmaken.
Met andere woorden, stel dat we dit willen schrijven:
Student jos = new Student("Lord Oakenwood");
Als we dit met voorgaande klasse uitvoeren zal de code een fout geven. C# vindt geen constructor die een string als actuele parameter aanvaardt.
Net zoals bij overloading van methoden kunnen we ook constructors overloaden. De code is verrassend gelijkaardig aan method overloading:
internal class Student
{
public Student(string bijnaamIn)
{
BijNaam = bijnaamIn;
}
public string BijNaam { get; private set;}
}
Dat was eenvoudig, hé?
Maar denk eraan: je hebt een overloaded constructor geschreven. Hierdoor zegt C# eigenlijk tegen je: "Ok, je schrijft zelf constructors? Trek je plan nu maar. De default constructor zal je ook nu zelf moeten schrijven."
Je kan nu enkel je objecten nog via de overloaded constructors aanmaken. Schrijf je new Student() dan zal je een foutboodschap krijgen. Wil je de default constructor toch nog hebben dan zal je die dus ook expliciet moeten schrijven, bijvoorbeeld:
internal class Student
{
private const string DEFBIJNAAM = "Geen";
//Default
public Student()
{
BijNaam = DEFBIJNAAM;
}
//Overloaded
public Student(string bijnaamIn)
{
BijNaam = bijnaamIn;
}
public string BijNaam { get; private set;}
}
Voorgaande wil ik nog eenmaal herhalen. Herinner je m'n voorbeeld van die aannemers die soms wel en soms niet opruimden? Ik zal nog eens samenvatten hoe het zit met constructors in C#:
Als je geen constructors schrijft krijg je een default constructor gratis. Die doet echter niets extra buiten alle instantievariabelen en properties default waarden geven.
Van zodra je één constructor zelf schrijft krijg je niets meer gratis én zal je dus zelf die constructors moeten bijschrijven die jouw code vereist.
Wil je meerdere overloaded constructors dan mag dat ook. Je wilt misschien een constructor die de bijnaam vraagt alsook een bool om mee te geven of het om een werkstudent gaat:
internal class Student
{
private const string DEFBIJNAAM = "Geen";
//Default
public Student()
{
BijNaam = DEFBIJNAAM;
}
//Overloaded 1
public Student(string bijnaamIn)
{
BijNaam = bijnaamIn;
}
//Overloaded 2
public Student(string bijnaamIn, bool isWerkStudentIn)
{
BijNaam = bijnaamIn;
IsWerkStudent = isWerkStudentIn
}
public string BijNaam { get; private set;}
public string IsWerkStudent { get; private set;}
}
Merk op dat je ook full properties best aanroept in je constructor en niet rechtstreeks de achterliggende instantievariabele. Zo kan je ogenblikkelijk de typische controles in een set in gebruik nemen.
Beeld je in dat het schoolsysteem crasht wanneer een nieuwe student een onbeleefde bijnaam invoert. Wanneer dit gebeurt moet de bijnaam altijd gewoon op "Good boy" gezet worden, ongeacht de effectieve bijnaam van de student. Via een set-controle kunnen we dit doen én vervolgens passen we de auto-property aan naar een full property zodat er een ingebouwde controle kan plaatsvinden:
internal class Student
{
private const string DEFBIJNAAM = "Good boy";
//Default
public Student()
{
bijNaam = DEFBIJNAAM;
}
//Overloaded
public Student(string bijnaamIn)
{
bijNaam = bijnaamIn;
}
public string BijNaam
{
private set
{
if(value == "stommerik") //pardon my french
{
bijNaam = DEFBIJNAAM;
}
else
bijNaam = value;
}
get
{
return bijNaam;
}
}
private string bijNaam;
}
Deze manier voorkomt dat de constructors verantwoordelijk zijn opdat properties de juiste waarden krijgen. Leg steeds de verantwoordelijk bij het element zelf. Door dit te doen hoef je ook niet in iedere constructor te controleren doorgegeven parameters wel geldig zijn. Ook hier blijft de regel gelden: als je dubbele code dicht bij elkaar ziet staan dan is de kans groot dat je dit kan vereenvoudigen.
internal class Microfoon
{
public Microfoon(string merkIn, bool isUitverkochtIn)
{
IsUitverkocht = isUitverkochtIn;
Merk = merkIn;
}
public Microfoon(string merkIn)
{
IsUitverkocht = false;
Merk = merkIn;
}
public Microfoon()
{
Merk = "Onbekend";
isUitverkocht = true;
}
public string Merk { get; set;}
public bool IsUitverkocht {get; set;}
}
Bij voorgaande code gaat er mogelijk bij sommige van jullie een alarmbelletje af vanwege de kans op quasi dezelfde code in de verschillende constructors. En dat is een terecht alarm!
Om te voorkomen dat we steeds dezelfde toewijzingen moeten schrijven in constructors laat C# toe dat je een andere constructor kunt aanroepen bij een constructor call.
We gebruiken hier een speciale methode aanroep (this()) bij de constructorsignatuur. Via deze aanroep kunnen we dan eventueel parameters meegeven, afhankelijk van wat we nodig hebben. De compiler zal aan de hand van de parameters (of het ontbreken) beslissen welke constructor nodig is.
Dit gebeurt met behulp van de klassieke method overload resolution en de betterness regel.
Voorgaande klasse gaan we herschrijven zodat alle constructors de bovenste overloaded constructor gebruiken en zo voorkomen dat we te veel dubbele code hebben:
internal class Microfoon
{
public Microfoon(string merkIn, bool isUitverkochtIn)
{
IsUitverkocht = isUitverkochtIn;
Merk = merkIn;
}
public Microfoon(string merkIn): this(merkIn, false)
{ }
public Microfoon(): this ("Onbekend", true)
{ }
public string Merk { get; set;}
public bool IsUitverkocht {get; set;}
}
Bij de tweede overloaded constructor geven we de binnenkomende parameter merkIn gewoon door naar de this() aanroep. Voorts voegen we er nog een tweede literal (false) aan toe. De compiler zal nu via method overload resolution op zoek gaan naar de best passende constructor, wat in dit geval de bovenste overloaded constructor zal zijn.
Uiteraard ben je vrij om in de constructor zelf nog steeds code te plaatsen. Het is gewoon belangrijk dat je de volgorde begrijpt waarin de constructor-code wordt doorlopen. Stel dat we volgende constructor toevoegen:
Wanneer we een object aanmaken (met new Microfoon(true)) dan zal uiteindelijk dit object van het merk Wit Product zijn. Er gebeurt namelijk het volgende:
De overloaded constructor Microfoon(bool isUitverkochtIn) wordt aangeroepen.
Ogenblikkelijk wordt de meegegeven actuele parameter isUitverkochtIn doorgegeven om de overloaded constructor Microfoon(string merkIn, bool isUitverkochtIn) te benaderen.
Deze constructor zal het Merk op Bovarc zetten en IsUitverkocht op true (daar we die parameter doorgeven).
We keren nu terug naar de contructor Microfoon(bool isUitverkochtIn) en voeren de code hiervan uit. Bijgevolg wordt de waarde in Merk overschreven met Wit Product.
Dit hangt natuurlijk af van de soort klasse dat je maakt. Een constructor is minimaal nodig om ervoor te zorgen dat alle variabele die essentieel zijn in je klasse een beginwaarde hebben. Beeld je volgende klasse voor die een breuk voorstelt:
internal class Breuk
{
public int Noemer {get; private set;}
public int Teller {get; private set;}
public double BerekenBreuk()
{
return (double)Teller/Noemer;
}
}
De methode zal een DivideByZeroException opleveren als ik de methode BerekenBreuk zou aanroepen nog voor de Noemer een waarde heeft gekregen (deling door nul, weet je wel):
Breuk eenBreuk = new Breuk();
int resultaat = eenBreuk.BerekenBreuk(); //BAM!Een exception!
Via een constructor kunnen we dit soort bugs voorkomen. We beschermen ontwikkelaars hiermee dat ze jouw klasse foutief gebruiken. Door een overloaded constructor te schrijven die een noemer en teller vereist verplichten we de ontwikkelaar jouw klasse correct te gebruiken. Je kan niet per ongeluk breuk-objecten met de default constructor aanmaken.
Eerst veranderen we de auto-property Noemer naar een full property:
private int noemer;
public int Noemer
{
get
{
return noemer;
}
private set
{
if(value != 0)
noemer = value;
else
noemer = 1; //of werp Exception op zoals eerder uitgelegd.
}
}
En vervolgens voegen we een overloaded constructor toe:
public Breuk(int tellerIn, int noemerIn)
{
Teller = tellerIn;
Noemer = noemerIn
}
Finaal wordt dan onze klasse:
internal class Breuk
{
public Breuk(int tellerIn, int noemerIn)
{
Teller = tellerIn;
Noemer = noemerIn
}
public int Teller {get; private set;}
private int noemer;
public int Noemer
{
get
{
return noemer;
}
private set
{
if(value != 0)
noemer = value;
else
noemer = 1; //of werp Exception op zoals eerder uitgelegd.
}
}
}
Hierdoor kan ik geen Breuk objecten meer als volgt aanmaken:Breuk eenBreuk = new Breuk(); Maar ben ik verplicht deze als volgt aan te maken:
We zullen deze nieuwe informatie gebruiken om onze Pong-klasse uit het eerste hoofdstuk te verbeteren door deze de nodige constructors te geven. Namelijk een default die een balletje aanmaakt dat naar rechtsonder beweegt, en één overloaded constructor die toelaat dat we zelf kunnen kiezen wat de beginwaarden van X, Y, VX en VY zullen zijn:
internal class Balletje
{
public Balletje(int xin, int yin, int vxIn, int vyIn)
{
X = xin;
Y = yin;
VX = vxIn;
VY = vyIn;
}
public Balletje(): this(5,5,1,1)
{
}
//...
We kunnen nu op 2 manieren balletjes aanmaken:
Balletje bal1 = new Balletje();
Balletje bal2 = new Balletje(10,8,-2,1);
Je zou ook kunnen overwegen om in de default constructor het balletje een willekeurige locatie en snelheid te geven:
static Random rng =new Random();
public Balletje()
{
X = rng.Next(0, Console.WindowWidth);
Y = rng.Next(0, Console.WindowWidth);
VX = rng.Nex(-2,3);
VY = rng.Nex(-2,3);
}
Het is niet altijd duidelijk hoeveel overloaded constructors je juist nodig hebt. Meestal beperken we het tot de default constructor en 1 of 2 heel veel gebruikte overloaded constructors.
Dankzij object initializer syntax kan je ook parameters tijdens de aanmaak van objecten meegeven zonder dat je hiervoor een specifieke constructor moet schrijven.
Object initializer syntax laat je toe om tijdens creatie van een object, properties beginwaarden te geven.
Object initializer syntax is een eerste glimp in het feit waarom properties zo belangrijk zijn in C#. Je kan object initializer syntax enkel gebruiken om via properties je object extra beginwaarden te geven.
Stel dat we volgende klasse hebben waarin we enkele auto-properties gebruiken. Merk op dat dit evengoed full properties mochten zijn. Voor object initializer syntax maakt dat niet uit, het ziet toch enkel maar het public gedeelte van de klasse:
internal class Meting
{
public double Temperatuur {get;set;}
public bool IsGeconfirmeerd {get;set;}
}
We kunnen deze properties beginwaarden geven via volgende initializer syntax:
Meting meting = new Meting() { Temperatuur = 3.4, IsGeconfirmeerd = true};
Object initializer syntax bestaat er uit dat je een object aanmaakt met de default constructor en dat je dan tussen accolades een lijst van properties en hun beginwaarden kunt meegeven. Object initializer werkt enkel indien het object een default constructor heeft. Je hoeft deze niet expliciet aan te maken. Indien je klasse geen andere constructors heeft zal er dus een default constructor zijn, zoals ik eerder vertelde.
Bovenstaande code mag ook iets korter nog:
Meting meting = new Meting { Temperatuur = 3.4, IsGeconfirmeerd = true};
Zie je het verschil? De ronde haakjes van de default constructor mag je dus achterwege laten.
De volgorde waarin je code wordt uitgevoerd is wel belangrijk. Je ziet het niet duidelijk, maar sowieso wordt eerst nu de default constructor aangeroepen. Pas wanneer die klaar is zullen de properties de waarden krijgen die je meegeeft tussen de accolades. Als je dus zelf een default constructor in Meting had geschreven dan had eerst die code uitgevoerd zijn geweest. Voorgaande voorbeeld zal intern eigenlijk als volgt plaatsvinden:
Object initializer syntax werd ontwikkeld om de wildgroei aan overloaded constructors in te perken. Echter, dit bracht een nieuw probleem met zich mee. Met behulp van overloaded constructors kan je gebruikers van je klasse verplichten om bepaalde begininformatie van het object bij de creatie mee te geven. Object initializer syntax werkt enkel met een default constructor, en dus was een nieuw keyword vereist. Welkom required!
Door required voor een property te plaatsen kan je aangeven dat deze property verplicht moet ingesteld worden wanneer je een object aanmaakt met object initializer syntax:
internal class Meting
{
public double Temperatuur {get;set;}
public required bool IsGeconfirmeerd {get;set;}
}
Wanneer we nu een Meting als volgt aanmaken:
Meting meting = new Meting { Temperatuur = 0.7};
Dan krijgen we een foutboodschap: Required member 'Meting.IsGeconfirmeerd' must be set in the object initializer or attribute constructor.1 Enkel als we dus minstens IsGeconfirmeerd ook instellen zal onze code werken:
Meting meting = new Meting { IsGeconfirmeerd = true};
Het required keyword werd pas geïntroduceerd in C# 11.0 en zal enkel werken indien je applicaties ontwikkelt in .NET 7 of nieuwer.
1
Attribute constructors worden niet in dit boek behandeld.
Herinner je je dat ik bij de definitie van een klasse het volgende scrheef: "95% van de tijd zullen we in dit boek de voorgaande definitie van een klasse beschrijven, namelijk de blauwdruk voor de objecten die er op gebaseerd zijn. Je zou kunnen zeggen dat de klasse een fabriekje is dat objecten kan maken. Echter, wanneer we het static keyword zullen bespreken gaan we ontdekken dat heel af en toe een klasse ook als een soort object door het leven kan gaan. "
Laat ik hier eens dieper op ingaan: Je hebt het keyword static al een paar keer zien staan aan de start van methodesignaturen. Maar vanaf hoofdstuk 9 werd er dan weer nadrukkelijk verteld géén static voor methoden in klassen te plaatsen. Wat is het nu?
Bij klassen en objecten duidt static aan dat een methode of variabele "gedeeld" wordt over alle objecten van die klasse. Wanneer je static ergens voorplaatst dan kan je dit element aanroepen zonder dat je een instantie van die klasse nodig hebt.
static kan op verschillende plaatsen in een klasse gebruikt worden:
Bij instantievariabelen om een gedeelde variabele aan te maken, over de objecten heen. We spreken dan niet meer over een instantievariabele maar over een static field.
Bij methoden om zogenaamde methoden-bibliotheken of hulpmethoden aan te maken (denk maar aan Math.Pow() en DateTime.IsLeap()). We spreken dan over een static method.
Bij de klasse zelf om te voorkomen dat er objecten van de klasse aangemaakt kunnen worden (bijvoorbeeld de Console en Math klasse). Je raadt het nooit, maar dit noemt dan een static class. De klasse doet zich dan voor als een uniek object-achtig concept.
Bij properties. We hebben al met 1 static property gewerkt namelijk de readonly property Now van de DateTime klasse (DateTime.Now).
Ook een constructor kan static gemaakt worden, maar dat ga ik in dit boek niet bespreken. Samengevat kan je een static constructor gebruiken indien je een soort oer-constructor wilt hebben die eenmalig wordt aangeroepen wanneer het allereerste object van een klasse wordt aangemaakt. Wanneer een tweede instantie wordt aangemaakt zal de static constructor niet meer aangeroepen worden.
We vereenvoudigen bewust het keyword static wat om verwarring te voorkomen. Het "delen van informatie dankzij static" is een gevolg, niet de reden. Met static geven we eigenlijk aan dat het element bij de klasse zelf behoort én niet bij instanties van die klasse.
Zonder het keyword static heeft ieder object z'n eigen instantievariabelen. Aanpassingen binnen het object aan die variabelen hebben geen invloed op andere objecten van hetzelfde type. Ik toon je eerst de werking zoals je die gewend bent. Vervolgens leg ik uit hoe static in de praktijk werkt.
internal class Mens
{
private int geboorteJaar;
public int Geboortejaar
{
get { return geboorteJaar; }
private set { geboorteJaar = value; }
}
public void Jarig()
{
Geboortejaar++;
}
}
Als we dit doen:
Mens m1 = new Mens();
Mens m2 = new Mens();
m1.Jarig();
m1.Jarig();
m2.Jarig();
Console.WriteLine($"{m1.Geboortejaar}");
Console.WriteLine($"{m2.Geboortejaar}");
Dan zien we volgende uitvoer:
2
1
Ieder object houdt de stand van z'n eigen variabelen bij. Ze kunnen elkaars interne - zowel publieke als private - staat niet rechtstreeks veranderen.
Laten we eens kijken wat er gebeurt indien we een instantievariabele static maken.
We maken de variabele private int geboorteJaar static als volgt: private static int geboorteJaar = 1;. We krijgen dan:
internal class Mens
{
private static int geboorteJaar = 1;
public int Geboortejaar
{
get { return geboorteJaar; }
private set { geboorteJaar = value; }
}
public void Jarig()
{
Geboortejaar++;
}
}
We hebben er nu voor gezorgd dat ALLE objecten de variabele geboorteJaardelen. Er wordt van deze variabele dus maar één "instantie" in het geheugen aangemaakt.
Voeren we nu terug volgende code uit:
Mens m1 = new Mens();
Mens m2 = new Mens();
m1.Jarig();
m1.Jarig();
m2.Jarig();
Console.WriteLine($"{m1.Geboortejaar}");;
Console.WriteLine($"{m2.Geboortejaar}");;
Dan wordt de uitvoer:
4
4
We zien dat de variabele geboorteJaar dus niet meer per object individueel wordt bewaard, maar dat het één globale variabele als het ware is geworden en géén instantievariabele meer is.
static laat je dus toe om informatie over de objecten heen te delen.
Gebruik static niet te pas en te onpas: vaak druist het in tegen de concepten van OO en wordt het vooral misbruikt.
Ga je dit soort static variabelen -ook wel static fields genoemd - vaak nodig hebben? Niet zo vaak. Het volgende concept daarentegen wel!
Heb je er al bij stil gestaan waarom je dit kan doen:
Math.Pow(3,2);
Zonder dat we objecten moeten aanmaken in de trend van:
Math myMath = new Math(); //dit mag niet!
myMath.Pow(3,2)
De reden dat je de Math-bibliotheek kan aanroepen rechtstreeks op de klasse en niet op objecten van die klasse is omdat de methoden in die klasse als static gedefinieerd staan.
De klasse is op de koop toe ook zelf static gemaakt. Zo kan er zeker geen twijfel bestaan: deze klasse kan niét in een object gegoten worden.
De klasse zal er dus zo ongeveer uitzien:
internal static class Math
{
public static double Pow(int getal, int macht)
{
//enz.
Zoals je hopelijk al merkt zijn er aardig wat keywords die je nog voor methode en klasse-definities kunt plaatsen. Zo zijn er al:
Stel dat we enkele veelgebruikte methoden willen groeperen en deze gebruiken zonder telkens een object te moeten aanmaken dan doen we dit als volgt:
internal static class EpicLibrary
{
static public void ToonInfo()
{
Console.WriteLine("Ik ben ik");
}
static public int TelOp(int a, int b)
{
return a+b;
}
}
We kunnen deze methoden nu als volgt aanroepen:
EpicLibrary.ToonInfo();
int opgeteld = EpicLibrary.TelOp(3,5);
Mooi toch?!
Dankzij static kunnen we dus eigen bibliotheken van methoden én properties aanmaken die we kunnen aanroepen rechtstreeks op de klasse. We kunnen deze aanroepen zonder dat er een instantie van de klasse moet zijn.
Je mag ook hybride klassen maken waarin sommige delen static zijn en andere niet. De DateTime klasse uit het eerste hoofdstuk bijvoorbeeld is zo'n klasse. De meeste dingen gebeurden non-static toch was er ook bijvoorbeeld de static property Now om de huidige tijd terug te krijgen, alsook de IsLeapYear hulpmethode die we rechtstreeks op de klasse DateTime moesten aanroepen:
Even een kort intermezzo dat we in de volgende sectie gaan gebruiken, namelijk de werking van de Debug klasse.
De Debug klasse (die in de System.Diagnostics namespace staat) kan je gebruiken om eenvoudig zaken naar het debug output venster te sturen tijdens het debuggen. Dit is handig om te voorkomen dat je debug informatie steeds naar het console-scherm moet sturen . Het zou niet de eerste keer zijn dat iemand vergeet een bepaalde Console.WriteLine te verwijderen uit het finale product en zo mogelijk gevoelige debug-informatie naar de eindgebruikers lekt.
Volgende code toont een voorbeeld (merk lijn 1 op die vereist is):
using System.Diagnostics;
namespace debugdemo
{
internal class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World! Console");
Debug.WriteLine("Hello World! Debug");
}
}
}
Als je voorgaande code uitvoert in debugger modus, dan zal je enkel de tekst Hello World! Console in je console zien verschijnen. De andere lijn kan je terugvinden in het "Output" venster in Visual Studio:
Mooi zo. Nu we dat hebben bekeken kunnen terug keren naar het gebruik van het static keyword. Of zoals mijn grootvader zaliger altijd zei "goto static!".
In het volgende voorbeeld gebruik ik een static variabele om bij te houden hoeveel objecten (via de constructor met behulp van Debug.WriteLine ) er van de klasse reeds zijn aangemaakt:
internal class Fiets
{
private static int aantalFietsen = 0;
public Fiets()
{
aantalFietsen++;
Debug.WriteLine($"Er zijn nu {aantalFietsen} gemaakt");
}
public static void VerminderFiets()
{
aantalFietsen--;
Debug.WriteLine($"STATIC: Er zijn {aantalFietsen} fietsen");
}
}
Merk op dat we de methode VerminderFiets enkel via de klasse kunnen aanroepen daar deze static werd gemaakt. We kunnen echter nog steeds Fiets-objecten aanmaken aangezien de klasse zelf niet static werd gemaakt.
Laten we de uitvoer van volgende code eens bekijken:
Fiets merckx = new Fiets();
Fiets steels = new Fiets();
Fiets evenepoel = new Fiets();
Fiets.VerminderFiets();
Fiets aerts = new Fiets();
Fiets.VerminderFiets();
Dit zal debug uitvoer geven:
Er zijn nu 1 gemaakt
Er zijn nu 2 gemaakt
Er zijn nu 3 gemaakt
STATIC:Er zijn 2 fietsen
Er zijn nu 3 gemaakt
STATIC:Er zijn 2 fietsen
Van zodra je een methode hebt die static is dan zal deze methode enkel andere static methoden en variabelen kunnen aanspreken. Dat is logisch: een static methode heeft geen toegang tot de gewone niet-statische variabelen van een individueel object, want welk object zou hij dan moeten benaderen? Het omgekeerde kan nog wel natuurlijk.
Volgende code zal dus een fout geven:
internal class Mens
{
private int gewicht = 50;
private static void VerminderGewicht()
{
gewicht--;
}
}
De foutboodschap die verschijnt "An object reference is required for the non-static field, method, or property 'Program.Mens.gewicht'" zal bij lijn 7 staan.
Volgende vereenvoudiging maakt duidelijk wat kan aangeroepen worden en wat niet:
Een eenvoudige regel is te onthouden dat van zodra je in een staticomgeving bent, je niet meer naar de niet-static delen van je code zal geraken.
Dit verklaart ook waarom je bij console applicaties in Program.cs steeds alle methoden static moet maken. De Main van een console-applicatie is namelijk als volgt beschreven:public static void Main(){}.
Zoals je ziet is de Main methode als static gedefinieerd. Willen we dus vanuit deze methode andere methoden aanroepen dan moeten deze als static aangeduid zijn..
Beeld je in dat je een pong-variant moet maken waarbij meerdere balletjes over het scherm moeten botsen. Je wilt echter niet dat de balletjes zelf allemaal apart moeten weten wat de grenzen van het scherm zijn. Mogelijk wil je bijvoorbeeld dat je code ook werkt als het speelveld kleiner is dan het eigenlijke Console-scherm.
We gaan dit oplossen met een static property waarin we de grenzen voor alle balletjes bijhouden. Aan onze klasse Balletje voegen we dan alvast het volgende toe:
static public int Breedte { get; set; }
static public int Hoogte { get; set; }
In ons hoofdprogramma (Main) kunnen we nu de grenzen voor alle balletjes tegelijk vastleggen:
Maar even goed maken we de grenzen voor alle balletjes gebaseerd op zelf gekozen waarden:
Balletje.Hoogte = 20;
Balletje.Breedte = 10;
We zouden zelfs de grenzen van het veld dynamisch kunnen maken en laten afhangen van het huidige level.
De interne werking van de balletjes hoeft dus geen rekening meer te houden met de grenzen van het scherm. We passen de Update-methode aan, rekening houdend met deze nieuwe kennis:
public void Update()
{
if (X + VX >= Balletje.Breedte || X + VX < 0)
{
VX = -VX;
}
X = X + VX;
if (Y + VY >= Balletje.Hoogte || Y + VY < 0)
{
VY = -VY;
}
Y = Y + VY;
}
En nu kunnen we vlot balletjes laten rond bewegen op bijvoorbeeld een klein deeltje maar van het scherm:
Je zal static minder vaak nodig hebben dan non-static zaken. Alhoewel: wanneer je werkt met een klasse waarin je een Random-number generator gebruikt, dan is het een goede gewoonte deze generator static te maken zodat alle objecten deze ene generator gebruiken. Anders bestaat de kans dat je objecten dezelfde random getallen zullen aanmaken wanneer ze toevallig op quasi hetzelfde moment werden geïnstantieerd of methoden in aanroept.
Test maar eens wat er gebeurt als je volgende klasse hebt:
internal class Dobbelsteen
{
public int Werp()
{
Random gen = new Random(); //SLECHT IDEE!
return gen.Next(1,7);
}
}
Wanneer je nu dezelfde dobbelsteen 10 maal snel na elkaar rolt is de kans groot dat je geregeld dezelfde getallen gooit:
Dobbelsteen testDobbel = new Dobbelsteen();
for(int i = 0 ; i < 10; i++)
{
Console.WriteLine(testDobbel.Werp());
}
De reden? Een nieuw aangemaakt Random-object gebruikt de tijd waarop het wordt aangemaakt als een zogenaamde seed. Een seed zorgt ervoor dat je dezelfde reeks getallen kan genereren wanneer de seed dezelfde is -een concept dat nuttig is in cryptografie. Uiteraard willen we dat niet bij een dobbelsteen. Het is niet omdat een dobbelsteen snel na elkaar wordt geworpen (of aangemaakt) dat die dobbelsteen dan regelmatig dezelfde getallen na elkaar gooit.
We lossen dit op door de generator static te maken zodat er maar één generator bestaat die alle dobbelstenen en hun methoden delen. Dit is erg eenvoudig opgelost: je verhuist je generator naar buiten de methode en plaatst er static voor:
internal class Dobbelsteen
{
static Random gen = new Random();
public int Werp()
{
return gen.Next(1,7);
}
}
Arrays van value types kwamen we al in hoofdstuk 8 tegen. In dit hoofdstuk demonstreer ik dat ook arrays van objecten perfect mogelijk zijn. We weten reeds dat klassen niets meer dan zijn dan nieuwe datatypes. Het is dus ook logisch dat wat we reeds met arrays konden, we dit kunnen blijven doen met objecten.
Maar, er is één grote maar: omdat we met objecten werken moeten we rekening houden met het feit dat de individuele objecten in je array reference values hebben en dus mogelijk null zijn. Met andere woorden: het is van essentiëel belang dat je het hoofdstuk rond geheugenmanagement in C# goed begrijpt, want we gaan het geregeld nodig hebben.
Na Exceptions is het weer tijd voor een andere bekentenis: arrays zijn fijn, maar nogal omslachtig qua gebruik. Er zit echter in .NET een soort array on steroids datatype dat ons nooit nog zal doen teruggrijpen naar arrays. Welke dat zijn? Lees verder en ontdek het zelf!
De new zorgt er echter enkel voor dat er een referentie naar een nieuwe array wordt teruggegeven, waar ooit 20 studenten-objecten in kunnen komen. Maar: er staan nog géén objecten in deze array. Alle elementen in deze array zijn nu nog null.
Willen we nu elementen in deze array plaatsen dan moeten we dit ook expliciet doen en moeten we dus objecten aanmaken en hun referentie in de array bewaren:
mijnKlas[0] = new Student();
mijnKlas[2] = new Student();
Uiteraard kan dit ook in een loop indien relevant voor de opgave. Volgende voorbeeld vult een reeds aangemaakte array met evenveel objecten als de arrays groot is:
for(int i = 0; i < mijnKlas.Length; i++)
{
mijnKlas[i] = new Student();
}
Van zodra een object in de array staat kan je deze vanuit de array aanspreken door middel van de index en de dot-operator om de de juiste methode of property op het object aan te roepen:
mijnKlas[3].Name = " Duke Peekaboo";
Uiteraard mag je ook altijd de referentie naar een individueel object in de array kopiëren. Denk er aan dat we de hele tijd met referenties werken en de GC dus niet tussenbeide zal komen zolang er minstens 1 referentie naar het object is. Indien de student op plek 4 in de array aan de start een geboortejaar van 1981 had, dan zal deze op het einde van volgende code als geboortejaar 1983 hebben, daar we op hetzelfde objecten het geboortejaar verhogen in zowel lijn 2 als 3:
Je kan ook een variant op de object initializer syntax gebruiken waarbij de objecten reeds van bij de start in de array worden aangemaakt. Als bonus zorgt dit er ook voor dat we geen lengte moeten meegeven, de compiler zal deze zelf bepalen.
Volgende voorbeeld maakt een nieuwe array aan die bestaat uit 2 nieuwe studenten, alsook 1 bestaande met de naam jos:
Student jos = new Student();
//...
Student[] mijnKlas = new Student[]
{
new Student(),
new Student(),
jos
};
Let op de puntkomma helemaal achteraan. Die wordt als eens vergeten.
Het kan niet genoeg benadrukt worden dat een goede kennis van de heap, stack en referenties essentieel is om te leren werken met arrays van objecten. Uit voorgaande stukje code zien we duidelijk dat een goed inzicht in referenties je van veel leed beschermen. Bekijk eens de eindsituatie van voorgaande code:
Zoals je merkt zal nu de student jos niet verwijderd worden indien we op gegeven moment schrijven jos = null daar het object nog steeds bestaat via de array. We kunnen met andere woorden op 2 manieren de student jos momenteel bereiken, via de array of via jos:
Ook arrays mag je als parameters en returntype gebruiken in methoden. De werking hiervan is identiek aan die van value-types zoals volgende voorbeeld toont. Eerst maken we een methode die als resultaat een referentie naar een lege array van 10 studenten teruggeeft.
static Student[] CreateEmptyStudentArray()
{
return new Student[10];
}
Vervolgens kunnen we deze dan aanroepen en het resultaat (de referentie naar de lege array) toewijzen aan een nieuwe variabele (van hetzelfde datatype, namelijk Student[]):
Een List<>-collectie is de meest standaard collectie die je kan beschouwen als een veiligere variant op een doodnormale array. Een List heeft alle eigenschappen die we al kennen van arrays, maar ze zijn wel krachtiger. Het giet een klasse "rond" het concept van de array, waardoor je toegang krijgt tot een hoop nuttige methoden die het werken met arrays vereenvoudigen.
De klasse List<> is een generieke klasse. Tussen de < >tekens plaatsen we het datatype dat de lijst zal moeten gaan bevatten. Bijvoorbeeld:
List<int> alleGetallen = new List<int>();
List<bool> binaryList = new List<bool>();
List<Pokemon> pokeDex = new List<Pokemon>();
List<string[]> listOfStringarrays = new List<string[]>();
Zoals je ziet hoeven we bij het aanmaken van een List geen begingrootte mee te geven, wat we wel bij arrays moeten doen. Dit is één van de voordelen van List: ze groeien mee.
In dit boek behandel ik het concept generieke klassen enkel in de appendix.
Generieke klassen oftewel generic classes zijn een handig concept om je klassen nog multifunctioneler te maken doordat we zullen toelaten dat bepaalde datatypes niet hardcoded in onze klasse moet gezet worden. List<> is zo'n eerste voorbeeld, maar er zijn er tal van anderen én je kan ook zelf dergelijke klassen schrijven. Bekijk zeker de appendix indien je dit interesseert.
De generieke List<> klasse bevindt zich in de System.Collections.Generic namespace. Je dient deze namespace dus als using bovenaan toe te voegen wil je deze klasse kunnen gebruiken in C# 9.0 en ouder.
Via de Add()-methode kan je elementen toevoegen aan de lijst. Je dient als parameter aan de methode mee te geven wat je aan de lijst wenst toe te voegen. Deze parameter moet uiteraard van het type zijn dat de List verwacht.
In volgende voorbeeld maken we een List aan die objecten van het type string mag bevatten en vervolgens plaatsen we er twee elementen in.
List<string> mijnPersonages = new List<string>();
mijnPersonages.Add("Reinhardt");
mijnPersonages.Add("Mercy");
Ook meer complexe datatypes kan je dus toevoegen:
List<Pokemon> pokedex = new List<Pokemon>();
pokedex.Add(new Pokemon());
Via object syntax initializer kan dit zelfs nog sneller:
List<Pokemon> pokedex = new List<Pokemon>()
{
new Pokemon(),
new Pokemon()
};
Je kan ook een stap verder gaan en ook binnenin deze initializer syntax dezelfde soort initialize syntax gebruiken om de objecten individueel aan te maken:
List<Pokemon> pokedex = new List<Pokemon>()
{
new Pokemon() {Naam = "Pikachu", HP_Base = 5},
new Pokemon() {Naam = "Bulbasaur", HP_Base = 15}
};
Het leuke van een List is dat je deze ook kan gebruiken als een gewone array, waarbij je met behulp van de indexer elementen individueel kan aanroepen. Stel bijvoorbeeld dat we een lijst hebben met minstens 4 strings in. Volgende code toont hoe we de string op positie 3 kunnen uitlezen en hoe we die op positie 2 overschrijven, net zoals we reeds kenden van arrays:
Clear(): methode die de volledige lijst leegmaakt en de lengte (Count) terug op 0 zet.
Insert(): methode om een element op een specifieke plaats in de lijst in te voegen.
IndexOf(): geeft de index terug van het element item in de rij. Indien deze niet in de lijst aanwezig is dan wordt -1 teruggegeven.
RemoveAt(): verwijdert een element op de index die je als parameter meegeeft.
Sort(): alle elementen in de lijst worden gesorteerd. Merk op dat dit niet altijd werkt zoals je verwacht. Lees zeker in hoofdstuk 17 de sectie omtrent "Interfaces in de praktijk" eerst voor je probeert een lijst van eigen objecten te sorteren.
Let op met het gebruik van IndexOf en objecten. Deze methode zal controleren of de referentie dezelfde is van een bepaald object en daar de index van teruggeven. Je kan deze methode dus wel degelijk met arrays van objecten gebruiken, maar je zal enkel je gewenste object terugvinden indien je reeds een referentie naar het object hebt en dit meegeeft als parameter.
Ikzelf ben fan van List. Het maakt je code vaak leesbaarder dan arrays. Voorts geeft het je de optie om dynamisch groeiende (en krimpende) arrays te hebben, zonder dat je daar veel boilerplate code voor moet schrijven. Herinner je onze Pong-code waarin we 100 balletjes op het scherm lieten vliegen?
const int AANTAL_BALLETJES = 100;
Random r = new Random();
Balletje[] veelBalletjes = new Balletje[AANTAL_BALLETJES];
for (int i = 0; i < veelBalletjes.Length; i++) //balletjes aanmaken
{
veelBalletjes[i] = new Balletje();
veelBalletjes[i].X = r.Next(10, 20);
veelBalletjes[i].Y = r.Next(10, 20);
veelBalletjes[i].VX = r.Next(-2, 3);
veelBalletjes[i].VY = r.Next(-2, 3);
}
while (true)
{
for (int i = 0; i < veelBalletjes.Length; i++)
{
veelBalletjes[i].Update(); //update alle balletjes
}
for (int i = 0; i < veelBalletjes.Length; i++)
{
veelBalletjes[i].TekenOpScherm(); //teken alle balletjes
}
System.Threading.Thread.Sleep(50);
Console.Clear();
}
Vooral de code in de while wordt nu leesbaarder dankzij List<Balletje> (we gaan ook ineens gebruik maken van onze nieuwe default constructor die de random startwaarde instelde):
const int AANTAL_BALLETJES = 100;
List<Balletje> veelBalletjes = List<Balletje>();
for (int i = 0; i < AANTAL_BALLETJES; i++) //balletjes aanmaken
{
veelBalletjes.Add(new Balletje());
}
while (true)
{
foreach(var bal in veelBalletjes)
{
bal.Update(); //update alle balletjes
}
foreach(var bal in veelBalletjes)
{
bal.TekenOpScherm(); //teken alle balletjes
}
System.Threading.Thread.Sleep(50);
Console.Clear();
}
Deze code zou je aan iemand die geen C# kan kunnen tonen en met een beetje geluk zal die de code begrijpen. Dat is het fijne van hogere programmeertalen zoals C#: ze zijn veel leesbaarder dan talen die dichter tegen het metaal zitten, zoals C en C++.
Als leuke extra bij C# is dat het een erg levende taal is. Jaarlijks komen er nog nieuwe concepten bij. Meestal zijn die ietwat obscuur, maar vaak maken ze de code wel een pak leesbaarder dan ervoor. Alhoewel ik graag werk met arrays, zorgen Lists er bijvoorbeeld voor dat we veel minder met vierkante haakjes moeten werken én verstoppen ze een hoop code om bijvoorbeeld lijsten te doen groeien en krimpen.
Dit verstoppen kan uiteraard soms een probleem zijn indien je hoog-performante code moet schrijven. Aan de andere kant: denk je dat jij betere code kunt schrijven dan de ontwikkelaars van de Add-methode bij List?
In het hoofdstuk over loops besprak ik reeds de while, do while en for-loops. Er is echter een vierde soort loop in C# die vooral zijn nut zal bewijzen wanneer we met arrays van objecten werken: de foreach loop.
Wanneer je geen indexering nodig hebt, maar wel over alle elementen in een array wenst te gaan, dan is de foreach loop nuttig.
Een foreach loop zal ieder element in de array één voor één in een tijdelijke variabele plaatsen (de iteration variable). Vervolgens kan binnenin de loop iedere iteratie met die iteration variabele gewerkt worden. Het voordeel hierbij is dat je geen teller nodig hebt en dat de loop zelf de lengte van de array zal bepalen: je code wordt net iets leesbaarder. Zeker als we dit bijvoorbeeld vergelijken met hoe een for loop geschreven is.
Volgende code toont de werking waarbij we een double-array hebben en alle elementen ervan op het scherm willen tonen:
Het belangrijkste nieuwe concept is de iteration variable die we hier definiëren als meting. Deze moet van het type zijn van de individuele elementen in de array. De naam die je aan de iteration variabele geeft mag je zelf kiezen. Vervolgens schrijven we het nieuwe keyword in gevolgd door de array waar we over wensen te itereren.
De eerste keer dat we in de loop gaan, zal het element metingen[0] aan meting toegewezen worden voor gebruik in de loop-body. Vervolgens wordt metingen[1] toegewezen, enz.
De output zal dan zijn:
1.2
0.89
3.15
0.1
Stel dat we een array van Studenten hebben, deKlas, en wensen van deze studenten de naam en geboortejaar op het scherm te tonen. Ook dit kan dan met een foreach erg eenvoudig:
foreach (Student student in deKlas)
{
Console.WriteLine($"{student.Naam}, {student.Geboortejaar}");
}
Merk op dat al deze voorbeelden ook met een List in plaats van een array werken.
De foreach loop is weliswaar leesbaarder en eenvoudiger in gebruikt, er zijn ook 3 erg belangrijke nadelen aan:
De foreach iteration variabele is read-only: je kan dus geen waarden in de array aanpassen, enkel uitlezen. Dit ogenschijnlijk eenvoudige zinnetje heeft echter veel gevolgen. Je kan met een foreach-loop dus nooit de inhoud van de variabele aanpassen (lees zeker de waarschuwing hieronder). Wens je dat wel te doen, dan dien je de klassieke while, do while of for loops te gebruiken.
De foreach loop gebruik je enkel als je alle elementen van een array wenst te benaderen. In alle andere gevallen zal je een ander soort loop moeten gebruiken (daar ik geen fan van break ben).
Voorts heb je geen teller (die je gratis bij een for krijgt) om bij te houden hoeveel objecten je al hebt benaderd. Heb je dus een teller nodig dan zal je deze manueel moeten aanmaken zoals je ook bij een while en do while loop moet doen.
Het feit dat de foreach iteration variabele read-only is wil niet zeggen dat we de inhoud van het onderliggend object niet kunnen aanpassen. De iteration variabele krijgt bij een array van objecten telkens een referentie naar het huidige element. Deze referentie kunnen we niet aanpassen, maar we mogen wel de referentie "volgen" om vervolgens iets in het huidige object zelf aan te passen.
Dit mag dus niét:
foreach (Student eenStudent in deKlas)
{
eenStudent = new Student();
}
Maar dit mag wél:
foreach (Student eenStudent in deKlas)
{
eenStudent.Geboortejaar++;
}
Met de VS snippet foreach gevolgd door twee maal op de tab-toets te duwen krijg je een kant-en-klare foreach loop.
C# heeft een var keyword. Je mag dit keyword gebruiken ter vervanging van het datatype op voorwaarde dat de compiler kan achterhalen wat het type (implicit type) moet zijn. De compiler kan het type ontdekken aan de hand van de expressie rechts van de toekenningsoperator.
var getal = 5; //var zal int zijn
var myArray = new double[20]; //var zal double[] zijn
var tekst = "Hi there handsome"; //var zal string zijn
var ikke = new Leerkracht(); //var zal Leerkracht zijn
Opgelet: het var keyword is gewoon een lazy programmer syntax toevoeging om te voorkomen dat je als programmeur niet constant het type moet schrijven.
Bij JavaScript heeft var een totaal andere functie, daar zegt het eigenlijk: "het type dat je in deze variabele kan steken is...variabel". Met andere woorden, het kan de ene keer string zijn, dan int, enz.
Bij C# gaat dit niet: eens je een variabele aanmaakt dan zal dat type onveranderbaar zijn en kan je er alleen waarden aan toekennen van dat type.
JavaScript is namelijk een dynamically typed language. C# is daarentegen een statically typed language. Er is één uitzondering bij C#: wanneer je met dynamic leert werken kan je C# ook tijdelijk als een dynamically typed taal gebruiken (maar dat wordt niet besproken in dit boek).
Wanneer je de Visual Studio code snippet voor foreach gebruikt (foreach [tab][tab]) dan zal deze code ook een var gebruiken voor de iteration variabele. De compiler kan aan de te gebruiken array of List zien wat het type van een individueel element in de array moet zijn.
De foreach die we zonet gebruikten kan dus herschreven worden naar:
foreach (var student in deKlas)
{
Console.WriteLine($"{student.Naam}, {student.Geboortejaar}");
}
Merk op dat dit hoegenaamd geen invloed heeft op je applicatie. Wanneer je code gaat compileren die het keyword var bevatten dan zal de compiler eerst alle vars vervangen door het juiste type, én dan pas beginnen compileren.
Naast de generieke List collectie, zijn er nog enkele andere nuttige generieke 'collectie-klassen' die je geregeld in je projecten kan gebruiken. We bespreken nu de Dictionary, Queue en Stack-collecties.
Een queue (uitgesproken als kjioe) stelt een "first in, first out"-lijst (FIFO) voor. Een Queue stelt de rijen voor die we in het echte leven ook hebben wanneer we bijvoorbeeld aanschuiven aan een ticketverkoop of in de supermarkt. Met deze klasse kunnen we zo’n rij simuleren en ervoor zorgen dat steeds het eerste/oudste element in de rij als eerste wordt behandeld. Nieuwe elementen worden achteraan de rij toegevoegd.
We gebruiken onder andere volgende 2 methoden1 om met een Queue-lijst te werken:
Enqueue(T item): Voeg een item achteraan de lijst toe.
Dequeue(): geeft een referentie naar het eerste element in de queue terug en verwijdert dit vervolgens.
Voorbeeld:
Queue<string> wachtrij = new Queue<string>();
wachtrij.Enqueue("Ik stond hier eerste.");
wachtrij.Enqueue("Ik tweedes.");
wachtrij.Enqueue("Ik laatste.");
Console.WriteLine(wachtrij.Dequeue());
Console.WriteLine(wachtrij.Dequeue());
Dit zal op het scherm tonen:
Ik stond hier eerste.
Ik tweedes.
1
Een andere interessante methode is Peek(): hiermee kunnen we kijken in de queue wat het eerste element is, zonder het te verwijderen.
Daar waar een queue "first in,first out" is, is een stack "last in,first out" (LIFO). Met andere woorden het recentst toegevoegde element zal steeds vooraan staan en als eerste verwerkt worden. Je kan dit vergelijken met een stapel papieren waar je steeds bovenop een nieuw papier legt.
Ook de klasse Stack heeft verschillende methoden, waarvan volgende 2 methoden het interessantst zijn:
Push(T item): plaats een nieuw element bovenop de stapel.
Pop(): geeft het bovenste element in de stack terug en verwijdert dit vervolgens.
Voorbeeld:
Stack<string> stapel = new Stack<string>();
stapel.Push("Ik was eerste hier.");
stapel.Push("Ik tweede.");
stapel.Push("Ik als laatste.");
Console.WriteLine(stapel.Pop());
Console.WriteLine(stapel.Pop());
In een dictionary wordt ieder element voorgesteld door een sleutel (key of index) en een waarde (value).
De sleutel moet een unieke waarde zijn zodat het element kan opgevraagd worden uit de dictionary aan de hand van deze sleutel zonder dat er duplicaten zijn.
Bij de declaratie van de Dictionary dien je op te geven wat het datatype van de key zal zijn, alsook het type van de waarde (value).
De Dictionary-klasse emuleert dus letterlijk de werking van een woordenboek, waarbij ieder woord uniek is en een bijhorende uitleg heeft. Het woord is de sleutel, de bijhorende uitleg is de waarde.
In het volgende voorbeeld maken we een Dictionary van klanten aan. Iedere klant heeft een unieke ID (de key is van het type int) alsook een naam (die niet noodzakelijk uniek is en de waarde voorstelt):
Dictionary<int, string> klanten = new Dictionary<int, string>();
klanten.Add(123, "Tim Dams");
klanten.Add(6463, "James Bond");
klanten.Add(666, "The beast");
klanten.Add(700, "James Bond");
Bij de declaratie van klanten plaatsen we dus tussen de < > twee datatypes: het eerste duidt het datatype van de key aan, het tweede dat van de values.
We kunnen een specifiek element opvragen aan de hand van de key. Stel dat we de waarde (naam) van de klant met key (id) gelijk aan 123 willen tonen, dan schrijven we:
Console.WriteLine(klanten[123]);
We kunnen nu met behulp van bijvoorbeeld een foreach-loop alle elementen tonen. Hier kunnen we de key met de .Key-property uitlezen en het achterliggende object of waarde met .Value. Value en Key hebben daarbij ieder het type dat we hebben gedefinieerd toen we het Dictionary-object aanmaakten, in het volgende geval is de Key dus van het type int en Value van het type string:
foreach (var item in klanten)
{
Console.WriteLine(item.Key+ "\t:"+item.Value);
}
De key werkt dus net als de index bij gewone arrays. Alleen heeft de key nu geen relatie meer met de positie van het element in de collectie, maar is een unieke identifier van het element in kwestie.
De key kan zelfs een string zijn en de waarde een ander type. In het volgende voorbeeld hebben we eerder een klasse Student aangemaakt. We maken nu een student aan en voegen deze toe aan de studentenLijst. Vervolgens willen we het geboortejaar van een bepaalde student tonen op het scherm en vervolgens verwijderen we deze student:
var studentenLijst = new Dictionary<string, Student>();
Student stud = new Student() { Naam = "Tim", Geboortejaar = 2001 };
studentenLijst.Add("AB12", stud);
Console.WriteLine(studentenLijst["AB12"].Geboortejaar);
studentenLijst.Remove("AB12");
Lijn1 is zo'n typisch voorbeeld waar het gebruik van het keyword var effectief een meerwaarde heeft. Het zorgt ervoor dat de code mooi op 1 lijn past en leesbaar blijft.
Het wordt tijd om de derde letter in het acroniem A PIE aan te pakken. We hadden reeds abstractie en encapsulatie bekeken. Nu is het de beurt aan inheritance, oftewel overerving.
Programmeurs zijn luie wezens. Ieder concept dat hen toelaat minder code te schrijven zullen ze dan ook omarmen. Dubbele code wil namelijk ook zeggen dat er dubbel zoveel plekken zijn waar bugs kunnen optreden én die aangepast moeten worden wanneer de specificaties veranderen.
Indien 2 of meer klassen een aantal gelijkaardige stukken code hebben is er mogelijk een verband tussen die twee klassen. Denk maar aan de klassen Monster en Held in een avonturenspel. Beide klassen hebben vermoedelijk bepaalde properties en methoden die identiek, of bijna identiek zijn qua implementatie.
Wat we hier zien is het concept overerving. Beide klassen hebben duidelijk een soort gemeenschappelijke "voorouder". Net zoals in de natuur waar apen en mensen afstammen van een gemeenschappelijke voorouder, kan je dit concept ook in OOP hebben.
De zogenaamde "child-klasse" is de klasse die overerft van een "parent-klasse". Deze child-klasse zal een specialisatie zijn: het zal meer kunnen dan z'n parent. Ook in de natuur zien we dit. De homo sapiens sapiens (wij!) is evolutionair gezien een verbetering tegenover de homo erectus (kleinere hersenen). De homo erectus is op zijn beurt een verbetering van zijn voorouder: de homo habilis kon nog niet op 2 ledematen rondwandelen.
Kijken we terug naar Monster en Held dan is het duidelijk dat een gemeenschappelijke parent-klasse misschien wel de klasse Karakter is.
Dankzij overerving kunnen we de gemeenschappelijk code van de child-klassen verhuizen naar deze parent-klasse. De child-klassen zullen enkel nog de code bevatten die uniek is voor hen: de code die de specialisatie beschrijft.
Deze introductie doet uitschijnen dat overerving enkel z'n nut heeft om dubbele code te vermijden, wat niet zo is. Dubbele code vermijden via overerving is eerder een gevolg ervan. Overerving is een erg krachtig concept dat in de komende hoofdstukken telkens zal terugkomen bij polymorfisme, interfaces, enz.
Overerving (inheritance) laat ons toe om klassen te specialiseren vanuit een reeds bestaande parent- of basisklasse. Wanneer we een klasse van een andere klasse overerven dan zeggen we dat deze nieuwe klasse een child-klasse of sub-klasse is van de bestaande parent-klasse of super-klasse.
De child-klasse kan alles wat de parent-klasse kan, maar de nieuwe klasse kan nu ook extra specialisatie-code krijgen.
Wanneer twee klassen met behulp van een "x is een y"-relatie kunnen beschreven worden dan weet je dat overerving mogelijk is.
Een paard is een dier. Het paard is child-klasse. Dier is parent-klasse.
Een tulp is een plant.
Zowel een dier als een plant zijn levende wezens.
Als je dus in een programmeeropdracht het werkwoord zijn tegenkomt - was, is, zijn, zal zijn, enz. - dan is de kans groot dat overerving mogelijk is. Ik ga echter dit idee verderop in het boek uitbreiden met interfaces en polymorfisme. Deze twee begrippen hangen nauw samen met overerving en zullen soms een "betere oplossing" zijn dan pure overerving.
Wanneer we "x heeft een y" zeggen gaat het niet over overerving, maar over een associatie (zoals compositatie of aggregatie) wat ik in het volgende hoofdstuk zal uitleggen.
Het is niet omdat 2 klassen delen gelijkaardige (of dezelfde) code hebben dat hier dus automatisch overerving van toepassing is. Enkel indien er een realistische "is een"-relatie bestaat kan overerving toegepast worden.
Overerving in C# duid je aan met behulp van het dubbele punt(:) bij de klassedefinitie, als volgt:
internal class Paard : Dier
{
public bool KanHinnikken{get;set;}
}
internal class Dier
{
public void Eet()
{
//...
}
}
We zeggen dus dat Paard overerft van de klasse Dier. Het paard is dus een specialisatie van dier. Objecten van het type Dier kunnen enkel de Eet-methode aanroepen. Objecten van het type Paard kunnen de Eet-methode aanroepen én ze hebben ook een property KanHinnikken. Een paard kan dus alles wat een dier kan en wat het zelf kan. Een dier kan enkel wat het zelf kan:
Dier aDier = new Dier();
Paard bPaard = new Paard();
aDier.Eet();
bPaard.Eet();
bPaard.KanHinnikken = false;
aDier.KanHinnikken = false; //!!! zal niet werken!
Overerving in C# is transitief. Dit wil zeggen dat de child-klasse ALLES overerft van de parent-klasse: methoden, properties, enz.
Dit kleine, korte zinnetje herbergt aardig wat kracht. Dankzij overerving kunnen we onze klasse dus proper en kort houden indien er een "is een" relatie bestaat. Er zijn echter ook enkele kanttekeningen aangaande overerving die ik in de komende secties uit te doeken zal doen.
Alhoewel overerving transitief is, wil dat niet zeggen dat private variabelen plots zichtbaar zijn in de child-klasse. De child-klasse erft ook de private instantievariabelen over, maar C# houdt zich wel aan de regels en zal voorkomen dat de child-code aan deze private parent instantievariabelen kan.
Tijd om eens te kijken hoe het voorgaande er uitziet in de heap en de stack, met een voorbeeld: een applicatie om aan gebouwbeheer te doen.
Beeld je in dat je volgende klassehiërarchie hebt vastgelegd:
Vervolgens maken we van iedere klasse 1 object aan. De objecten in het geheugen (de heap) zullen er dan als volgt uitzien:
Laten we eens 2 objecten aanmaken en kijken wat er in de heap en stack gebeurt:
Huis eenHuis = new Huis();
Villa groteVilla = new Villa();
Dat ziet er dan als volgt uit:
Ook hier zien we duidelijk dat een Villa object alle "code" in zich heeft die zowel in de klasse Villa staat (de specialisatie) alsook die waarvan wordt overgeërfd, Huis. Bijgevolg heeft groteVilla dus ook de "code" van Gebouw "in zich" door de transitiviteits-eigenschap van overerving.
Echter, de private delen van een klasse blijven beperkt tot dat stuk waar de variabele of methode origineel toe hoort. Als er dus in de klasse Huis een variabele private bool heeftDeurbel was, dan zal de code in de klasse Villa daar niet aan geraken:
Ook al is overerving transitief, hou er rekening mee dat private variabelen en methoden van de parent-klasse NIET rechtstreeks aanroepbaar zijn in de child-klasse. private geeft aan dat het element enkel in de klasse zichtbaar is:
internal class Paard: Dier
{
public void MaakOuder()
{
geboortejaar++; // !!! dit zal een error geven!
}
}
internal class Dier
{
private int geboortejaar;
}
Je kan dit oplossen door de protected access modifier te gebruiken in de plaats van private. Met protected geef je aan dat het element enkel zichtbaar is binnen de klasse én binnen child-klassen:
internal class Paard: Dier
{
public void MaakOuder()
{
geboortejaar++; // werkt nu wel
}
}
internal class Dier
{
protected int geboortejaar;
}
Alhoewel protected z'n nut heeft, is het meestal veiliger om alles nog steeds via properties te doen. Je kan dus beter van een property met private set er één met protected set van maken, zodat de achterliggende instantievariabele beschermd blijft.
In C# is het niet mogelijk om een klasse van meer dan één parent-klasse te laten overerven (zogenaamde multiple inheritance). Dit is wel mogelijk in sommige andere object georiënteerde talen. Het is in C# dus niet mogelijk om een klasse Mens te maken die tegelijkertijd overerft van de klasse Aap en van Tekening.
Als puntje bij paaltje komt zal je trouwens bijna nooit multiple inheritance in de echte wereld tegenkomen (het typische tegenvoorbeeld is het vogelbekdier...maar hoe vaak ga je dat moeten modelleren in een project). Vaker zullen compositie en interfaces de oplossing zijn voor je probleem: 2 essentiële OOP aspecten die ik in de volgende hoofdstukken uit de doeken zal doen.
Wanneer je een object instantiëert van een child-klasse dan gebeuren er meerdere zaken na elkaar, in volgende volgorde:
Eerst wordt de constructor aangeroepen van de basis-klasse.
Gevolgd door de constructors van alle parent-klassen.
Finaal de constructor van de klasse zelf.
Dit is logisch: de child-klasse heeft de "fundering" nodig van z'n parent-klasse om te kunnen werken.
Volgende voorbeeld toont dit in actie:
internal class Soldaat
{
public Soldaat()
{
Debug.WriteLine("Soldaat is aangemaakt.");
}
}
internal class VeldArts : Soldaat
{
public VeldArts()
{
Debug.WriteLine("Veldarts is aangemaakt.");
}
}
Indien je vervolgens een object aanmaakt van het type VeldArts:
VeldArts RexGregor = new VeldArts();
Dan zien we de volgorde van constructor-aanroep in het debug output venster:
Soldaat is aangemaakt.
Veldarts is aangemaakt.
Er wordt dus verondersteld in dit geval dat er een default constructor in de basis-klasse aanwezig is.
Indien je klasse Soldaat een overloaded constructor heeft, dan wisten we al dat deze niet automatisch een default constructor heeft. Volgende code zou dus een probleem geven indien je een VeldArts wilt aanmaken via new VeldArts():
internal class Soldaat
{
public Soldaat(bool kanSchieten)
{
//Doe soldaten dingen
}
}
internal class VeldArts:Soldaat
{
public VeldArts()
{
Debug.WriteLine("Veldarts is aangemaakt.");
}
}
Wat je namelijk niet ziet bij child-klassen en hun constructors is dat er eigenlijk een impliciete aanroep naar de constructor van de parent-klasse wordt gedaan. Bij alle constructors staat er eigenlijk :base() achter, wat je ook zelf kunt schrijven:
internal class VeldArts:Soldaat
{
public VeldArts(): base()
{
Debug.WriteLine("Veldarts is aangemaakt.");
}
}
Door base() achter de constructor te zetten ze je: "roep de default constructor van de parent-klasse aan". Je mag hier echter ook parameters meegeven en de compiler zal dan zoeken naar een overloaded constructor in de basis-klasse die deze volgorde van parameters kan accepteren.
We zien hier hoe we ervoor moeten zorgen dat we terug via new VeldArts() objecten kunnen aanmaken zonder dat we de constructor(s) van Soldaat moeten aanpassen:
internal class Soldaat
{
public Soldaat(bool kanSchieten)
{
//Doe soldaten dingen
}
}
internal class VeldArts:Soldaat
{
public VeldArts():base(true)
{
Debug.WriteLine("Veldarts is aangemaakt.");
}
}
De default constructor van VeldArts zal de actuele parameter kanSchieten steeds op true zetten.
Uiteraard wil je misschien kunnen meegeven bij het aanmaken van een VeldArts wat de startwaarde van kanSchieten moet zijn. Dit vereist dat je een overloaded constructor in VeldArts aanmaakt, die op zijn beurt de overloaded constructor van Soldaat aanroept.
Je schrijft dan een overloaded constructor in VeldArts bij:
internal class Soldaat
{
public Soldaat(bool kanSchieten)
{
//Doe soldaten dingen
}
}
internal class VeldArts:Soldaat
{
public VeldArts(bool kanSchieten): base(kanSchieten)
{}
public VeldArts():base(true) //Default
{
Debug.WriteLine("Veldarts is aangemaakt.");
}
}
Merk op hoe we de formele parameter kanSchieten doorgeven als actuele parameter aan base-aanroep.
Uiteraard mag je ook de default constructor aanroepen vanuit de child-constructor. Alle combinaties zijn mogelijk, zolang de constructor in kwestie maar bestaat in de parent-klasse.
Een hybride aanpak is ook mogelijk. Volgend voorbeeld toont 2 klassen, Huis en Gebouw waarbij we de constructor van Huis zodanig beschrijven dat deze bepaalde parameters "voor zich houdt" en andere als het ware doorsluist naar de aanroep van z'n parent-klasse:
internal class Gebouw
{
public int AantalVerdiepingen { get; private set; }
public Gebouw(int verdiepingenIn)
{
AantalVerdiepingen = verdiepingenIn;
}
}
internal class Huis: Gebouw
{
public bool HeeftTuintje { get; private set; };
public Huis(bool heeftTuin, int aantalVer): base(aantalVer)
{
HeeftTuintje = heeftTuin;
}
}
De volgorde waarin alles gebeurt in voorgaande voorbeeld is belangrijk om te begrijpen. Er wordt een hele machine in gang gezet wanneer we volgende korte stukje code schrijven:
Huis eenEigenHuis = new Huis(true,5);
Start: overloaded constructor van Huis wordt opgeroepen.
Nog voor dat deze echter iets kan doen, wordt de formele parameter verdiepingenIn (die de waarde 5 heeft gekregen) doorgegeven als actuele parameter om de constructor van de basis-klasse aan te roepen.
De overloaded constructor van Gebouw wordt dus aangeroepen.
De code van deze constructor wordt uitgevoerd: het aantal verdiepingen van het gebouw/huis wordt ingesteld.
Wanneer het einde van de constructor wordt bereikt, zal er teruggegaan worden naar de constructor van Huis.
Nu wordt de code van de Huis constructor uitgevoerd: HeeftTuintje krijgt de waarde true.
Einde: Finaal keren we terug en staat er nu een gloednieuw object in de heap, wiens geheugenlocatie we kunnen toewijzen aan eenEigenHuis.
Om te voorkomen dat child-klassen zomaar eender welke methode of property van de parent-klasse kunnen aanpassen gaan we de hulp van het virtual keyword inroepen. Standaard is het geen goede gewoonte om de bestaande werking van een klasse in de child-klasse aan te passen: beeld je in dat je een essentieel stuk code aanpast waardoor je hele klasse plots niet meer werkt!
Soms willen we echter kunnen aangeven dat de werking van een property of methode door een child-klassen mag aangepast worden. Dit geven we aan met het virtual keyword.
Vervolgens dient de child-klasse het keyword override te gebruiken om expliciet aan te geven dat er een methode of property komt wiens werking die van de parent-klasse zal wijzigen.
Enkel indien een element met virtual werd aangeduid, kan je deze dus met override aanpassen. Uiteraard ben je niet verplicht om elke virtueel element ook effectief te overriden. virtual geeft enkel aan dat dit een mogelijkheid is, geen verplichting.
Stel je voor dat je een applicatie hebt met 2 klassen, Vliegtuig en Raket. Een raket is een vliegtuig, maar kan veel hoger vliegen dan een vliegtuig. Omdat we weten dat potentiële childklassen op een andere manier zullen willen vliegen, zullen we de methode Vliegvirtual zetten:
internal class Vliegtuig
{
public virtual void Vlieg()
{
Console.WriteLine("Het vliegtuig vliegt door de wolken.");
}
}
internal class Raket: Vliegtuig
{
}
Merk op dat we het keyword virtual mee opnemen in de methodesignatuur op lijn 3, en dat deze dus niets te maken heeft met het returntype en de zichtbaarheid van de methode. Dit zou bijvoorbeeld een perfect legale methodesignatuur kunnen zijn: protected virtual int SayWhatNow().
Terzijde: static methoden kunnen niet virtual gezet worden.
Stel dat we 2 objecten aanmaken en laten vliegen:
Vliegtuig topGun = new Vliegtuig();
Raket spaceX1 = new Raket();
topGun.Vlieg();
spaceX1.Vlieg();
De uitvoer zal dan zijn twee maal dezelfde zin tonen: Het vliegtuig vliegt door de wolken.
Enkel public methoden en properties kan je virtual instellen.
Momenteel doet het virtual keyword niets. Het is enkel een signaal aan mede-programmeurs: "hey, als je wilt mag je de werking van deze methode aanpassen als je van deze klasse overerft."
Een raket is een vliegtuig, toch vliegt het anders. We willen dus de methode Vlieg anders uitvoeren voor een raket. Daar hebben we override voor nodig. Door override voor een methode in de child-klasse te plaatsen zeggen we "gebruik deze implementatie en niet die van de parent klasse."
internal class Raket:Vliegtuig
{
public override void Vlieg()
{
Console.WriteLine("De raket verdwijnt in de ruimte.");
}
}
De uitvoer van volgende code zal nu anders zijn:
Vliegtuig topGun = new Vliegtuig();
Raket spaceX1 = new Raket();
topGun.Vlieg();
spaceX1.Vlieg();
Uitvoer:
Het vliegtuig vliegt door de wolken.
De raket verdwijnt in de ruimte.
Indien je iets override moet de signatuur van je methode of property identiek zijn aan deze van de parent-klasse. Het enige verschil is dat je het keyword virtual vervangt door override.
Als je in VS override begint te typen in een child-klassen dan kan je met behulp van de tab-toets heel snel de overige code van de signatuur schrijven.
Het base keyword laat ons toe om bij override van een methode of property in de child-klasse toch te verplichten om de parent-implementatie toe te passen. Dit kan handig zijn wanneer je in je child-klasse de bestaande implementatie wenst uit te breiden.
Stel dat we volgende 2 klassen hebben:
internal class Restaurant
{
protected int kosten = 0;
public virtual void PoetsAlles()
{
kosten += 1000;
}
}
internal class Frituur:Restaurant
{
public override void PoetsAlles()
{
kosten += (1000 + 500); //SLECHT IDEE! Wat als de basiskosten in het restaurant veranderen?
}
}
Het poetsen van een Frituur is duurder (1000 basis + 500 voor ontsmetting) dan een gewoon Restaurant. Als we echter later beslissen dat de basisprijs (in Restaurant) moet veranderen dan moet je ook in alle child-klassen doen, wat natuurlijk geen goede programmeerstijl is.
base lost dit voor ons op. De Frituur-klasse herschrijven we naar:
internal class Frituur:Restaurant
{
public override void PoetsAlles()
{
base.PoetsAlles(); //eerste basiskost wordt opgeteld
kosten += 500; //kosten eigen aan frituur worden bijgeteld
}
}
Het base keyword laat ons toe om in onze code expliciet een methode of property van de parent-klasse aan te roepen. Ook al overschrijven we de implementatie van PoetsAlles toch kan de originele versie van de parent-klasse nog steeds gebruikt worden.
We hebben een soortgelijke werking ook reeds gezien bij de constructors van overgeërfde klassen.
Je kan zelf beslissen waar in je code je base aanroept. Soms doe je dat aan de start van de methode, soms op het einde, soms halverwege. Alles hangt er van af wat je juist nodig hebt.
"Ik denk dat ik een extra voorbeeldje nodig ga hebben."
Laten we eens kijken. Beeld je in dat je volgende basisklasse hebt:
internal class Oermens
{
public virtual int VoorzieVoedsel()
{
return 15; //kg
}
}
Wanneer 1 van mijn dorpsgenoten voedsel zoekt door te jagen zal hij 15 kg vlees verzamelen.
De moderne mens, die overerft van de oermens, is natuurlijk al iets beter in het maken van voedsel en kan dagelijks standaard 100 kg voedsel maken.
Echter, er bestaan ook jagers die nog op de klassieke manier voedsel kunnen verzamelen (maar ze zijn wel gewoon moderne mensen, dus geen klasse apart hier). Uiteraard hebben zij de technieken van de oermens verbeterd en zullen sowieso toch iets meer voedsel nog kunnen verzamelen met de traditionele methoden, namelijk 20 kg bovenop de basishoeveelheid van 15 kg.
internal class ModerneMens: Oermens
{
public bool IsJager {get; set;}
public override int VoorzieVoedsel()
{
if (IsJager)
return base.VoorzieVoedsel() + 20;
return 100;
}
}
Dankzij overerving zijn we nu in staat om Pong uit te breiden met andere soort balletjes. De eerste vraag die je je moet stellen is dan "welke werking in de klasse Balletje gaan we potentiëel willen aanpassen?". Laten we veronderstellen dat we enkel de Update mogelijk willen veranderen. We voegen daarom het virtual keyword aan die methode toe:
virtual public void Update()
Voor de rest passen we hier niets aan. Dankzij overerving kunnen we de klasse Balletje nu onaangeroerd laten en onze nieuwe functionaliteit toevoegen via child-klassen.
Stel dat we een nieuw Balletje willen ontwikkelen, genaamd CentreerBalletje. Dit balletje heeft als eigenschappen dat het terug naar het midden van het scherm teleporteert wanneer het de linker- of rechterzijde van het scherm raakt. Dit zal er zo uitzien:
internal class CentreerBalletje : Balletje
{
public override void Update()
{
if(X+VX >= Console.WindowWidth || X+VX < 0)
{
X = Console.WindowWidth / 2;
Y = Console.WindowHeight / 2;
}
base.Update();
}
}
We hoeven nu enkel in het hoofdprogramma alle Balletje-variabelen te vervangen door CentreerBalletje.
Dankzij polymorfisme verderop gaan we ontdekken dat zelfs dit eigenlijk mag!
C# houdt van objecten. De hele taal is letterlijk opgebouwd om maximaal het object georiënteerd programmeren te omarmen. Van zodra je een nieuw project aanmaakt kan je niet naast de internal class Program zien. Hoe meer je C# en de bestaande bibliotheken bekijkt, hoe duidelijker dit wordt. Alles is een klasse.
Maar dan stelt zich natuurlijk de vraag: staat er nog iets boven alle klassen die wij aan het maken zijn? Is er misschien een soort oer-klasse waar alle klassen van overerven?
De vraag stellen is ze beantwoorden! Er is effectief een oer-klasse, genaamd de System.Object-klasse, waar alles en iedereen in C# van moet overerven.
Alle klassen in C# zijn afstammelingen van de System.Object klasse. Zowel de bestaande ingebouwde klassen zoals Random en Console. Maar ook klassen die je zelf maakt erven over van System.Object. En ja, zelfs de bestaande valuetype datatypes zoals int en bool zijn verre afstammelingen van System.Object.
Indien je een klasse schrijft zonder een expliciete parent dan zal deze steeds System.Object als rechtstreekse parent hebben. Ook afgeleide klassen stammen dus uiteindelijk af van System.Object. Concreet wil dit zeggen dat alle klassen System.Object-klassen zijn en dus ook de bijhorende functionaliteit ervan hebben.
Om de klasse Object niet te verwarren met het concept "object" zullen we hier steeds praten over System.Object.
Wanneer je een klasse Student aanmaakt als volgt: class Student{ }. Dan gebeurt er een zogenaamde impliciete overerving van System.Object. Er staat dus eigenlijk:
internal class Student: System.Object
{ }
Wat je trouwens ook expliciet zelf mag schrijven, dat maakt niet uit. Maar van zodra je een klasse schrijft die nergens expliciet van overerft, dan zal deze automatisch van System.Object overerven.1:
1
Je kan in de .NET documentatie altijd opzoeken waar een klasse van overerft. De Type klasse bijvoorbeeld erft finaal ook van System.Object over. Eerst erft Type over van de MemberInfo klasse, die op zijn beurt overerft van de oer-klasse.
Wanneer je een lege klasse maakt dan zal je misschien al gezien hebben dat instanties van deze nieuwe klasse reeds 4 methoden ingebouwd hebben, dit zijn uiteraard de methoden die in de System.Object klasse staan gedefiniëerd:
Methode
Beschrijving
Equals()
Gebruikt om te ontdekken of twee instanties gelijk zijn.
GetHashCode()
Geeft een unieke hash terug van het object; nuttig om o.a. te sorteren.
GetType()
Geeft het datatype (de klasse) van het object terug.
ToString()
Geeft een string terug die het object voorstelt.
Deze methoden zijn redelijk nutteloos in het begin. Enkel door ze zelf te overriden zullen ze hun nut bewijzen. Uiteraard kan je de de methoden testen om te zien wat er gebeurt.
Stel dat je een klasse Student hebt gemaakt in je project. Je kan dan op een object van deze klasse de GetType()-methode aanroepen om te weten wat het type van dit object is:
Student stud1 = new Student();
Console.WriteLine(stud1.GetType());
Dit zal als uitvoer de namespace gevolgd door het type van het object op het scherm geven . Als je project bijvoorbeeld StudentManager heet (en je namespace dus vermoedelijk ook) dan zal er op het scherm verschijnen: StudentManager.Student.
Wil je enkel het type zonder namespace dan is het nuttig te beseffen dat GetType() eigenlijk een object teruggeeft van het type Type met meerdere eigenschappen, waaronder Name. Volgende code zal enkel Student op het scherm tonen:
Student stud1 = new Student();
Console.WriteLine(stud1.GetType().Name);
Deze methode vind ik het nuttigst. Wanneer je schrijft:
Console.WriteLine(stud1);
Wordt er eigenlijk een impliciete aanroep naar ToString gedaan. Er staat dus eigenlijk:
Console.WriteLine(stud1.ToString());
Op het scherm verschijnt dan StudentManager.Student. Waarom? Wel, de methode ToString() wordt in System.Object() ongeveer als volgt beschreven:
public virtual string ToString()
{
return GetType();
}
Merk twee zaken op:
GetType() wordt aangeroepen en die output krijg je dus terug.
De methode is virtual gedefinieerd.
Alle 4 methoden in System.Object zijn virtual, en je kan deze dus override'n!
Nu komen we tot het hart van deze methoden. Aangezien ze alle 4 virtual zijn, kunnen we de werking ervan naar onze hand zetten in onze eigen klassen. Aardig wat .NET bibliotheken rekenen er namelijk op dat je deze methoden op de juiste manier hebt aangepast, zodat ook jouw nieuwe klassen perfect kunnen samenwerken met deze bibliotheken. Een eerste voorbeeld hiervan toonde ik net: de Console.WriteLine methode gebruikt van iedere parameter dat je er aan meegeeft de ToString-methode om de parameter op het scherm als string te tonen.
Het zou natuurlijk fijner zijn dat de ToString()-methode van onze student nuttigere info teruggeeft.
Stel dat we de Voornaam gevolgd door de Geboortejaar (ook een autoprop) willen terugkrijgen. We kunnen dat eenvoudig verkrijgen door ToString() te overriden:
internal class Student
{
public int Geboortejaar {get;set;}
public string Voornaam {get;set;}
public override string ToString()
{
return $"{Voornaam} ({Geboortejaar})";
}
}
Wanneer je nu Console.WriteLine(stud1); - gelet dat hij de properties Voornaam en Geboortejaar heeft - zou schrijven dan wordt je output: Tim Dams (1981).
Een extra handigheidje van ToString is dat deze methode wordt gebruikt tijdens het debuggen om je objecten samen te vatten in het watch-venster.
Ook deze methode kan je overriden om twee objecten met elkaar te vergelijken:
if(stud1.Equals(stud2))
De Equals()-methode heeft als signatuur: public virtual bool Equals(Object o)
Twee objecten zijn gelijk voor .NET als aan volgende afspraken wordt voldaan:
Het moet false teruggeven indien de parameter onull is.
Het moet true teruggeven indien je het object met zichzelf vergelijkt (bv. stud1.Equals(stud1)).
Het mag enkel true teruggeven als zowel stud1.Equals(stud2); als stud2.Equals(stud1); waar zijn.
Indien stud1.Equals(stud2) true teruggeeft en stud1.Equals(stud3) ook true is, dan moet stud2.Equals(stud3) ook true zijn.
Het is echter aan de maker van de klasse om te beslissen wanneer 2 objecten van een zelfde type gelijk zijn. Het is dus niet zo dat iedere waarde van een instantievariabele bijvoorbeeld gelijk moet zijn opdat 2 objecten gelijk zijn. Alles hangt af van de wijze waarop de klasse dienst moet doen.
Stel dat we vinden dat een student gelijk is aan een andere student indien z'n Voornaam en Geboortejaar dezelfde is, we kunnen dan de Equals-methode overriden als volgt in de Student klasse:
De lijn Student temp = (Student)o; zal het object o casten naar een Student. Doe je dit niet dan kan je niet aan de interne Student-variabelen van het object o. Dit concept noemen we polymorfisme (zie nog steeds hoofdstuk 16....We komen dichter!).
Indien je Equals override dan moet je eigenlijk ook GetHashCode overriden, daar er wordt verondersteld dat twee gelijke objecten ook dezelfde unieke hashcode teruggeven. Wil je dit dus implementeren dan zal je dus een (bestaand) algoritme moeten schrijven dat een uniek nummer genereert voor ieder niet-gelijke object. Algoritmes bespreken om zelf een hash te genereren liggen niet in de scope van dit boek.
Als je nog wat dieper zou graven in de documentatie van System.Object zou je ontdekken dat er ook een static methode met als signatuur static bool ReferenceEquals(object obj1, object obj2) bestaat. Deze handige methode laat je toe om te controleren of 2 variabelen dezelfde referentie hebben. Je kan hiermee dus kijken of 2 variabelen naar hetzelfde object in de heap verwijzen. Het gebruik ervan is eenvoudig:
Nu stelt zich de vraag: waarom deze controle niet met de == doen? Alhoewel dit perfect toegestaan is, moet je je ervan bewust zijn dat de werking van == kan overschreven worden.Ik leg dit niet uit, maar kijk zeker eens in de appendix naar het hoofdstuk Operator overloading.
Je hebt dus geen garantie dat in alle projecten de == werkt zoals je zou verwachten. Prefereer daarom om ReferenceEquals() te gebruiken. Merk op dat we System. voor de methodenaam mogen weglaten, net zoals we Object in plaats van System.Object mogen schrijven.
"Ik ben nog niet helemaal mee..."
Niet getreurd, je bent niet de enige: het is allemaal een hoop nieuwe kennis om te verwerken. En ik vermoed dat je nu niet bepaald overweldigd bent van de nieuwe kennis. Mogelijk heb je nu zoiets van? "Ok..wow?! Wat krijg ik nu juist extra wetende dat al mijn klassen overerven van een oer-klasse? 4 methoden en wat beloofde compatibiliteit met andere .NET bibliotheken? Call me ...unimpressed".Begrijpelijke reactie.
Hou vol, we zijn een hoop puzzelstukjes aan het opnemen die finaal zullen samenkomen om een gigantisch knappe OOPuzzel te maken (see what I did there?) In die puzzel zal polymorfisme onze sterspeler worden. Het zal ons toelaten erg krachtige code te schrijven.
Polymorfisme wordt onze doelpuntenmaker, maar System.Object zal steeds de perfecte voorzet geven!
Aan de start van hoofdstuk 9 gaf ik volgende twee definities:
Een klasse is als een blauwdruk dat het gedrag en toestand beschrijft van alle objecten van deze klasse.
Een individueel object is een instantie van een klasse en heeft een eigen toestand, gedrag en identiteit.
Niemand die zich hier vragen bij stelde? Als ik in het echte leven zeg: "Geef mij eens de blauwdruk van een object van het type meubel." Wat voor soort meubel zie je voor je bij het lezen van deze zin? Een tafel? Een kast? Een zetel? Een bed?
En wat zie je voor je als ik vraag om een "geometrische figuur" in te beelden. Een cirkel? Een rechthoek? Een kubus? Een buckyball? Kortom, er zijn in het leven ook soms eerder abstracte dingen die niet op zich in objecten kunnen gegoten worden zonder meer informatie.
Toch is het concept "geometrische figuur" een belangrijk concept: we weten dat alle geometrische figuren een gemeenschappelijke definitie hebben, namelijk - met dank aan Encyclo.nl- dat het twee- of meerdimensionale grafische elementen zijn waarvan de vorm wiskundig te berekenen valt. En dus is er ook een bestaansreden voor een klasse GeometrischeFiguur.Objecten van deze abstracte klasse maken daarentegen lijkt ons nutteloos.
Het is dit concept, abstracte klasse datik in dit hoofdstuk uit te doeken doe. Het laat ons toe klassen te definiëren die niet niet kunnen geïnstantieerd worden, maar die wel dienst kunnen doen als parentklasse voor andere klassen.
Laten we voorgaande eens praktisch binnen C# bekijken. Soms maken we een parent-klasse waarvan geen instanties kunnen gemaakt worden: denk aan de parent-klasse Dier. Voorbeelden van subklassen van Dier zijn Paard en Wolf. Van Paard en Wolf is het logisch dat je instanties kan maken (echte paardjes en wolfjes) maar van 'een dier'? Hoe zou dat er uit zien? Maar toch willen we bepaalde delen gemeenschappelijk maken (alle dieren hebben bijvoorbeeld zuurstof nodig).
Met behulp van het keyword abstract kunnen we aangeven dat een klasse abstract is: je kan overerven van deze klasse, maar je kan er geen instanties van aanmaken.
We plaatsen abstract voor de klasse definitie om dit aan te duiden.
Een voorbeeld:
internal abstract class Dier
{
public string Naam {get;set;}
}
We kunnen nu geen objecten meer van het type Dier aanmaken. Volgende code zal een foutboodschap geven: Dier hetDier = new Dier();
Maar, we mogen dus wel klassen overerven van deze klasse en instanties van deze nieuwe klasse aanmaken:
internal class Paard: Dier
{
//...
}
internal class Wolf: Dier
{
//...
}
En dan zal dit wel werken: Wolf wolfje = new Wolf();
En als we polymorfisme gebruiken (soon!) dan mag dit ook: Dier paardje = new Paard();
In het begin lijkt abstract een beperkende factor: je kan minder dan ervoor. Maar het heeft dus één heel duidelijke functie: je kan een parent-klasse maken waarin de gedeelde functionaliteit van je child-klassen in zit, zonder dat je deze parent-klasse op zich kunt gebruiken.
Het is logisch dat we mogelijk ook bepaalde zaken in de abstracte klasse als abstract kunnen aanduiden. Beeld je in dat je een methode MaakGeluid hebt in je klasse Dier. Wat voor een geluid maakt 'een dier'? We kunnen dus ook geen implementatie (code) geven in de abstracte parent klasse, maar willen wel zeker ervoor zorgen dat alle child-klassen van Dier geluid kunnen maken, op wat voor manier dan ook.
Via abstracte methoden geven we dit aan: we hoeven enkel de methode signatuur te geven, met ervoor abstract:
internal abstract class Dier
{
public abstract string MaakGeluid();
}
Door het keyword abstractzijn child-klassen verplicht deze abstracte methoden te overriden!
Merk op dat er geen codeblock-accolades na de signatuur van abstracte methodes komt.
internal class Paard: Dier
{
public bool HeeftTetanus {get;set;}
public override string MaakGeluid()
{
return "Hinnikhinnik";
}
}
1
En idem voor de Wolf-klasse uiteraard, maar hopelijk met een dreigender geluid.
Dit is dus niet hetzelfde als virtual waar een override MAG. Bij abstract MOET je override'n. We komen dan ook bij de essentie van het abstracte klasse concept: ze laten ons toe om klassen te maken waar nog gaten in zitten qua implementatie. We maken als het ware een soort klasse-sjabloon, die de child-klassen nog verder moeten inkleuren.
Properties kunnen virtual gemaakt worden, en dus ook abstract. Net zoals bij abstracte methoden, kunnen we met abstracte properties de overgeërfde klassen verplichten een eigen implementatie van de property te schrijven.
Volgend voorbeeld toont hoe dit werkt:
internal abstract class Dier
{
abstract public int MaxLeeftijd { get;}
}
internal class Olifant : Dier
{
public override int MaxLeeftijd
{
get
{
return 100;
}
}
}
Wanneer je een abstracte property maakt dien je ogenblikkelijk aan te geven of het om een readonly, writeonly, of property met get én set gaat:
Dankzij abstract kunnen we nu een meer algemene klasse maken in Pong. Beeld je in dat je naast balletjes ook andere zaken op het scherm wilt tonen. Echter, niet alles moet als een gek over het scherm vliegen én is op de koop toe niet noodzakelijk een child van de Balletje-klasse.
We definiëren daarom een klasse die alle zaken zal voorstellen die "op het scherm" moeten getoond worden. Omdat we niet weten HOE die zaken getoond worden, zal dit een abstracte klasse worden waarbij we de TekenOpScherm-methode bewust niet implementeren:
internal abstract class SpelObject
{
public int X { get; set; }
public int Y { get; set; }
public abstract void TekenOpScherm();
}
We kunnen nu ons klasse Balletje hier van laten overerven en veranderen volgende zaken:
We halen de X en Y properties uit de klasse (daar de parent deze al heeft gedefiniëerd).
We veranderen TekenOpScherm van een virtual naar een override versie, daar we nu de abstracte methode van de parent moeten implementeren. Merk op dat dit geen invloed heeft op de child-klassen van Balletje, die zullen nog steeds in staat zijn om de Update-versie van Balletje te override'n.
internal class Balletje:SpelObject
{
//...
public override void TekenOpScherm()
{
//...
Dankzij deze abstracte klasse hebben we nu een manier om bijvoorbeeld ook een scorebord in het spel te brengen:
internal class ScoreBoard: SpelObject
{
public ScoreBoard()
{
X = 5;
Y = 5;
}
public int ScoreSpeler1 { get; set; }
public int ScoreSpeler2 { get; set; }
public override void TekenOpScherm()
{
Console.BackgroundColor = ConsoleColor.Yellow;
Console.ForegroundColor = ConsoleColor.Black;
Console.SetCursorPosition(X, Y);
Console.Write($"{ScoreSpeler1} - {ScoreSpeler2}");
Console.ResetColor();
}
}
In ons hoofdprogramma blijven we leven van de kracht van polymorfisme en gebruiken we een snuifje is en as om zeker onze Balletje ook te update'n wanneer nodig. Onze lijst, hernoemd naar spelElementen zal nu SpelObject objecten bevatten:
List<SpelObject> spelElementen = new List<SpelObject>();
//Balletjes toevoegen...
//En nu het scoreboard
var score = new ScoreBoard()
spelElementen.Add();
while (true)
{
foreach(var spelObject in spelElementen)
{
//update enkel de balletjes
if(spelObject is Balletje)
{
(spelObject as Balletje).Update();
}
//spe
}
Indien nu een speler scoort dan kunnen we schrijven:
We zijn ondertussen al gewend aan het opvangen van uitzonderingen met behulp van try en catch. Ook bij exception handling wordt overerving toegepast. De uitzonderingen die we opvangen zijn steeds objecten van het type Exception of van een afgeleide klasse. Denk maar aan de NullReferenceException klasse die werd overgeërfd van Exception.
Dat wil zeggen dat Exceptions ook maar "gewone klassen" zijn en dus ook aan alle andere regels binnen C# moeten voldoen. Zo ondersteunen ze polymorfisme (sooooon!), kan je ze in arrays plaatsen, enz.
Bijgevolg is het logisch dat je in je code uitzonderingen zelf kunt maken en opwerpen. Vervolgens kan je deze elders opvangen.
Een voorbeeld van een bestaand Exception type gebruiken. We gaan zelf een Exception object aanmaken (met new) en dit vervolgens opwerpen wanneer we een uitzondering opmerken. In dit geval wanneer getal de waarde 0 heeft:
Je kan ook eigen klassen overerven van Exception zodat je eigen uitzonderingen kan maken. Je maakt hiervoor gewoon een nieuwe klasse aan die je laat overerven van de Exception-klasse. Een voorbeeld:
internal class Timception: Exception
{
public override string ToString()
{
string extrainfo = "Exception Generated by Tim Dams:\n";
return $"{extrainfo}. {base.ToString()}";
}
}
Merk op dat we hier met base.ToString() ervoor zorgen dat ook de foutboodschap van het parent-gedeelte van de uitzondering wordt weergegeven.
Om deze exception nu zelf op te werpen gebruiken we het keyword throw gevolgd door een object van het type uitzondering dat je wenst op te werpen.
In volgende voorbeeld gooien we onze eigen exception op een bepaald punt in de code op en vangen deze dan op:
Dit hoofdstuk is kort maar krachtig. Ik ga eigenlijk niets nieuws uitleggen. Ik ga zaken benoemen die je waarschijnlijk al toepaste, zonder te weten dat er daar ook een naam voor was.
We spreken over compositie (compositie) en aggregatie (aggregation) wanneer we een object in een ander object gebruiken. Beide termen zijn zogenaamde associaties.
Ze beschrijven de relatie tussen 2 objecten. Denk bijvoorbeeld aan een object van het type Motor dat je gebruikt in een object van het type Auto. Afhankelijk of het interne object kan bestaan zonder het omliggende object bepaalt of het gaat om aggregatie of compositie:
Compositie: Het interne object heeft geen bestaansreden zonder het omliggende object. Denk bijvoorbeeld aan een kamer in een huis. Als het huis verdwijnt, verdwijnt ook de kamer.
Aggregatie: Beide objecten kunnen onafhankelijk van elkaar bestaan. Denk hierbij aan de motor in een auto. Wanneer de auto vernietigd wordt kan de motor gered worden en elders gebruikt worden. Een ander voorbeeld zijn de harde schijven in een computer.
Het lijdende voorwerp zal steeds het object zijn dat binnen het onderwerp zal geplaatst worden (motor in auto, schijf in computer).
Overerving konden we detecteren door de "is een"-relatie. Een associatie daarentegen detecteren we met behulp van de "heeft een"-relatie tussen 2 klassen. Een mango heeft een pit. Een vliegtuig heeft een cockpit. enz.
Je hoort ook ogenblikkelijk of het om een "heeft één" of "heeft meerdere"-relatie gaat. In het tweede geval (heeft meerdere) wil dit zeggen dat het omliggende object een array van het interne object in zich heeft. Wederom het voorbeeld van het boek: een boek heeft meerdere pagina's. Dus in de klasse Boek zullen we een object van het type Pagina[] of List<Pagina> tegenkomen.
Een klassieke fout is overerving gebruiken wanneer je bijvoorbeeld de relatie tussen een boek en z'n pagina's wilt aanduiden. Een boek is géén pagina, ook niet omgekeerd. Er is dus geen sprake van overerving. Een boek HEEFT een pagina (of meerdere). Er is dus sprake van een associatie, namelijk aggregatie (je kan pagina's uit een boek scheuren en deze nog steeds doorgeven aan iemand anders).
Compositie duiden we aan met een lijn die begint met een volle ruit aan de kant van de klasse die de objecten in zich heeft:
Aggregatie duiden we op exact dezelfde manier aan, maar de ruiten zijn niet gevuld. Optioneel duidt een getal aan iedere kant van de lijn de verhouding aan (zowel bij aggregatie als compositie), zodat we kunnen aangeven hoeveel (of geen) objecten het omliggende object kan hebben:
Uiteraard zijn ook combinaties mogelijk. Stel je voor dat je een applicatie moet ontwerpen waarin je een reeks huizen moet bouwen, waarbij er in de slaapkamer steeds een computer moet gezet worden:
Herinner je: overerving duiden we aan met een pijl die wijst naar de parent-klasse en duidt een "is een"-relatie aan.
Het verschil tussen aggregatie en compositie is vooral van filosofische aard. In de praktijk zijn er weinig verschillen.
Eens kijken naar het voorbeeld van de computer en de harde schijf. We hebben twee klassen:
internal class PC
{
}
internal class HardeSchijf
{
}
Een PC heeft een HardeSchijf, dit wil zeggen dat we in de klasse PC een object (instantievariabele) van het type HardeSchijf zullen definiëren:
internal class PC
{
private HardeSchijf cHardeSchijf;
}
In principe kunnen we nu zeggen dat we aggregatie hebben toegepast. Uiteraard moeten we nu deze HardeSchijf nog instantiëren anders zal deze de hele levensduur van ieder PC-object null zijn.
De instantie van een geaggregeerd object kan op verschillende manieren aangemaakt worden en is afhankelijk van wat je nodig hebt in je applicatie.
Associatie is net zoals overerving een belangrijk onderdeel van het OOP paradigma. Er is geen exacte oplossingsstrategie om associatie toe te passen: deze zal afhankelijk zijn van je specifieke probleem en oplossing. Staar je dus niet blind op deze voorbeelden: het is maar een greep uit de vele manieren waarmee je associateis kunt gebruiken.
Wanneer we wensen dat iedere nieuwe PC ogenblikkelijk een interne harde schijf heeft dan kunnen we dit doen door ogenblikkelijk de instantievariabele een object te geven:
internal class PC
{
private HardeSchijf cHardeSchijf = new HardeSchijf();
}
Willen we echter bij het aanmaken van een nieuwe pc ook iets meer controle over wat voor harde schijf er wordt geïnstalleerd, dan kan dit ook via de constructors. We zouden dan bijvoorbeeld afhankelijk van bepaalde parameters in de (overloaded) constructors de schijf andere eigenschappen kunnen geven:
internal class PC
{
private HardeSchijf cHardeSchijf;
public PC(bool preinstallHD)
{
//enkel interne harde schijf indien klant voorinstallatie wenst
if(preinstallHD)
cHardeSchijf = new HardeSchijf();
else
cHardeSchijf == null;
}
}
De lijn cHardeSchijf == null is niet noodzakelijk, daar cHardeSchijf sowieso null zal zijn indien we niet in de if gaan.
Ik raad je toch aan dit altijd expliciet te doen. Hiermee zeg je nadrukkelijk: "als we via de overloaded constructor een PC aanmaken en er is geen preinstallatie vereist dan zit er geen harde schijf in de pc". Het kan namelijk gebeuren dat voor we aan deze code komen er ondertussen iets voor heeft gezorgd dat cHardeSchijf alsnog een objectreferentie bevat. Door deze nu expliciet op null te zetten verwijderen we zeker de harde schijf als die er toch nog had ingezeten.
Heb je gezien hoe ik praat over deze preinstallatie alsof het om iets gaat dat in het echte leven gebeurt? Dit is bewust: het OOP paradigma draait om het feit dat het ons toelaat de realiteit zo dicht mogelijk te benaderen. Het helpt dan ook om je code (en probleemanalyse) steeds vanuit de context van de "echte wereld" te benaderen. Bijna ieder concept uit de echte wereld heeft een equivalent binnen C# als OOP-taal.
Het is een goede OOP oefening om af en toe in je omgeving eens rond te kijken, en wat je ziet vervolgens te vertalen naar een structuur van klassen, objecten en verbanden tussen die dingen (overerving, compositie, arrays en later ook nog polymorfisme en interfaces).
De vorige 2 voorbeelden waren eigenlijk voorbeelden van compositie. Wanneer de PC-objecten vernietigd worden (door de garbage collector) zullen ook de interne harde schijven verdwijnen.
Willen we echter via aggregatie de pc's bouwen, dan is het logischer dat we op een externe plaats de HardeSchijf objecten aanmaken. Nadat de PC werd aangemaakt zullen we de de schrijf in de PC plaatsen. We gebruiken hierbij properties om toegang tot de interne (geaggregeerde) variabele te verschaffen:
internal class PC
{
public HardeSchijf CHardeSchijf {get;set;}
}
Vervolgens kunnen we nu van buiten het object benaderen en er, als het ware, een nieuwe harde schijf in steken:
HardeSchijf mijnHardeSchijf = new HardeSchijf()
PC mijnPC = new PC();
mijnPC.CHardeSchijf = mijnHardeSchijf ;
Op deze manier hebben we nog steeds een referentie naar mijnHardeSchijf en zal de GC dit object dus niet verwijderen wanneer mijnPC wordt opgekuist.
Kortom, nog steeds niets nieuws onder de zon. Alle manieren die ja al kende om met bestaande types objecten aan te maken gelden nog steeds. Compositie deed je al de hele tijd wanneer je bijvoorbeeld zei "een student heeft een geboortejaar" en dan een instantievariabele int geboortejaar aanmaakte. Het grote verschil is echter dat objecten moeten geïnstantieerd worden, wat niet moest met value-types en je dus iets vaker op null zal moeten controleren.
Stel je voor dat de klasse HardeSchijf ook een auto-property MaxCapacity heeft. De klasse PC kan dankzij compositie dus nu ook die property gebruiken, zoals volgende voorbeeld toont:
internal class PC
{
private HardeSchijf cHardeSchijf = new HardeSchijf();
public override string ToString()
{
return $"PC capaciteit HD: {cHardeSchijf.MaxCapacity} Gb";
}
}
Het moge duidelijk zijn: compositie/aggregatie en referenties horen samen. Maar hoe ziet dit er allemaal uit in het geheugen? Blij dat je het vraagt!
Wanneer we van voorgaande klasse een object aanmaken als volgt:
PC mijnSuperPC = new PC();
Dan zien we volgende "beeld":
Compositie wil dus niet zeggen dat je in het geheugen grote monolithische objecten gaat hebben die het samengestelde object voorstellen. Neen, we blijven dankzij de kracht van referenties de boel apart houden.
Zoals je ziet is het belangrijk te beseffen dat bij compositie én aggregatie het inner object op zichzelf in de heap ergens zal gezet worden en dus niet in het parent-object komt. Alles dat we dus al wisten in verband met het doorgeven van referenties, de GC, enz. blijft dus nog steeds gelden.
Of zoals het hoofdstuk al begon: eigenlijk niets nieuws onder de zon!
Een veelvoorkomende fout bij compositie en aggregatie van objecten is dat je een intern object aanspreekt dat nooit werd aangemaakt. Je krijgt dan een NullReferenceException.
Het is dus zeker bij compositie en aggregatie een goede gewoonte om zoveel mogelijk te controleren op null telkens je het object gaat gebruiken:
public override string ToString()
{
string result= "Dit is een Intel i9.";
if(cHardeSchijf != null)
result += $"Capaciteit HD: {cHardeSchijf.MaxCapacity} Gb";
else
result += "Er is geen harde schijf aanwezig";
return result:
}
En uiteraard kan het ook nooit kwaad om alles in try-catch blokken te zetten, alleen is dat op detail-niveau niet werkbaar: je werkt met objecten en zal dus bijna de hele tijd code hebben waar NullReferenceException een potentieel gevaar is. Het is dus beter om vanaf de start je code zodanig te schrijven (met controles op null) dat er quasi geen uitzonderingen op null kunnen optreden.
Wanneer een object meerdere objecten van een specifiek type heeft (denk maar aan een boek met pagina's) dan zullen we een array of een List als associatie-object gebruiken. Een voorbeeld:
internal class Pagina
{
}
internal class Boek
{
public Pagina[] AllePaginas {get;set;} = new Pagina[100];
}
Indien je nu een pagina wenst toe te voegen dan moet je ook deze individuele array-elementen nog instantiëren.
internal class Boek
{
public Pagina[] AllePaginas {get;set;} = new Pagina[100];
public void InsertPagina(Pagina paginaIn, int positie)
{
AllePaginas[positie] = paginaIn;
}
}
Een voorbeeld waarbij men vervolgens van buiten het object bestaande pagina's kan toevoegen:
Boek zieScherper = new Boek();
Pagina mijnDerdePagina = new Pagina();
zieScherper.InsertPagina(mijnDerdePagina, 2);
Of een voorbeeld met List:
internal class Boek
{
//SLECHT IDEE!
public List<Pagina> AllePaginas {get;set;} = new List<Pagina>();
}
Dit heeft als voordeel dat we de Insert methode van de List-klasse kunnen gebruiken en niet zelf nog moeten schrijven:
zieScherper.AllePaginas.Insert(new Pagina(), 5);
Dit voorbeeld met List is vanuit OOP-standpunt geen goede oplossing. Het vereist namelijk dat programmeurs die jouw klasse Boek gebruiken, weten dat intern met een List wordt gewerkt.
We willen echter zo goed mogelijk een blackbox creëren, conform het abstractie-principe, die van buiten duidelijk en eenvoudig in gebruik is. Het is daarom beter om alsnog aan je Boek klasse een Insert methode toe te voegen. Dit geeft als extra verbetering dat we daarmee de set van onze lijst van pagina's private kunnen houden:
internal class Boek
{
public List<Pagina> AllePaginas {get; private set;} = new List<Pagina>();
public void InsertPagina(Pagina paginaIn, int positie)
{
allPaginas.Insert(paginaIn, positie)
}
}
Pagina's voegen we nu als volgt toe:
zieScherper.InsertPagina(new Pagina(), 5);
Begrijp je nu waarom het geen goed idee is om een interne lijst gewoonweg via een property naar buiten beschikbaar te maken? Stel je voor dat het essentiëel is dat de AllePaginas lijst NOOIT leeggemaakt wordt. Jij als ontwikkelaar weet dit. Maar andere gebruikers van je klasse misschien niet. Zij kunnen echter zonder problemen Clear() via de property aanroepen, wat dus onverwachte gevolgen kan hebben!
Ik vertelde in het begin van dit hoofdstuk dat compositie en aggregatie een "heeft een"-relatie aanduiden, terwijl overerving een "is een"-relatie behelst. In de praktijk zal je véél vaker compositie en aggregatie moeten gebruiken dan overerving.
Associatie laat ons toe om 2 (of meer) totaal verschillende soorten zaken met elkaar te laten samenwerken, iets wat met overerving enkel kan indien beide zaken een "is een"-relatie hebben. Dit zien we ook in de echte wereld: de zaken rondom ons zullen vaker een compositie/aggregatie-relatie hebben dan een overervings-relatie.
Zoals je hopelijk beseft kan dus alles een compositieobject zijn in een ander object. Denk maar aan een Dictionary van klanten die je gebruikt in een klasse Winkel. Of wat te denken van de klasse Mens die uit een hele boel organen bestaat. Ieder orgaan is compositie-object in de klasse Mens, zoals 2 Nier-objecten, een Hersenen instantie, 1 Hart instantie enz. Iemand die in jouw Mens-simulator een nieuw hart nodig heeft kan dat dan dankzij manier 3, via een property ingeplant krijgen:
Mens patient = new Mens();
Mens donor = new Mens();
//Donor heeft een tragisch ongeluk en sterft
//Operatie start
patient.Hart = null; //vorig hart wordt "verwijderd"
patient.Hart = donor.Hart;
donor = null //donor wordt begraven
Let er wel op dat je niet overal compositie begint toe te passen alsof je de Dokter Frankenstein van C# bent. Hoe meer compositie (of aggregatie) je toepast in een klasse, hoe specifieker die soms wordt, en daardoor mogelijk minder herbruikbaar. Het is om die reden dat we verderop interfaces gaan ontdekken om ervoor te zorgen dat 2 of meerdere klassen minder "op/in elkaar gelijmd" zitten ten gevolge van bijvoorbeeld een nogal hechte compositie.
Je zult in je zoektocht naar online antwoorden mogelijk al een paar keer het this keyword zijn tegengekomen. Dit keyword kan je aanroepen in een object om de referentie van het object terug te krijgen. Met andere woorden: het laat toe dat een object "zichzelf" kan aanroepen. Dat klinkt vreemd, maar heeft 3 duidelijke gebruiken:
Het laat toe dat een object zichzelf kan meegeven als actuele parameter aan een methode.
Het laat toe instantievariabelen en properties aan te roepen van het object die mogelijk dezelfde naam hebben als een lokale variabele.
We kunnen een andere constructor vanuit een constructor aanroepen zoals reeds gezien (in hoofdstuk 11).
Wanneer je this gebruikt binnen een klasse, dan zal je zien dat bij het schrijven van de dot-operator je ogenblikkelijk de volledige interne structuur van de klasse kunt bereiken:
Enerzijds ben je vrij om altijd this te gebruiken wanneer je eender wat van de klasse zelf wilt bereiken. Vooral in oudere code-voorbeelden zal je dat nog vaak zien gebeuren.
Anderzijds laat this ook toe om properties, methoden en instantievariabelen aan te roepen wanneer die mogelijk op de huidige plek niet aanroepbaar zijn omdat hun naam conflicteert met een lokale variabele dat dezelfde naam heeft:
De lijn Levens = 5; in de constructor zal de parameter zelf van waarde aanpassen (wat niet wordt aangeraden). Terwijl door this te gebruiken geraak je aan de property met dezelfde naam.
Merk op dat qua naamgeving de keuze van de formele parameter Levens in de constructor sowieso een ongelukkige keuze is in dit voorbeeld.
Beeld je in dat je volgende Management klasse hebt die toelaat om Werknemer objecten te controleren of ze promoveerbaar zijn of niet. Het management van de firma heeft beslist dat werknemers enkel kunnen promoveren als hun huidige Rang lager is dan 10:
internal class Management
{
private const int MAXRANG = 10;
public static bool MagPromoveren(Werknemer toCheck)
{
return toCheck.Rang < MAXRANG;
}
}
Dankzij het this keyword kan je nu vanuit de klasse Werknemer deze externe methode aanroepen om zo te kijken of een object al dan niet kan promoveren:
internal class Werknemer
{
public int Rang { get; set; }
public bool IsPromoveerbaar()
{
return Management.MagPromoveren(this);
}
}
Op deze manier geeft het object waarop je IsPromoveerbaar op aanroept zichzelf mee als actuele parameter aan Management.MagPromoveren(). Dit laat dus toe dat een werknemer zelf kan weten of hij of zij al dan niet kan promoveren:
Werknemer francis = new Werknemer();
if(francis.IsPromoveerbaar())
{
Console.WriteLine("Jeuj!");
}
En zo komen we eindelijk aan de vierde grote pijler van OOP. Weet je nog waar A,I en E voor stonden in A PIE? Nu gaan we dus de P van Polymorfisme (polymorphism) aanpakken.
De latijnse naam polymorfisme bestaat uit 2 delen: poly en morfisme, letterlijk dus "meerdere vormen". En geloof het of niet, deze naam dekt de lading ongelooflijk goed.
Polymorfisme laat ons toe dat objecten kunnen behandeld worden als objecten van de klasse waar ze van overerven. Dit klinkt logisch, maar zoals je zo meteen zal zien zal je hierdoor erg krachtige code kunnen schrijven. Anderzijds zorgt polymorfisme er ook voor dat het virtual en override concept bij methoden en properties ook effectief werkt. Het is echter vooral de eerste eigenschap waar ik in dit hoofdstuk dieper op in ga.
Dankzij overerving kunnen we "is een"-relaties beschrijven. Soms is het echter handig dat we alle child-objecten als dat van hun parent kunnen beschouwen. Beeld je in dat je een gigantische klasse-hiërarchie hebt gemaakt, maar finaal wil je wel dat alle objecten een bepaalde property aanpassen die ze gemeenschappelijk hebben. Zonder polymorfisme is dat een probleem.
Stel dat we een een aantal van Dier afgeleide klassen hebben die allemaal op hun eigen manier een geluid voortbrengen:
internal abstract class Dier
{
public abstract string MaakGeluid();
}
internal class Paard: Dier
{
public override string MaakGeluid()
{
return "Hinnikhinnik";
}
}
internal class Varken: Dier
{
public override string MaakGeluid()
{
return "Oinkoink";
}
}
Met de hulp van polymorfisme kunnen we nu elders objecten van Paard en Varken in een variabele van het type Dier bewaren, maar toch hun eigen geluid laten reproduceren:
Dier someAnimal = new Varken();
Dier anotherAnimal = new Paard();
Console.WriteLine(someAnimal.MaakGeluid()); //Oinkoink
Console.WriteLine(anotherAnimal.MaakGeluid()); //Hinnikhinnik
Alhoewel er een volledig Varken en Paard object in de heap wordt aangemaakt (en blijft bestaan), zullen variabelen van het type Dier enkel die dingen kunnen aanroepen die in de klasse Dier gekend zijn. Dankzij override zorgen we er echter voor dat MaakGeluid wel die code uitvoert die specifiek bij het child-type hoort.
Het is belangrijk te beseffen dat someAnimal en anotherAnimal van het type Dier zijn en dus enkel die dingen kunnen die in Dier beschreven staan. Enkel zaken die override zijn in de child-klasse zullen met de specialisatie-code werken.
Kortom, polymorfisme laat ons toe om referenties (naar objecten van een child-type) toe te wijzen aan een variabele van het parent-type (upcasting).
Dit wil ook zeggen dat dit mag (daar alles overerft van System.Object):
System.Object mijnObject = new Varken();
Alhoewel mijnObject effectief een Varken is (in het geheugen), kunnen we enkel aan dat gedeelte dat in de klasse System.Object staat beschreven (ToString, Equals enz.). Als we het varken toch geluid willen laten maken, dan zal dat niet werken!
Arrays en lijsten laten heel krachtige code toe dankzij polymorfisme. Je kan een lijst van de basis-klasse maken en deze vullen met allerlei objecten van de basis-klasse én de child-klassen.
Een voorbeeld:
List<Dier> zoo = new List<Dier>();
zoo.Add(new Varken());
zoo.Add(new Paard());
foreach(var dier in zoo)
{
Console.WriteLine(dier.MaakGeluid());
}
We hebben nu een manier gevonden om onze objecten op de juiste momenten even als één geheel te gebruiken, zonder dat we verplicht zijn dat ze allemaal van hetzelfde type zijn!
Polymorfisme is een heel krachtig concept. Door een referentie naar een object te bewaren in een variabele van z'n basistype en, wanneer nodig, ze als 'zichzelf' te gebruiken wordt je code een pak eenvoudiger.
Vaak weet je niet op voorhand wat voor elementen je in je lijst wilt plaatsen. Via polymorfisme lossen we dit op. Stel dat je een List<Person> hebt waar echter elementen van subklassen (Bakker, Student, enz.) in terecht kunnen komen. Polymorfisme laat gewoon toe om ook deze elementen in die lijst te plaatsen.
Ik had al een klein tipje van de sluier gelicht toen ik overerving introduceerde in Pong. Met de hulp van overerving konden we plots veel toffere balletjes ontwikkelen zoals het CentreerBalletje. Wel, met de hulp van polymorfisme kan dit op de koop toe zonder dat we ons hoofdprogramma moeten aanpassen. In principe kunnen we nog steeds werken met List<Balletje>, maar maakt het niet uit wat voor balletjes we er in plaatsen: polymorfisme zal de boel draaiende houden.
Beeld je in dat we naast CentreerBalletje ook nog de klassen InstabielBalletje (dat op random momenten z'n vectoren op 0 zet) en TeleportBalletje (dat elke 10 ticks naar een random plek op het scherm teleporteert) hebben. De code om deze balletjes te instantiëren en in de lijst te plaatsen wordt verrassend eenvoudig:
We hebben nu 5 balletjes: 2 gewone, en eentje van de 3 nieuwe types elk. Alle overige code verderop, waarin we de lijst doorlopen en de Update en TekenOpScherm aanroepen van ieder balletje, moet niet aangepast worden.
Beeld je in dat je een klasse EersteMinister hebt met een methode Regeer en je wilt een eenvoudig land simuleren.
De EersteMinister heeft toegang tot de ministers die hem kunnen helpen (inzake milieu, binnenlandse zaken (BZ) en economie). Zonder de voordelen van polymorfisme zou de klasse EersteMinister er zo kunnen uitzien (slechte manier!):
internal class EersteMinister
{
public MinisterVanMilieu Jansens {get;set;} = new MinisterVanMilieu();
public MinisterBZ Ganzeweel {get;set;} = new MinisterBZ();
public MinisterVanEconomie VanCent {get;set;} = new MinisterVanEconomie();
public void Regeer()
{
// ministers stappen binnen en zeggen wat er moet gebeuren
// Jansens: Problematiek aangaande bos dat gekapt wordt
Jansens.VerhoogBosSubsidies();
Jansens.OpenOnderzoek();
Jansens.ContacteerGreenpeace();
// Ganzeweel advies omtrent rel aan grens met Nederland
Ganzeweel.VervangAmbassadeur();
Ganzeweel.RoepTroepenmachtTerug();
Ganzeweel.VerhoogRisicoZoneAanGrens();
// Van Cent geeft advies omtrent nakende beurscrash
VanCent.InjecteerGeldInMarkt();
VanCent.VerlaagWerkloosheidsPremie();
}
}
Dit voorbeeld is gebaseerd op een briljante StackOverflow post waarin de vraag "What is polymorphism, what is it for, and how is it used?" wordt behandeld1.
De MinisterVanMilieu zou er zo kunnen uitzien (de methodenimplementatie mag je zelf verzinnen):
internal class MinisterVanMilieu
{
public void VerhoogBosSubsidies(){}
public void OpenOnderzoek(){}
}
De MinisterVanEconomie-klasse heeft dan weer heel andere publieke methoden. En de MinisterBZ ook weer totaal andere.
Je merkt dat de EersteMinister-klasse aardig wat specifieke kennis moet hebben van de vele verschillende departementen van het land. Bovenstaande code is dus zeer slecht en vloekt tegen het abstractie-principe van OOP: onze klasse moeten veel te veel weten van andere klassen, wat vermeden moet worden. Telkens er zaken binnen een specifieke ministerklasse wijzigen moet dit ook in de EersteMinister aangepast worden. Dankzij polymorfisme en overerving kunnen we dit alles veel mooier oplossen!
Ten eerste: We verplichten alle ministers dat ze overerven van de abstracte klasse Minister die maar 1 abstracte methode heeft Adviseer:
internal abstract class Minister
{
abstract public void Adviseer();
}
internal class MinisterVanMilieu:Minister
{
public override void Adviseer()
{
VerhoogBosSubsidies();
OpenOnderzoek();
ContacteerGreenpeace();
}
private void VerhoogBosSubsidies(){ ... }
private void OpenOnderzoek(){ ... }
private void ContacteerGreenpeace(){ ... }
}
}
internal class MinisterBZ:Minister {}
internal class MinisterVanEconomie:Minister {}
Ten tweede: Het leven van de EersteMinister wordt plots véél makkelijker. Hij kan gewoon de Adviseer methode aanroepen van iedere minister:
internal class EersteMinister
{
public MinisterVanMilieu Jansens {get;set;} = new MinisterVanMilieu();
public MinisterBZ Ganzeweel {get;set;} = new MinisterBZ();
public MinisterVanEconomie VanCent {get;set;} = new MinisterVanEconomie();
public void Regeer()
{
Jansens.Adviseer();
Ganzeweel.Adviseer();
VanCent.Adviseer();
}
}
En ten derde: En we kunnen hem nog helpen door met een array of List<Minister> te werken zodat hij ook niet steeds de "namen" van z'n ministers moet kennen. Dankzij polymorfisme mag dit:
internal class EersteMinister
{
public List<Minister> AlleMinisters {get;set;}= new List<Minister>();
public EersteMinister()
{
AlleMinisters.Add(new MinisterVanMilieu());
AlleMinisters.Add(new MinisterBZ());
AlleMinisters.Add(new MinisterVanEconomie());
}
public void Regeer()
{
foreach (Minister minister in AlleMinisters)
{
minister.Adviseer();
}
}
}
En wie zei dat het regeren moeilijk was?!
Merk op dat dit voorbeeld ook goed gebruik maakt van compositie.
Dankzij polymorfisme kunnen we dus child en parent-objecten door elkaar gebruiken. De keywords is en as gaan ons helpen om door het bos van objecten het bos nog te zien.
Het is keyword is een operator die je kan gebruiken om te weten te komen of:
Een object van een bepaalde datatype is.
Een object een bepaalde interface bevat (zie volgende hoofdstuk).
De is operator heeft twee operanden nodig en geeft een bool terug als resultaat. De linkse operator moet een variabele zijn, de rechtse een datatype. Bijvoorbeeld:
internal class Voertuig {}
internal class Auto: Voertuig{}
internal class Persoon {}
Een Auto is een Voertuig.
Een Persoon is géén Voertuig.
Stel dat we enkele variabelen hebben als volgt:
Auto mijnAuto = new Auto();
Persoon rambo = new Persoon();
We kunnen nu de objecten met is bevragen of ze van een bepaalde type zijn:
if(mijnAuto is Voertuig)
{
Console.WriteLine("mijnAuto is een Voertuig");
}
if(rambo is Voertuig)
{
Console.WriteLine("rambo is een Voertuig");
}
De uitvoer zal worden: mijnAuto is een Voertuig.
Met polymorfisme wordt dit voorbeeld echter interessanter. Wat als we een hoop objecten in een lijst van voertuigen plaatsen en nu enkel met de auto's iets willen doen, dan kan dat:
List<Voertuig> alleMiddelen = new List<Voertuig>();
alleMiddelen.Add(new Voertuig());
alleMiddelen.Add(new Auto());
alleMiddelen.Add(new Voertuig());
foreach (var middel in alleMiddelen)
{
if(middel is Auto)
{
//Doe iets met het huidige voertuig
}
}
Wanneer we objecten van het ene naar het andere type willen omzetten dan doen we dit vaak met behulp van casting:
Student fritz = new Student();
Mens jos = (Mens)fritz;
Het probleem bij casting is dat dit niet altijd lukt. Indien de conversie niet mogelijk is zal een uitzondering gegenereerd worden en je programma zal crashen als je niet aan exception handling doet.
Het as keyword lost dit op. Het keyword zegt aan de compiler "probeer dit object te converteren. Als het niet lukt, zet het dan op null in plaats van een uitzondering op te werpen."
De code van daarnet herschrijven we dan naar:
Student fritz = new Student();
Mens jos = fritz as Mens;
Indien nu de casting niet lukt (omdat Student misschien geen childklasse van Mens blijkt te zijn) dan zal jos de waarde null krijgen.
We kunnen dan vervolgens schrijven:
Student fritz = new Student();
Mens jos = fritz as Mens;
if(jos != null)
{
//Doe Mens-zaken
}
De is en as keywords worden gebruik in logische expressie. Ze hebben dan ook een bepaalde volgorde wanneer ze verwerkt zullen worden. Onze bestaande volgorde van bewerkingen krijgt dus 2 nieuwe leden op lijn 4:
Dankzij polymorfisme hebben we nu met de is en as keywords handige hulpmiddelen om meer "generieke" methoden te schrijven. Herinner je je nog de Equals methode die we schreven om 2 studenten te vergelijken toen we leerden dat alle klassen van System.Object overerfden? Laten we deze code er nog eens bijnemen en verbeteren:
De eerste lijn waarin we o casten naar een student kan natuurlijk mislukken. Het is dan ook veiliger om eerst te controleren of we wel mogen casten, voor we het effectief doen. Hierdoor schrijven we een minder foutgevoelige methode:
//In de Student klasse
public override bool Equals(Object o)
{
if(o is Student)
{
Student temp = o as Student;
return (Geboortejaar == temp.Geboortejaar && Voornaam == temp.Voornaam);
}
return false;
}
Of we kunnen ook het volgende doen:
//In de Student klasse
public override bool Equals(Object o)
{
Student temp = o as Student;
if(temp != null)
{
return (Geboortejaar == temp.Geboortejaar && Voornaam == temp.Voornaam);
}
return false;
}
Beide zijn geldige oplossingen.
De is en as keywords laten toe om meer dynamische code te schrijven. Mogelijk weet je niet op voorhand wat voor datatype je code zal moeten verwerken en wordt polymorfisme je oplossing. Maar dan? Dan komen is en as to the rescue!
Je met polymorfisme gevulde lijst van objecten van allerhande typen wordt nu beheersbaarder. Je kan nu met is een element bevragen of het van een bepaald type is. Vervolgens kan je met as het element tijdelijk 'omzetten' naar z'n effectieve type. Bijgevolg kan dit element dan doen dan wanneer hij kan in de vermomming is van z'n eigen basistype.
De naam interface kan je letterlijk vertalen als "tussen vlakken". Een interface is de verbinding tussen 2 systemen, van welke vorm ook. In de echte wereld gebruik je constant interfaces. Telkens je met de auto rijdt gebruik je een interface: namelijk een handvol handelingen om de auto te laten rijden (pedalen, stuur, enz.). Bijna alle auto's hanteren deze zelfde interface.
Van zodra je de interface kent en begrijpt kan je die overal gebruiken, zonder dat je moet weten wat er in het systeem intern juist gebeurt (als ik de gaspedaal induw boeit het niet of ik op gas of elektrisch rijd, zolang de auto maar voortbeweegt).
Aan de achterkant van je computer (en ook in de pc zelf) zijn tal van hardware-interfaces. Afgesproken manieren om 2 systemen met elkaar te laten communiceren. Zo heb je de USB-aansluiting die toelaat dat een extern systeem met een usb-aansluiting met de computer kan communiceren. Maar ook de HDMI, audio, en andere aansluitingen hanteren interfaces. Zouden er rond deze zaken geen wereldwijde interfaces zijn afgesproken, dan zou je mogelijk telkens op een andere manier je externe harde schijf aan een computer moeten hangen.
Voor je dolenthousiast wordt, denkende dat je eindelijk grafische applicaties (GUI oftewel Graphical User Interface applicaties) gaat maken, moet ik je helaas teleurstellen. Dit hoofdstuk behandelt het programmeer-concept interfaces wat eigenlijk niets te maken heeft met User Interfaces. U weze gewaarschuwd.
Interfaces in OOP
Dit concept van interfaces uit de echte wereld heeft ook een OOP variant. Namelijk de interface tussen 2 (of meer) klassen. Door te beloven dat een klasse aan een bepaalde interface voldoet kunnen alle klassen die deze interface "kennen" met elkaar praten. Een interface in OOP is een beschrijving van publieke methoden en properties die de klasse belooft te hebben. Net zoals je een fotocamera kunt kopen die de HDMI en USB-interface heeft, zo ook kan je nu een klasse maken die bijvoorbeeld de interfaces ISecure en IStreamableheeft.
Interfaces zijn als het ware stempels die we op een klasse kunnen plakken om zo te zeggen "deze klasse gebruikt interface xyz". Gebruikers van de klasse hoeven dan niet de hele klasse uit te spitten en weten dat alle klassen met interface xyz dezelfde publieke properties en methoden hebben.
Een interface is niet meer dan een belofte: het zegt enkel welke publieke methoden en properties de klassen bezit. Het zegt echter niets over de effectieve code/implementatie van deze methoden en properties.
Een interface is dus eigenlijk als het ware een klein stukje papier waar je op zet "om aan deze interface te voldoen moet je zeker volgende methoden en properties hebben". Kortom, een interface-bestand meestal een vrij klein bestand. Het is letterlijk de "Dit apparaat is USB 3.0 compatibel"-sticker.
Stel dat we deze interface kunnen we gebruiken in een spel vechtspel tussen karakters, waarin sommige van de klassen ook aan de Superhelden-interface moeten voldoen. Volgende code toont hoe we een interface definiëren in C#:
interface ISuperHeld
{
void SchietLasers();
int VerlaagKracht(bool isZwak);
int Power{get;set;}
}
Enkele opmerkingen hierbij zijn op z'n plaats:
Het woord class wordt niet gebruikt, in de plaats daarvan gebruiken we interface.
Het is een goede gewoonte om interfaces met een I te laten starten in hun naamgeving.
Methoden en properties gaan niet vooraf van public: interfaces zijn van nature al publiek, dus alle methoden en properties van de interface zijn dat bijgevolg ook (uiteraard geldt dit niet voor andere methoden in de klassen, deze mogen nog steeds private zijn als dat nodig is).
Er wordt geen code/implementatie gegeven: iedere methode eindigt ogenblikkelijk met een puntkomma.
Het is in de klassen waar we deze interface "aanhangen", dat we nu vervolgens verplicht zijn deze methode en properties te implementeren.
Ook abstracte klassen kunnen één of meerdere interfaces hebben. In het geval van een abstracte klasse is deze niet verplicht de interface ook al te implementeren, en mag (delen van) de interface ook als abstract aangeduid worden.
Een interface is een beschrijving hoe een component een andere component kan gebruiken, zonder te zeggen hoe dit moet gebeuren. De interface is met andere woorden 100% scheiding tussen de methode/property-signatuur en de eigenlijke implementatie ervan.
Interfaces zijn als het ware standaarden waaraan een klasse moet voldoen, wil het kunnen zeggen dat het een bepaalde interface heeft. Standaarden impliceert dat er duidelijke afspraken nodig zijn. Bij C# interfaces zijn er enkele belangrijke regels:
Je kan geen instantievariabelen declareren in een interface (dat hoort bij de implementatie).
Je kan geen constructors declareren.
Je kan geen access modifiers specificeren: alles is public1.
Je kan nieuwe types (bv. enum) in een interface declareren.
Een interface kan niet overerven van een klasse, wel van één of meerdere interfaces.
Een interface mag géén code bevatten.
1
In recentere versies van C# (sinds 8.0) is het nu wel toegestaan om public voor een methode of property te plaatsen. Dit verbeterd de leesbaarheid (daar we gewoon zijn dat het weglaten van een access modifier eigenlijk private betekent, wat bij interfaces dus niet zo is).
De laatste regel, "een interface mag géén code bevatten", is deels onwaar. Sinds C# 8.0 bestaan default interface methods. Dit zijn interface-methoden die standaardimplementaties bevatten. Deze implementaties worden gebruikt wanneer de methode niet is geïmplementeerd in de klasse die de interface overneemt. Ik behandel deze hier niet en raad je om interfaces te leren gebruiken waar ze voor bedoeld waren: property- en methodesignaturen zonder code.
We kunnen nu aan klassen de stempel ISuperHeld geven zodat programmeurs weten dat die klasse gegarandeerd de methoden SchietLasers, VerlaagKracht en de property Power zal hebben.
Volgende code toont dit. We plaatsen de interface (of interfaces) die de klasse beloofd te hebben achter het dubbele punt bovenaan.
internal class Zorro: ISuperHeld
{
public void RoepPaard(){...}
public bool HeeftSnor{get;set;}
public void SchietLasers() //interface ISuperHeld
{
Console.WriteLine("pewpew");
}
public int VerlaagKracht(bool isZwak)//interface ISuperHeld
{
if(isZwak)
{
return 5;
}
return 10;
}
public int Power {get;set;} //interface ISuperHeld
}
Zolang de klasse Zorro niet exact de interface inhoud implementeert zal deze klasse niet gecompileerd kunnen worden.
De klasse in dit voorbeeld blijft wel overerven van System.Object. Het is ook perfect mogelijk om een klasse te hebben die én overerft van een specifieke klasse én meerdere interfaces heeft:
internal class DarthVader: StarWarsCharacter, IForceUser, IPilot
Een "lolly" op een klasse geeft aan dat deze een bepaalde interface heeft in UML notatie. In volgende tekening hebben we een klasse WerkStudent en een interface IVerkortTraject.
We gebruiken de UML notatie voor een interface om aan te geven dat de Student klasse de IVerkortTraject interface heeft:
Een visuele manier om interfaces voor te stellen is de volgende. Eigenlijk is een interface als het ware een blad papier dat je bovenop je klasse kunt houden. Op het blad staan de methoden en properties beschreven die de interface moet hebben. Als je het blad mooi bovenop een klasse plaatst die de interface belooft te doen, dan zouden de gaten in het blad mooi bovenop de respectievelijke methoden en properties van de klasse passen.
Ik zei net: "Volgende interface kunnen we gebruiken in een spel waarin sommige klassen superhelden zijn." Die zin impliceert toch overerving "sommige klassen zijn superhelden"?
Dat klopt, maar zoals we weten kan je maar van 1 klasse overerven. Beeld je in dat je een uitgebreide klasse-hiërarchie hebt gemaakt bestaande uit monsters, mensen, huizen en voertuigen. Deze 4 groepen hebben mogelijk geen gemeenschappelijke parent, maar toch willen we dat sommige monsters superhelden kunnen worden, net zoals sommige mensen EN zelfs enkele voertuigen (Transformers!).
Dankzij interface kunnen we als het ware een stukje de beperking dat je maar van 1 klasse kunt overerven opvangen. Sommige klassen ZIJN een voertuig MAAR OOK een Superheld. Met andere woorden, klassen kunnen meerdere interfaces implementeren.
Merk wel op dat de interface NIET de implementatie bevat van wat een superheld juist doet. Het gaat enkel beloven dat de klasse bepaalde methoden en properties heeft.
Wanneer je in VS een klasse schrijft die een bepaalde interface moet hebben, dan kan je die snel implementeren. Je schrijft de klasse-signatuur en klikt er dan op: links verschijnt het lampje waar je vervolgens op kunt klikken en kiezen voor "Implement interface". En presto!
Merk op dat VS de nieuwere EBM syntax hier hanteert bij properties. Meer informatie hierover vind je in de appendix.
We kunnen is gebruiken om te weten of een klasse een specifieke interface heeft. Dit laat ons toe om code te schrijven die weer een beetje meer polyvalent wordt.
Stel dat we volgende klassen hebben waarbij de Boek klasse de IVerwijderbaar interface implementeert:
interface IVerwijderbaar{ ... };
internal class Boek: IVerwijderbaar { ... };
internal class Persoon { ... };
We kunnen nu met is objecten bevragen of ze de interface in kwestie hebben:
Persoon tim = new Persoon();
Boek gameOfThrones = new Boek();
if(gameOfThrones is IVerwijderbaar)
{
Console.WriteLine("Ik kan Game of Thrones verwijderen");
}
if(tim is IVerwijderbaar)
{
Console.WriteLine("Ik kan Tim verwijderen");
}
De output zal worden: Ik kan Game of Thrones verwijderen.
Net zoals bij onze voorbeelden over polymorfisme en is zal de kracht van interfaces pas zichtbaar worden wanneer we met arrays of lijsten van objecten werken. Indien deze lijst een bont allegaartje objecten bevat, allemaal met specifieke parents én interfaces, dan kunnen we weer met is bijvoorbeeld alle objecten benaderen die een bepaalde interface hebben:
foreach(var persoon in WerkNemers)
{
if(persoon is IManager)
{
//...
}
}
Een nadeel van overerving is dat een klasse maar van 1 klasse kan overerven. Een klasse mag echter wel meerdere interfaces met zich meedragen:
interface ISuperHeld{...}
interface ICoureur{...}
internal class Man {...}
internal class Zorro:Man, ISuperHeld
{...}
internal class Batman:Man, ISuperHeld, ICoureur
{...}
Merk op dat de volgorde belangrijk is: eerst plaats je de klasse waarvan wordt overgeërfd, dan pas de interface(s).
Ook mogen interfaces van elkaar overerven:
interface IGod:ISuperHeld
{ }
In kleine projecten lijken interfaces wat overkill, en dat zijn ze vaak wel. Van zodra je een iets complexer project krijgt met meerdere klassen die onderling met elkaar allerlei zaken moeten doen, dan zijn interfaces je dikke vrienden!
Je hebt misschien al over de SOLID programmeerprincipes gehoord?
And if not, niet erg.
Samengevat zegt SOLID dat we een bepaalde hoeveelheid abstractie inbouwen enerzijds (zodat we niet de gore details van klassen moeten kennen om er mee te programmeren) anderzijds dat er een zogenaamde 'separation of concerns' (SoC) moet zijn (ieder deel/klasse/module van je code heeft een specifieke opdracht).
Met interfaces kunnen we volgens de SOLID principes programmeren: het boeit ons niet meer wat er in de klasse zit, we kunnen gewoon aan de interfaces van een klasse zien wat hij kan doen. Handig toch!
In het vorige hoofdstuk gaf ik een voorbeeld van een klasse EersteMinister die enkele Minister-klassen gebruikte om hem of haar te helpen.
Een nadeel van die aanpak is dat al onze Ministers maar 1 "job" kunnen hebben: ze erven allemaal over van Minister en kunnen nergens anders van overerven (geen multiple inheritance is toegestaan in C#). Je wordt uiteraard niet geboren als Minister. Het zou dus handig zijn dat ook andere mensen Minister kunnen worden, zonder dat ze hun bestaande expertise moeten weggooien.
Via interfaces kunnen we dit oplossen. Een Minister gaan we dan eerder als een "bij-job" beschouwen en niet de hoofdreden van een klasse.
We definiëren daarom eerst een nieuwe interface IMinister:
interface IMinister
{
void Adviseer();
}
Vanaf nu kan eender wie die deze interface implementeert de EersteMinister advies geven. Hoera! En daarnaast kan die klasse echter ook nog tal van andere zaken doen. Beeld je in dat een CEO van een bedrijf ook minister bij de EersteMinister wilt zijn, zoals deze:
internal class Ceo
{
public void MaakJaarlijkseOmzet()
{
Console.WriteLine("Geld!!!");
}
public void OntslaDepartement()
{
Console.WriteLine("You're all fired!");
}
}
Nu we de interface IMinister hebben kunnen we deze klasse aanvullen met deze interface zonder dat de bestaande werking van de klasse moet aangepast worden:
internal class Ceo: IMinister
{
public void Adviseer()
{
Console.WriteLine("Vrijhandel is essentieel!");
}
//gevolgd door de reeds bestaande methoden
De CEO kan dus z'n bestaande job blijven uitoefenen maar ook als Minister optreden.
Ook de EersteMinister moet aangepast worden om nu met een lijst van IMinister ipv Minister te werken. Dankzij polymorfisme is dat erg eenvoudig!
internal class MisterEersteMinister
{
public void Regeer()
{
List<IMinister> AlleMinisters = new List<IMinister>();
AlleMinisters.Add(new Ceo);
foreach (IMinister minister in AlleMinisters)
{
minister.Adviseer();
}
}
}
De eerder beschreven MinisterVanMilieu, MinisterBZ en MinisterVanEconomie dienen ook niet meer van de abstracte klasse Minister over te erven en kunnen gewoon de interface implementeren. Enkel lijn 1 moet hierbij aangepast worden:
En bij deze hebben we dankzij interfaces, compositie en polymorfisme, ervoor gezorgd dat eender wie Minister kan worden zonder dat dat die daarvoor z'n bestaande job moet opzeggen. OOP laat ons echt toe de realiteit zo dicht mogelijk te benaderen!
De bestaande .NET klassen gebruiken vaak interfaces om bepaalde zaken uit te voeren. Zo heeft .NET tal van interfaces gedefiniëerd (bv. IEnumerable, IDisposable, IList, IQueryable enz.) waar je zelfgemaakte klassen mogelijk aan moeten voldoen indien ze bepaalde bestaande methoden wensen te gebruiken.
Een typisch voorbeeld is het gebruik van de Array.Sort methode. Hier wordt het echte nut van interfaces erg duidelijk: de ontwikkelaars van .NET kunnen niet voorspellen hoe andere ontwikkelaars hun bibliotheken gaan gebruiken. Via interfaces geven ze als het ware krijtlijnen en vanaf dan moeten de ontwikkelaars zelf maar bepalen hoe hun nieuwe klassen zullen samenwerken met die van .NET.
Een veelgebruikte .NET interface is de IComparable interface. Deze wordt gebruikt indien .NET bijvoorbeeld een array van objecten wil sorteren. Bij wijze van demonstratie zal ik demonstreren waarom deze interface erg nuttig kan zijn.
Indien je een array van objecten hebt en je wenst deze te sorteren via Array.Sort dan dienen de objecten de IComparable interface te hebben.
We willen een array van landen kunnen sorteren op grootte van oppervlakte.
Stel dat we de klasse Land hebben:
internal class Land
{
public string Naam {get;set;}
public int Oppervlakte {get;set;}
public int Inwoners {get;set;}
}
We plaatsen 3 landen in een array:
Land[] eurolanden = new Land[3];
eurolanden[0] = new Land() {Naam = "België", Oppervlakte = 5, Inwoners = 2000};
eurolanden[1] = new Land() {Naam = "Frankrijk", Oppervlakte = 7, Inwoners = 2500};
eurolanden[2] = new Land() {Naam = "Nederland", Oppervlakte = 6, Inwoners = 1800};
Wanneer we nu zouden proberen de landen te sorteren:
Array.Sort(eurolanden);
Dan treedt er een uitzondering op:InvalidOperationException: Failed to compare two elements in the array. Dit is erg logisch: .NET heeft geen flauw benul hoe objecten van het type Land moeten gesorteerd worden. Moet dit alfabetisch volgens de Naam property, of van groot naar klein op aantal Inwoners? Enkel jij als ontwikkelaar weet momenteel hoe er gesorteerd moet worden.
We kunnen dit oplossen door de IComparable interface in de klasse Land te implementeren. We bekijken daarom eerst de documentatie van deze interface1. De interface is beschreven als:
interface IComparable
{
int CompareTo(Object obj);
}
OPGELET: Deze interface bestaat al in .NET en mag je dus niet opnieuw in code schrijven!
Daarbij moet de methode een int teruggeven als volgt:
Waarde
Betekenis
Getal kleiner dan 0
Huidig object komt voor het obj dat werd meegegeven.
0
Huidig object komt op dezelfde positie als obj.
Getal groter dan 0
Huidig object komt naobj.
De Array.Sort methode zal werken tegen deze IComparable interface om juist te kunnen sorteren. Het verwacht dat de klasse in kwestie een int teruggeeft volgens de afspraken van de tabel hierboven.
We zorgen er nu voor dat Land deze interface implementeert. Daarbij willen we dat de landen volgens oppervlakte worden gesorteerd :
internal class Land: IComparable
{
public int CompareTo(object obj)
{
Land temp = obj as Land;
if(temp != null)
{
if(Oppervlakte > temp.Oppervlakte)
return 1;
if(Oppervlakte < temp.Oppervlakte)
return -1;
return 0;
}
else
throw new NotImplementedException("Object is not a Land");
}
}
Nu zal de Sort werken:
Array.Sort(eurolanden);
De Sort()-methode kan nu ieder object bevragen via de CompareTo()-methode en zo volgens een eigen interne sorteeralgoritme de landen in de juiste volgorde plaatsen.
Stel dat vervolgens nog beter willen sorteren: we willen dat landen met een gelijke oppervlakte, op hun aantal inwoners gesorteerd worden:
public int CompareTo(object obj)
{
Land temp = obj as Land;
if(temp != null)
{
if(Oppervlakte > temp.Oppervlakte) return 1;
if(Oppervlakte < temp.Oppervlakte) return -1;
if(this.Inwoners > temp.Inwoners) return 1;
if(this.Inwoners < temp.Inwoners) return -1;
}
else
throw new ArgumentException("Object is not a Land");
}
Ik laat jou de code schrijven wat er moet gebeuren indien het aantal inwoners én de oppervlakte dezelfde is. Misschien kan je dan sorteren volgens de Naam van het land.
De bestaande datatypes in .NET hebben allemaal de IComparable interface ingebakken. Zo ook dus de gekende primitieve datatypes. string dus ook en laat dus toe om bijvoorbeeld snel te weten welke van 2 string alfabetisch eerst komt, als volgt:
return this.Naam.CompareTo(temp.Naam);
Kortom, voeg dit achteraan de eerder geschreven vergelijkingen in je Land-klasse om finaal de Naam te gebruiken als sorteer-element.
Indien je een List<Land> zou willen sorteren in plaats van een array van Land dan kan dit ook. Nog steeds vereisen we dat je klasse de IComparable interface gebruikt. We kunnen nu de ingebouwde Sort-methode van de List klasse gebruiken. Stel dat je een lijst van landen hebt genaamd landLijst, deze sorteren kan dan heel eenvoudig als volgt:
landLijst.Sort();
Zo simpel!
Merk op dat we hier de lijst zelf sorteren. Er wordt dus geen nieuwe lijst teruggegeven zoals bij Array.Sort() het geval is.
Indien je toch liever Array.Sort gebruikt dan kunnen we een andere, handige, ingebouwde List-methode gebruiken, namelijk ToArray(), als volgt:
De eigenschappen van polymorfisme en interfaces combineren kan tot zeer krachtige code resulteren. Wanneer we dan ook nog eens de is en as keywords gebruiken is het hek helemaal van de dam. Als afsluiter van deze lange reis in OOP-land zal ik daarom een voorbeeld geven waarin de verschillende OOP-concepten samenkomen om ... vloekende mensen op het scherm te tonen.
Het idee is het volgende: mensen kunnen spreken. Leraars, studenten, politieker, en ja zelfs advocaten zijn mensen. Echter, enkel politiekers en advocaten hebben ook de interface IVloeker die hen toelaat eens goed te vloeken. Brave leerkrachten en studenten doen dat niet (kuch). We willen een programma dat lijsten van mensen bevat waarbij we de vloekers kunnen doen vloeken zonder complexe code te moeten schrijven.
We hebben volgende klasse-structuur:
Als basis klasse Mens hebben we:
internal class Mens
{
public void Spreek()
{
Console.WriteLine("Hoi!");
}
}
Voorts definiëren we de interface IVloeker als volgt:
interface IVloeker
{
void Vloek();
}
We kunnen nu de nodige child-klassen maken:
De niet-vloekers: Leraar en Student
De vloekers: Advocaat en Politieker
internal class Leraar:Mens {} //moet niets speciaal doen
internal class Student:Mens{} //ook studenten doen niets speciaal
internal class Politieker: Mens, IVloeker
{
public void Vloek()
{
Console.WriteLine("Godvermiljaardedju, zei de politieker");
}
}
internal class Advocaat: Mens, IVloeker
{
public void Vloek()
{
Console.WriteLine("SHIIIIT, zei de advocaat");
}
}
We maken een array van mensen aan waarin we van iedere type een vertegenwoordiger plaatsen (uiteraard had dit ook in een List<Mens> kunnen gebeuren):
Mens[] mensjes = new Mens[4];
mensjes[0] = new Leraar();
mensjes[1] = new Politieker();
mensjes[2] = new Student();
mensjes[3] = new Advocaat();
for(int i = 0; i < mensjes.Length; i++)
{
//NOW WHAT?
Het probleem: hoe kan ik in de array van studenten, leraren, advocaten en politiekers enkel de vloekers laten vloeken?
De eerste oplossing is door gebruik te maken van het is keyword.
We zullen de array doorlopen en steeds aan het huidige object vragen of dit object de IVloeker interface bezit, als volgt:
for(int i = 0; i<mensjes.Length; i++)
{
if(mensjes[i] is IVloeker)
{
//NOW WHAT?
}
else
{
mensjes[i].Spreek();
}
}
Vervolgens kunnen we binnen deze if het huidige object tijdelijk omzetten (casten) naar een IVloeker object en laten vloeken:
if(mensjes[i] is IVloeker)
{
IVloeker tijdelijk = (IVloeker)mensjes[i];
tijdelijk.Vloek();
}
Het as keyword kan ook een toffe oplossing geven. Hierbij zullen we het object proberen om te zetten via as naar een IVloeker. Als dit lukt (het object is verschillend van null) dan kunnen we het object laten vloeken:
Hopelijk hebben voorgaande voorbeelden je een beetje hebben kunnen doen proeven van de kracht van interfaces. Gedaan met ons druk te maken wat er allemaal in een klasse gebeurt. Werk gewoon 'tegen' de interfaces van een klasse en we krijgen de ultieme black-box revelatie! See what I did there?
Op vraag van velen is het nu tijd om één van de meest gebruikte .NET namespaces te bekijken: System.IO1.
Vergeet zeker niet bovenaan je code using System.IO; toe te voegen indien je ook maar één voorbeeld uit dit hoofdstuk wilt kunnen maken.
De System.IO namespace is een zeer uitgebreide bibliotheek die alle methoden bevat die je nodig hebt om input en output (I/O) operaties te verrichten. Dit betekent dat je met behulp van deze namespace bestanden en folders (ook wel mappen of directories genoemd) kunt uitlezen, schrijven, maken en verwijderen, en zo voort.
Het zal je met andere woorden toelaten om toegang te krijgen tot, onder andere, het lokale bestandssysteem.
...met alle voor-en nadelen als gevolg. Je zal namelijk rechtstreeks:
Wijzigingen op je harde schijf kunnen aanbrengen. Het is belangrijk om voorzichtig te zijn wanneer je werkt met bestanden en folders. Eén kleine fout kan leiden tot het verwijderen van belangrijke bestanden of gegevensverlies. En ja, ook ik heb dit al meegemaakt.
Niet altijd de juiste gebruikersrechten hebben om bepaalde I/O bewerkingen uit te voeren. Dit hangt af van de rechten die je gecompileerde programma heeft binnen het besturingssysteem. Zorg ervoor dat je controleert of je voldoende rechten hebt voordat je probeert een bestand te lezen of te schrijven.
Enkele tips voor je begint
Om de voorgaande waarschuwing te benadrukken, nog 2 belangrijke tips:
Back-ups: Backups maken is altijd belangrijk. Maar de voorbije 17 hoofdstukken heb je normaal gezien nooit code geschreven die effectief zaken kon kapot maken op je computer. Daar komt dus vanaf nu verandering in. Tijd dus voor die wekelijkse backup!
Try-catch gebruiken: Eigenlijk hebben we voorlopig maar beperkt aan exception handling moeten doen. 99% van de tijd wisten we heel goed welke uitzonderingen konden optreden en schreven we onze code er naar. Echter, vanaf nu zal je programma ook zaken benaderen buiten het programma. Tot aan dit hoofdstuk was enkel de gebruikersinput iets dat van buiten kwam. We waren meestal zelf de eindgebruiker, en gingen uit van foutloze invoer (ik weet het, naïef). Bestanden luisteren echter niet zo goed. Het kan dus goed zijn dat een bestand toch niet op die plaats staat waar je dacht dat het stond, of dat je toch niet de juiste rechten hebt. Kortom,exception handling zal vanaf nu essentieel worden.
Ieder bestand en folder op je harde schijf wordt gedefinieerd door een unieke locatie, path genoemd. Als je een bestand genaamd mijnData.txt hebt in de "temp"-folder van je c-schijf, dan is het full path van dit bestand:
c:\temp\mijnData.txt
Folders hebben ook een path, in het vorige voorbeeld is het full path van de temp-folder:
c:\temp\
In C# zullen deze paths altijd als string worden verwerkt.
Let er op dat een path niet hoofdlettergevoelig is. Je kan dus geen 2 bestanden met de naam "mijnData.txt" en "MijnData.TXT" in dezelfde folder hebben. Zowel Windows als Mac OS hebben een niet hoofdlettergevoelige bestandsstructuur.
Bij MacOS werkt men met forward slashes in plaats van backward slashes.
Als je geen specifiek path aangeeft wanneer je een bestand wilt gebruiken, gaat je programma ervan uit dat het zich in de folder van het programma zelf zich bevindt. Voor de meeste projecten is dit meestal de \bin\Debug-folder tijdens het ontwikkelen en testen.
Volgende voorbeeld (we lopen even al vooruit) zal de tekst "Het einde is nabij" wegschrijven naar een bestand "doem.txt" op één van volgende locaties:
Lijn 1: Naar de plek waar het programma wordt uitgevoerd.
Lijn 2: Naar de temp-folder.
File.WriteAllText("doem.txt", "Het einde is nabij");
File.WriteAllText(@"c:\temp\doem.txt", "Het einde is nabij");
In het tweede geval is belangrijk te controleren of je wel schrijfrechten hebt voor die folder. Heb je die niet dan zal je een UnauthorizedAccessException krijgen. We gebruiken dus best exception handling wanneer we met bestanden werken.
try
{
File.WriteAllText("doem.txt", "Het einde is nabij");
}
catch(UnauthorizedAccessException)
{
Console.WriteLine($"Geen schrijfrechten!")
}
Het is niet altijd duidelijk of je applicatie op een Mac of Windows zal uitgevoerd worden. Je kan er dus maar beter rekening mee houden dat je applicatie soms met andere paths zal werken dan je gewend bent (Mac OS werkt bijvoorbeeld niet met een "c:"-schijf notatie). Het is daarom veiliger om te werken met de System.IO.Path-klasse, die ons in staat stelt om op een platformonafhankelijke manier met paden en bestandsnamen te werken.
Stel dat we een bestandsnaam willen samenstellen uit verschillende delen, dan gebruiken we hier de erg nuttige Combine-methode voor:
Afhankelijk van het besturingssystemen zal de output dus verschillend zijn. Op Windows:
data\dagboek.txt
Op Mac OS wordt dit echter:
data/dagboek.txt
De Path-klasse heeft ook nog tal van nuttige methode zoals: ChangeExtension, GetDirectoryName, GetFileNameWithoutExtension, GetFullPath, enz. Met behulp van de GetRandomFileName-methode kan je een willekeurige folder- of bestandsnaam verkrijgen. Dit is handig als je een tijdelijke bestand wil aanmaken en zeker wil zijn dat de naam niet al bestaat. Een andere handige methode is GetTempPath, deze geeft je het path naar de temp-folder van de huidige gebruiker. Het is een goede gewoonte om tijdelijke werkbestanden voor je applicatie in deze folder te plaatsen. En het is nog toffer als je deze ook verwijderd wanneer ze niet meer nodig zijn.
Soms wil je bestanden opslaan in speciale folders zoals op het bureaublad. Hiervoor kun je de Environment.GetFolderPath-methode gebruiken. Deze methode vereist een parameter van het type Environment.SpecialFolder, wat een ingebouwde enum is. Deze enum bevat een hele hoop gekende locaties van Windows-folders, zoals het bureaublad, de temp-folder, "Mijn documenten"-folder, enz. Dit zorgt ervoor dat je bestand altijd op de juiste plek komt, ongeacht de gebruikersomgeving.
In dit voorbeeld plaatsen we ons onheilspellende bericht op het bureaublad van de huidige gebruiker:
string desktopPath = Environment.GetFolderPath(Environment.SpecialFolder.Desktop);
string fullPath = Path.Combine(desktopPath, "doem.txt");
File.WriteAllText(fullPath, "Het einde is nabij");
Het is een goede gewoonte om steeds te controleren of een bestand of folder al bestaat, voor je ermee gaat werken. Soms wil je een bestaand bestand zeker niet overschrijven. Of wil je een folder aanmaken als deze nog niet bestaat. Controleer dit dus altijd in je programma én vraag aan de gebruiker wat te doen bij twijfel. Overschrijf of verwijder nooit een bestand of folder zonder de gebruiker hierover te waarschuwen. Zeker wanneer het om een bestand gaat dat niet door jouw programma beheerd wordt.
Het controleren of een bestand bestaat doe je met de File.Exists-methode:
if(File.Exists(desktopPath))
{
//werk met bestand
}
else
{
Console.WriteLine("Dit bestand bestaat niet.");
}
Het controleren van het bestaan van een folder doe je met Directory.Exists():
if(Directory.Exists(tempPath))
{
//werk met folder
}
Om de voorbeeldcode in dit hoofdstuk behapbaar te houden, zullen we niet telkens overal deze controle doen.
De locaties en paths van bestanden kennen is...interessant. Het wordt natuurlijk pas echt nuttig wanneer we de inhoud van bestanden kunnen uitlezen en aanpassen. Daarvoor zijn we hier natuurlijk.
Er is geen vaste manier om dit te doen. Alles hangt af van je specifieke probleem. We zullen daarom enkele veel gebruikte use-cases bekijken.
Met behulp van een StreamWriter kan je data naar een bestand (of een andere streambron) wegschrijven. Het gebruik ervan is verrassend eenvoudig.
StreamWriter writer = new StreamWriter("doeeeeeem.txt",true):
writer.WriteLine("Game over!");
Inderdaad, net zoals je bij de Console-klasse WriteLine hebt, heb je dat ook hier om tekst naar een bestand te schrijven.
Wanneer we een writer-object aanmaken, geven we ook een tweede parameter (true) mee. Dit geeft aan dat de tekst achter de bestaande inhoud van het bestand moet worden toegevoegd (to append). Indien je false meegeeft dan zal de inhoud van het bestand verwijderd worden en start je van een nieuw, leeg bestand.
En ja, uiteraard is er dus ook een manier om tekst uit een bestand te lezen. De StreamReader heeft onder andere een ReadLine methode die dit toelaat. De extra moeilijkheid bij het uitlezen van bestanden is dat we goed moeten nakijken of er nog iets uit te lezen valt. Dit kun je enigszins vergelijken met het uitlezen van een array, want ook daar moeten we opletten dat we niet voorbij de grenzen van de array gaan.
Volgende voorbeeld gebruikt een StreamReader om ons tekstbestand lijn per lijn op het scherm te tonen:
StreamReader reader = new StreamReader("doeeeeeem.txt");
string regel;
while ((regel = reader.ReadLine()) != null)
{
Console.WriteLine(regel);
}
De conditie op lijn 4 verdient wat toelichting. We doen hier 2 zaken:
We lezen de volgende lijn uit met behulp van ReadLine.
Wanneer we aan het einde van het bestand zijn zouden we null terugkrijgen uit ReadLine. Daarom dat we vervolgens hierop controleren. Enkel als we dus effectief nog tekst uitlezen mogen we nogmaals in de loop gaan.
In een ver verleden (hoofdstuk 10) hadden we het al even over using en hoe het gebruikt wordt om aan te geven dat de compiler ook een specifieke namespace mag gebruiken. Wel, het using keyword heeft ook nog een alternatief gebruik in C#.
Het using keyword kan ook worden gebruikt om een bepaald stuk code binnen een codeblok te definiëren waarin een object wordt aangemaakt, gebruikt en vervolgens op de juiste manier wordt verwijderd zodra het blok is uitgevoerd.
Dit is vooral handig bij het werken met bestanden. Het zal ervoor zorgen dat het bestand correct wordt vrijgegeven aan het besturingssysteem, zelfs wanneer er fouten optreden. Beeld je in dat je programma crasht wanneer je net naar een bestand schrijft: hierdoor bestaat de kans dat het bestand gelockt wordt waardoor andere applicaties niet aan het bestand aan kunnen. Niet handig.
De vorm van een using-codeblock ziet er als volgt uit:
using (resource aanmaken dat netjes moet worden opgeruimd)
{
}
Volgend voorbeeld, waarin we een StreamWriter gebruiken, toont de werking ervan:
using (StreamWriter writer = new StreamWriter("doem.txt"))
{
writer.WriteLine("Het einde is nabij!");
writer.WriteLine("Hou vol!");
}
Wanneer de accolades van lijn 5 worden bereikt, zal het object dat in lijn1 werd aangemaakt, proper afgesloten worden. C# zal de Dispose-methode1 van het writer-object aanroepen zodat het bestand terug vrijgegeven wordt.
1
De Dispose methode wordt aangeroepen om bestanden, folders of andere resources expliciet vrij te geven wanneer ze niet langer nodig zijn. Dit voorkomt geheugenlekken en verhoogt de efficiëntie van de toepassing. De methode zit ingebakken in veel klassen die werken met zaken zoals bestanden, netwerkverbindingen, etc. Al deze klassen implementeren de IDisposable interface en hebben daarom de Dispose methode.
Dankzij StreamReader en StreamWriter hebben we nu reeds een goede greep op werken met bestanden. Laten we eens alles combineren tot een functioneel programma. We maken een dagboek-programma. Telkens het programma opstart zal het de reeds bestaande dagboek-schrijfsels tonen. Vervolgens kan de gebruiker een nieuwe tekst toevoegen. Nadien sluit het programma af. We gebruiken DateTime.Now om ieder schrijfsel van een duidelijke tijd en datum te voorzien:
string dagboekPath = "dagboek.txt";
if (!File.Exists(dagboekPath))
{
File.Create(dagboekPath);
}
// dagboek tonen
Console.WriteLine("Dagboek:");
using (StreamReader reader = new StreamReader(dagboekPath))
{
string regel;
while ((regel = reader.ReadLine()) != null)
{
Console.WriteLine(regel); //
}
}
//dagboek schrijven
Console.WriteLine("\nGeef je volgende dagboekschrijfsel:");
string entry = Console.ReadLine();
using (StreamWriter writer = new StreamWriter(dagboekPath,true))
{
writer.WriteLine($"\n{DateTime.Now}");
writer.WriteLine(entry);
}
Totnogtoe werkten we enkel met tekstbestanden om strings uit te lezen. Uiteraard hoeft dit niet, maar het is wel eenvoudig. Soms wil je echter ook binaire bestanden aanmaken en verwerken. Dat kan met de BinaryWriter en BinaryReader. Dit is echter iets complexer.
De extra moeilijkheid is het feit dat we nu niet meer beperkt zijn tot het wegschrijven van strings. We kunnen perfect een bestand aanmaken dat een opeenvolging van waardes bevat met allemaal verschillende datatypes. Vooral bij het uitlezen zal dit die extra complexiteit én foutgevoeligheid geven.
Om een bestand te openen met een BinaryWriter gebruiken we de File-klasse. We moeten daarbij ook expliciet aangeven hoe het bestand moet aangemaakt worden (indien het niet bestaat):
FileStream fs = File.Open("bondData.dat", FileMode.Create);
using (BinaryWriter writer = new BinaryWriter(fs))
{
//...
Het tweede argument bij de Open-methode is een enum die verschillende mogelijkheden heeft:
Append: Opent een bestaand bestand en plaatst de schrijfpositie aan het einde van het bestand, zodat nieuwe data aan het einde worden toegevoegd. Als het bestand niet bestaat, wordt er een FileNotFoundException gegenereerd.
Create: Maakt een nieuw bestand aan. Als het bestand al bestaat, wordt het overschreven.
CreateNew: Maakt een nieuw bestand aan. Als het bestand al bestaat, wordt er een IOException gegenereerd.
Open: Opent een bestaand bestand. Als het bestand niet bestaat, zal er een FileNotFoundException worden gegenereerd.
OpenOrCreate: Opent een bestaand bestand als het bestaat. Als het bestand niet bestaat, wordt er een nieuw bestand aangemaakt.
Truncate: Opent een bestaand bestand en snijdt de inhoud af, waardoor het bestand leeg wordt. Als het bestand niet bestaat, wordt er een FileNotFoundException gegenereerd.
Toegegeven, het is niet altijd erg intuïtief welke modus je juist nodig zal hebben. Alles hangt af van het specifieke probleem dat je wenst op te lossen.
Het andere verschil met de TextWriter is dat je nu alleen een Write-methode gaat gebruiken. Deze methode accepteert elk datatype. En dat is het grote verschil: met een BinaryWriter kunnen we elk datatype wegschrijven!
In volgende voorbeeld schrijven we 3 verschillende zaken weg, een string, een int en uiteindelijk een bool:
var fs = File.Open("bondData.dat", FileMode.Create);
using (BinaryWriter writer = new BinaryWriter(fs))
{
writer.Write("Bond");
writer.Write(7);
writer.Write(true);
}
Dit genereert een bestand van 10 bytes. Als we dit bestand vervolgens op binair niveau zouden bekijken, zouden we ontdekken dat de grootte van het bestand exact gelijk is aan de individuele groottes van de drie variabelen:
De string Bond bestaat uit 4 karakters, elk 1 byte groot, plus 1 extra byte om de lengte van de string aan te geven. Dus in totaal 5 bytes.
De integer vereist 4 bytes.
De boolean vereist slechts 1 byte.
Stel nu dat we een complexer voorbeeld hebben waarbij we nog meer typen data willen wegschrijven, zoals een double en een char:
var fs = File.Open("bondDataAdvanced.dat", FileMode.Create);
using (BinaryWriter writer = new BinaryWriter(fs))
{
writer.Write("Gadget");
writer.Write(42);
writer.Write(false);
writer.Write(3.14159);
writer.Write('A');
}
In dit voorbeeld zou de bestandsgrootte als volgt worden berekend:
De string is 6 karakters lang + 1 byte voor de lengte: 6 bytes + 1 byte = 7 bytes.
De integer beslaat 4 bytes.
De boolean beslaat 1 byte.
De double beslaat 8 bytes.
De char beslaat 1 bytes.
De totale bestandsgrootte zal daarom 21 bytes zijn.
Om binaire bestanden uit te lezen hebben we een BinaryReader-object nodig. Deze klasse heeft aller ReadX-methoden, waarbij X het datatype aangeeft dat je wilt uitlezen.
Bij het schrijven hoefden we nog niet echt na te denken over de volgorde. Bij het lezen is dit uiteraard cruciaal. Het is essentieel dat we weten in welke volgorde de data in het bestand staat. Als we bijvoorbeeld eerst een int en daarna een char hebben weggeschreven, dan moeten we bij het uitlezen exact die volgorde aanhouden. Anders zal de binaire informatie uit het bestand op een verkeerde manier worden verwerkt, wat kan leiden tot onjuiste data of zelfs een crash.
De Read-methode van de BinaryReader heeft varianten voor ieder primitief datatype beschikbaar in C#. Zo zijn er onder andere:ReadBoolean, ReadByte, ReadChar, ReadDecimal, ReadDouble, ReadInt16 (voor short), ReadInt32 (voor int), ReadInt64 (voor long), ReadSingle (voor float), ReadString, ReadUInt16 (voor ushort), ReadUInt32 (voor uint).
Hierdoor kunnen we specifiek aangeven welk type data we willen inlezen en kan de BinaryReader de bytes correct interpreteren.
Als we dus het bondData.dat bestand vervolgens willen uitlezen dan moet dit als volgt:
var fs = File.Open("bondData.dat", FileMode.Open);
using (BinaryReader reader = new BinaryReader(fs))
{
string naam = reader.ReadString();
int code = reader.ReadInt32();
bool leeftNog = reader.ReadBoolean();
Console.WriteLine($"{naam} ({code}). Leeft nog = {leeftNog}");
}
Merk op dat we deze keer de modus FileMode.Open hanteren bij het openen van het bestand.
Test gerust eens wat er zou gebeuren als je een van de Read-methode van volgorde zou veranderen. Meestal zal je een uitzondering krijgen omdat de methoden de in te lezen bytes niet begrijpen en kunnen omzetten naar het verwachte datatype.
Als we in het voorgaande voorbeeld lijn 4 en 5 zouden omwisselen dan crasht onze applicatie met een EndOfStreamException.
De File-klasse heeft een handige methode ReadAllBytes waarmee je snel de binaire inhoud van een bestand kunt bekijken. Deze methode is nuttig wanneer je de exacte gegevens van een bestand wilt inspecteren.
De ReadAllBytes methode zal een array van byte teruggeven die we vervolgens kunnen overlopen in een loop. Als handigheidje gebruiken een string formatter X2 (zie hoofdstuk 4) om de bytes als hexadecimale waarden af te drukken:
byte[] inhoud = File.ReadAllBytes("bondData.dat");
foreach (byte b in inhoud)
{
Console.Write($"{b:X2} ");
}
Dit geeft volgende output:
04 42 6F 6E 64 07 00 00 00 01
De eerste byte (04) geeft de lengte van de string aan die volgt, 4 dus. De volgende 4 bytes, 42 6F 6E 64 zijn de Unicode waarden voor de letters "b, o, n , d".
Vervolgens hebben we 4 byes om het getal 7 voor te stellen (07 00 00 00). Finaal hebben we nog de byte-waarde 01 die de bool op true voorstelt.
Vond je het vreemd dat 7 binair als 07 00 00 00 werd voorgesteld?
Dit komt doordat het getal 7 wordt opgeslagen als een 4-byte little-endian getal. In little-endian-notatie wordt de minst significante byte (least significant byte of LSB) eerst opgeslagen. Voor het getal 7 betekent dit dat de hexadecimale waarde 07 in de eerste byte komt, gevolgd door drie nullen omdat de overige bytes geen bijdrage leveren aan de waarde van het getal.
Als we daarentegen het getal 1000 willen voorstellen, 3E8 hexadecimaal, die we in little-endian volgorde opslaan als E8 03 00 00. Hier wordt de LSB E8 (de laagste byte) als eerste byte opgeslagen, gevolgd door 03 en daarna twee nullen om de 4-byte structuur te vervolledigen, aangezien 3E8 in 32-bits binaire vorm wordt opgeslagen.
Nadat het fileInfo object werd aangemaakt krijg je via een hele resem properties toegang tot detail-informatie over het bestand in kwestie, zoals:
Methode
Info
Voorbeeldoutput
Name
Bestandsnaam
"temp.txt"
FullName
Volledige pad van het bestand
c:\temp\temp.txt
Extension
Bestandsextensie
".txt"
Length
Bestandsgrootte in bytes
21
CreationTime
DateTime object met datum en tijd waarop het bestand is aangemaakt
11/06/2024 10:17:21
LastAccessTime
Laatste keer dat het bestand is geopend
idem
LastWriteTime
Laatste keer dat het bestand is gewijzigd
idem
Exists
boolean die aangeeft of het bestand bestaat
true
Het gebruik van deze properties wijst zichzelf uit (uiteraard zijn dit allemaal read-only properties):
FileInfo info = new FileInfo("bondData.dat");
if (info.Exists)
{
Console.WriteLine($"Bestandsnaam: {info.Name}");
Console.WriteLine($"Bestandsgrootte: {info.Length/1024} kB");
}
Van zodra je een FileInfo-object hebt, krijg je beschikking over tal van handige methoden. We gaan de 3 nuttigste (CopyTo, MoveTo en Delete) eens tonen in een domme demo:
FileInfo info = new FileInfo("bondData.dat");
if(info.Exists)
{
fileInfo.CopyTo("supermanData.dat");
fileInfo.MoveTo("bond2Data.dat");
fileInfo.Delete();
}
Als we deze code uitvoeren zullen er 3 zaken gebeuren, op voorwaarde dat het bestand bondData.dat beschikbaar:
Lijn 4: Een tweede bestand supermanData.dat wordt aangemaakt en zal dezelfde informatie als het originele bestand bevatten.
Lijn 5: Het bestand bondData.dat wordt hernoemd naar bond2Data.dat.
Lijn 6: Het originele bestand wordt verwijderd. Ook al werd het hernoemd.
Lijn 7: Als we nu de folder zouden bekijken waar de applicatie werd uitgevoerd, dan zouden we enkel nog een bestand met de naam "supermanData.dat" zien staan.
De System.IO namespace is een nogal verwarrende klasse. Je kan dezelfde zaken op verschillende manieren doen. Er zijn verschillende Readers en Writers. Soms gebruik je static-methoden, soms object-methoden. Wat is het nu? Lig er niet te hard van wakker! Je bent nog maar aan het prille begin van je C# carrière en zal de komende jaren zeker beter aanvoelen wanneer je welke oplossingsstrategie moet toepassen.
Toch willen we kort toelichten wat het verschil is tussen File en FileInfo. Je hebt gezien dat ik ze beide doorheen dit hoofdstuk door elkaar gebruikte. Beide klassen hebben veel gelijkaardige functionaliteiten, maar de File-klasse is een static klasse. Terwijl FileInfo dat niet is.
De File vereist dus niet dat je telkens een object aanmaakt wanneer je snel iets met een bestand wenst te doen. Bij FileInfo doen we dit uiteraard wel, waarbij we het path naar het te gebruiken bestand meegeven.
En hier ligt dan ook direct een groot verschil: de FileInfo heeft bewust een Refresh-methode, omdat het niet kan garanderen dat alle ingelezen informatie later in de code nog relevant is. File zal steeds instantaan met het betrokken bestand werken. FileInfo doet dit enkel tijdens de constructie en bij een Refresh.
Als je meerdere bewerkingen op een bestand wilt doen na elkaar is FileInfo aangeraden, daar je anders meerdere keren de file expliciet zou openen en sluiten met de File klasse. Wil je echter maar kort en krachtig iets met het bestand doen (bv. controleren of het bestaat met File.Exist) dan gebruik je beter de File klasse. Maar toegegeven, dit is geen harde wet. Ik zou daarom momenteel aanbevelen: gebruik wat je zelf het prettigst vindt. Van zodra je professionele code moet beginnen schrijven waarbij performantie en veiligheid belangrijk is, dan wordt het tijd om in-depth na te denken over het gebruik van specifieke klassen.
Uiteraard is er ook een DirectoryInfo klasse. En net zoals FileInfo een tegenhanger in de vorm van de File klasse heeft, zo is er ook de Directory klasse. Ook hier is Directory een static klasse, en DirectoryInfo niet. De uitleg van zonet over het verschil blijft dus ook hier gelden.
Deze klasse geeft dus meer informatie over een folder en het gebruik is identiek aan de FileInfo-klasse. Eerst moet er weer een object van aan gemaakt worden:
DirectoryInfo dirInfo = new DirectoryInfo(@"c:\temp");
Wederom kunnen we de typische properties (LastAccesTime, CreationTime, enz. ) en methoden (Create, Delete, MoveTo enz.) aanroepen.
De DirectoryInfo-klasse heeft nog 2 erg nuttige methoden om te bekijken welke elementen in de folder staan. GetFiles en GetDirectories geven een array van respectievelijk FileInfo en DirectoryInfo objecten terug. Vervolgens kunnen we deze arrays van paths gebruiken om bijvoorbeeld deze bestanden te verwijderen.
Volgende code toont hoe je kunt visualiseren welke elementen zich in de c:\temp-folder bevinden:
DirectoryInfo tempInfo = new DirectoryInfo(@"C:\temp");
if(tempInfo.Exists)
{
var bestanden = tempInfo.GetFiles();
var folders = tempInfo.GetDirectories();
foreach (var folder in folders)
{
Console.WriteLine($"Folder:{folder.Name}");
}
foreach (var bestand in bestanden)
{
Console.WriteLine(bestand.Name);
}
}
De GetFiles-methode aanvaardt enkele handige parameters die je toelaten om naar specifieke bestanden te zoeken.
Ten eerste kan je een searchPattern als string meegeven. Hierbij kan je met behulp van de asterisk (*) en het vraagteken aangeven bepaalde zaken maar te zoeken.
Volgende voorbeeld zal alle bestanden die extensie ".txt" hebben teruggeven:
var tekstBestanden= tempInfo.GetFiles("*.txt");
En deze zal alle bestanden teruggeven wiens bestandsnaam start met "Tim" en dan nog 1 teken bevat. De extensie maakt niet uit:
Via een tweede argument bij GetFiles kan je ook aangeven om niet enkel in de huidige folder te zoeken, maar ook in de subfolders. Volgende voorbeeld zal alle bestanden zoeken die eindigen op ".txt" , inclusief in de subfolders:
var gevonden = tempInfo.GetFiles("*.txt", SearchOption.AllDirectories );
Stel dat je alle subfolders en bestanden in die subfolders wilt oplijsten, inclusief folders in subfolders, en zo voort. Hiervoor bestaat geen ingebouwde .NET methode. Je zal dit dus zelf moeten oplossen, waarbij we een recursie-structuur zullen moeten aanmaken. Een recursieve methode roept zichzelf terug aan tot aan een bepaalde voorwaarde wordt voldaan. In dit geval wanneer er geen nieuwe subfolders meer worden gedetecteerd in de huidige folder.
Volgende methode zal telkens in de huidige folder, die je meegeeft als argument, alle bestanden en folders van oplijsten. Het zal vervolgens zichzelf aanroepen met als argument telkens één van de subfolders in de huidige folder:
static void ToonFoldersEnBestanden(string path)
{
foreach (string bestand in Directory.GetFiles(path))
{
Console.WriteLine(bestand);
}
foreach (string folder in Directory.GetDirectories(path))
{
Console.WriteLine(folder);
ToonFoldersEnBestanden(folder);
}
}
De eerste foreach lijst de bestanden op. De tweede loop zal de folders tonen en ook zichzelf recursief aanroepen.
Een klassieke fout bij recursie is een methode schrijven zonder stopvoorwaarde. Gelukkig hebben we dat probleem hier niet: de methode stopt met zichzelf aanroepen als er geen subfolders meer zijn in de huidige folder.
Pas wel op: als je deze methode uitvoert op bijvoorbeeld "c:", zal er waarschijnlijk heel veel tekst op je scherm verschijnen. Dat kan lang duren.
Uiteraard weet je nu genoeg om informatie uit je klassen naar een bestand te schrijven en vice versa. Zowel de BinaryWriter en TextWriter laten in principe toe om je objectinhoud te bewaren. Bij de TextWriter moeten we dan een hoop data dan de hele tijd converteren van en naar string, wat totaal niet handig werkt. Bij BinaryWriter moeten we dan weer goed uitkijken dat we de data in de juiste volgorde inlezen als dat we ze in de eerste instantie hadden weggeschreven.
Telkens een introductie begint zoals de vorige paragraaf, dan weet je dat er een betere oplossing is. Inderdaad, er zit in C# een ingebakken manier om objecten te serialiseren naar een bestand. Het woord serialiseren dekt de lading: we gaan de inhoud van een object in serie, achter elkaar bewaren en wegschrijven. Uiteraard zullen we ook het omgekeerde proces bekijken, namelijk deserialiseren.
Waarom wil je objecten kunnen serialiseren naar een bestand? Eenvoudig: het laat je toe om de huidige staat van je programma naar een bestand weg te schrijven en later terug op te halen. Je maakt letterlijk een savepoint van je programma en geeft je gebruiker de mogelijkheid om op een later moment vanaf dat punt verder te werken.
Serialiseren naar een binair bestand resulteert in een zeer compact, maar onleesbaar bestand. Dit type bestand is uiterst efficiënt wat betreft opslag en snelheid bij het inlezen. Echter, het aanpassen van een binair bestand is uiterst complex en het biedt geen garantie dat dit bestand nadien nog correct kan worden gedeserialiseerd naar een object. Bovendien is kennis van het exacte binaire formaat vereist om enige aanpassing te maken, wat handmatig werken vrijwel onmogelijk maakt.
Serialiseren naar een tekstbestand geeft daarentegen een zeer leesbaar en dus makkelijker aanpasbaar bestand. Het biedt eveneens het voordeel dat je het bestand eenvoudig kan openen, wijzigen en opslaan met behulp van een eenvoudige teksteditor. We moeten echter nauwkeurig specificeren welk datatype welke string vertegenwoordigt en structuren consequent aanhouden om misverstanden te vermijden.
Het JSON-bestandsformaat (JavaScript Object Notation) combineert het beste van beide werelden. We gaan niet alle details van JSON in dit boek bespreken, daar de essentie ervan zeer eenvoudig is. Een JSON-bestand is ogenblikkelijk herkenbaar en leesbaar:
JSON is de spirituele opvolger van XML. Alhoewel dit bestandsformaat nog steeds populair is, zien we toch dat meer en meer applicaties met JSON beginnen werken. XML-bestanden zijn door de grote hoeveelheid tags net iets minder leesbaar dan JSON-bestanden. Zeg nu zelf:
Met JSON kun je complexe datastructuren representeren zoals arrays en geneste objecten (denk maar aan associaties). Bovendien maakt JSON gebruik van een sleutel-waarde-notatie, wat bijdraagt aan de leesbaarheid. Hier is een meer geavanceerd voorbeeld waarbij we vierkante haken gebruiken om een array van data te beschrijven:
Om klassen in C# te serialiseren naar JSON-bestanden, kun je gebruik maken van de System.Text.Json namespace.
Objecten serialiseren is verrassend eenvoudig en intuïtief.
Voeg de benodigde namespace toe: Zonder deze 3 namespaces kan je uiteraard niets doen in deze sectie:
using System.Text.Json;
using System.Text.Json.Serialization;
using System.IO;
Definieer je klasse: In principe kan je eender welke klasse serialiseren. Oefen echter eerst met kleine, niet complexe klassen. Probeer zeker eerst associaties te vermijden. Dit is trouwens de eerste keer dat je zal ontdekken waarom properties zo belangrijk zijn: enkel de publieke zijde van een object wordt geserialiseerd. Wil je dus private instantievariabelen ook bewaren dan zal je deze via een property beschikbaar moeten maken. Zorg er ook voor dat je klasse public:
public class Student
{
public string Naam { get; set; }
public int Leeftijd { get; set; }
public bool Uitgeschreven { get; set;}
}
Serialiseer de klasse: Met behulp van de static klasse JsonSerializer kunnen we nu eenvoudig een object omzetten naar zijn JSON-voorstelling, van het type string. Je roept gewoon de Serialize methode aan en geeft het te serialiseren object mee als argument:
var student = new Student
{ Naam = "Barry", Leeftijd = 25, Uitgeschreven = true };
string jsonString = JsonSerializer.Serialize(student);
Console.WriteLine(jsonString); //ter controle
Schrijf naar een bestand: Finaal kunnen we onze bestaande kennis van de File.WriteAllText-methode gebruiken om de JSON-voorstelling naar een bestand weg te schrijven. Merk op da thet een goede gewoonte is om het bestand een ".json"-extensie te geven.
Je zal in veel documentatie en online bronnen vaak zien dat men een andere namespace gebruikt om met JSON-bestanden te werken in C#. Tot recent was de Newtonsoft.Json namespace de geijkte manier. Deze bibliotheek is door een externe firma, Newtonsoft, ontwikkelt (merk op dat het volledig opensource is!) De .NET ontwikkelaars hebben echter veel tijd en moeite in hunSystem.Text.Jsonnamespace gestoken, waardoor er nu een ingebouwde .NET oplossing is. Hierdoor is het aangeraden om nu te werken met de Microsoft oplossing, deze kan quasi alles wat de Newtonsoft-oplossing kan en het zal niet lang meer duren voor het meer zal kunnen.
Om data uit een JSON-bestand te laden, gebruiken we de Deserialize-methode van de JsonSerializer. We veronderstellen dat de klasse onveranderd is gebleven en dat we nog steeds de nodige namespaces voorzien. De methode is generic, dus we moeten meegeven welk datatype we verwachten. Dit is logisch: de methode krijgt een string en kan niet raden bij welke klasse deze data hoort. voor hetzelfde geld zijn er meerdere klassen met de naam Student en de properties Naam, Leeftijd en Uitgeschreven:
Soms zijn er zaken in een klasse die niet direct als JSON kunnen worden geserialiseerd. Denk aan private instantievariabelen en read-only properties. Deze zaken zijn niet beschikbaar voor de buitenwereld. In dergelijke gevallen kunnen we het serialisatiegedrag aanpassen door attributen te gebruiken.
Attributen zijn kleine codeblokjes die worden toegevoegd aan onze klasse om bepaalde eigenschappen van de klasse aan te passen. Bijvoorbeeld, we kunnen een attribuut gebruiken om een property te laten overslaan bij het serialiseren. Attributen zijn herkenbaar aan de tekst tussen vierkante haken boven een klasse-element. Merk op dat attributen niéts met arrays te maken hebben. Ze zijn een C# manier om je code als het ware meta-informatie te geven die door de compiler of andere bibliotheken kan gebruikt worden.
Er zijn tal van JSON-gerelateerde attributen beschikbaar om dus het serialisatiegedrag bij te sturen. Stel dat we in voorgaande klasse een property hebben die niét mag geserialiseerd worden, dan plaatsen we het JsonIgnore attribuut boven die property:
public class Student
{
public string Naam { get; set; }
public int Leeftijd { get; set; }
[JsonIgnore]
public bool Uitgeschreven { get; set; }
}
Als we nu een Student-object zouden serialiseren zoals voorheen dan krijgen we volgende JSON:
{"Naam":"Barry","Leeftijd":25}
Ook bij het deserialiseren zou Uitgeschreven genegeerd worden, zelfs als die in het JSON-bestand zou voorkomen.
Dit attribuut laat ons toe om de naam van een property aan te passen wanneer deze wordt geserialiseerd. Dit kan handig zijn als de naam van de property niet exact overeenkomt met de naam die we in het JSON-bestand willen gebruiken:
public class Student
{
[JsonPropertyName("VolledigeNaam")]
public string Naam { get; set; }
}
Als we hier een object zouden van serialiseren zou dit volgende JSON geven:
Soms is het belangrijk dat bepaalde private informatie ook geserialiseerd wordt. Met het JsonInclude kan je dat aanduiden:
public class Student
{
public string Naam { get; set; }
[JsonInclude]
private int leeftijd=20;
}
Beeld je in dat we nog een methode hebben die de leeftijd geregeld zal veranderen, dan nog zal de juiste waarde van leeftijd bewaard worden (en dus niet op 20 blijven). De JSON zal er als volgt uit zien:
{"Naam":"Barry","leeftijd":20}
Er zijn nog tal van attributen om het serialisatiegedrag te verbeteren. Deze zijn vaak echter een stuk complexer en worden daarom niet in dit basis handboek behandeld. Opgelet: controleer steeds goed of je de juiste attributen hebt opgezocht. Je zal op het internet zowel Newtonsoft.Json als System.Text.Json attributen vinden, en beide zijn vaak nét niet hetzelfde.
Als afsluiter toon ik graag een verborgen feature van VS die mij al veel tijd heeft bespaard. Stel dat je een stuk JSON hebt van elders1 dat je in je code wilt kunnen deserialiseren naar een object. Het JSON-bestand is echter vrij complex en gebruikt bijvoorbeeld allerlei geneste objecten (door associatie) en arrays, etc. Kortom, hier manueel de juiste klasse(n) voor schrijven voor je verder kan is veel werk. Zoals je al vermoedde kan je dit heel eenvoudig oplossen.
Stap 1: kopieer de JSON-tekst naar het klembord.
Stap 2: voeg een nieuw, leeg klasse-bestand toe aan je project. verwijder alles in dit bestand behalve de namespace-definitie en bijhorende accolades.
Stap 3: en nu de magie! Kies in het menu bovenaan voor Edit, dan "Paste Special" en finaal voor "Paste JSON as Classes". BOEM!
Visual Studio heeft nu voor je de nodige klassen geschreven die exact overeen komen met de JSON die jij wilt kunnen deserialiseren. Handig toch?!
1
Een typische use-case is wanneer je met een online webapi praat die met JSON antwoordt.
Opgelet, de volgende kennisclip(s) zijn een experiment waarbij ik een combinatie van A.I. en eigen input heb gebruikt om ze te maken. Feedback zeer welkom!
Je hebt het gehaald! Volgens m'n statistieken zal je nu in 1 van volgende 2 staten zijn:
Het scheelt niet veel of je droomt in klassen en objecten. Overal waar je kijkt zie je toepassingen van polymorfisme, interfaces en overerving. Je begrijpt nu waarom zoveel mensen graag software ontwikkelen. Je hebt de smaak te pakken en er ligt een ongelooflijk scala aan mogelijkheden voor je klaar. Bekijk zeker enkele aanbevelingen op de volgende pagina die je na dit boek kan ontdekken. Ook in de appendix zal je nog enkele interessante, gevorderde concepten kunnen ontdekken.
Je pinkt een traantje weg. Je had zo gehoopt nu alles van OOP te kunnen, maar het is alleen maar verwarrender geworden. Dat is jammer, maar niets aan te doen. Bij sommigen komt de klik niet altijd direct. Hopelijk heb je toch iets geleerd uit dit boek en begrijp je waarom zoveel mensen, zoals ik, zo enthousiast over OOP zijn. Blijven oefenen is de boodschap!
En moest je dit boek nu ongelooflijk nuttig, slecht of briljant vinden: iedere review helpt. Je doet me er een ongelooflijke dienst mee als je een review plaatst op de website waar je dit boek kocht!
Ik wens je alvast veel succes met de verdere ontwikkeling van je programmeer-expertise en denk er aan: gebruik nooit goto!
Helaas niet. Maar je hebt wel een erg goede basis gelegd. Vanaf dit punt kan je tal van richtingen uitgaan, afhankelijk van je interesses:
Geavanceerde C# concepten: je zou je verder kunnen verdiepen in "de taal C#". Denk maar aan leren werken met async en events. Maar ook het wonderlijke Linq is iets dat je in bijna alle .NET geledingen zal kunnen gebruiken.
Desktop-applicaties: Totnogtoe hebben we enkel oersaaie Console-applicaties gemaakt. Uiteraard kan je ook heel eenvoudig -met de kennis die je nu hebt- zogenaamde bureaublad-applicaties maken. Neem zeker eens een kijkje wat WPF en UWP je te bieden heeft. Je zal je even moeten inwerken in eventgebaseerd-programmeren en XAML en vanaf dan ben je vlot vertrokken!
Mobiele applicaties: Zogenaamde native Android of iPhone applicaties ontwikkelen gaat niet met C#. Merk wel op dat dankzij je nieuwe C# kennis je vlot de native programmeertalen van Android (Java) en iOS (Swift) kan leren. Binnen de .NET-familie bestaat er echter wel het nieuwe .NET MAUI-framework. Dit krachtige framework (de opvolger van Xamarin) laat je toe om in C# crossplatform-apps te ontwikkelen. Je zal met 1 codebase kunnen compileren naar zowel Windows, Android, iPhone, enz. Bekijk zeker ook eens de Comet toolkit om erg modern-ogende apps te maken met .NET MAUI.
Web-ontwikkeling: Ook .NET heeft een zogenaamde back-end stack waar aardig wat grote bedrijven op draaien. Deze technologie-stack bevat tal van belangrijke technologieën zoals APS.NET, Entity Framework. En als je genoeg hebt van altijd maar in Javascript te werken, dan moet je zeker eens een kijkje nemen in de jongste .NET-telg Blazor, die je toelaat om C# te schrijven in je HTML!
Game development: Wil je eerder de Sid Meiers, John Romeros en Gabe Newells van deze wereld achterna gaan en games beginnen ontwikkelen? Steeds meer games - zeker in de indie-wereld - worden nu ontwikkeld in Unity, een op C# gebaseerde game-engine. Maar bekijk zeker ook eens Monogame, een C# bibliotheek waar onder andere Stardew Valley in is ontwikkeld. Monogame is een zogenaamde crossplatform bibliotheek en kan je games compileren naar Mac, Windows, Linux, Android, Nintendo Switch, Playstation 4, XboxOne, enz. Godot is een andere, laagdrempelige, manier om in C# games te ontwikkelen.
Azure en de cloud: en wil je echt ontdekken dat je nog niet veel kent van .NET, dan moet je eens kijken naar wat er allemaal onder de Azure-tak van Microsoft te vinden is. Azure is de verzamelnaam voor alle cloud-gebaseerde technologieën & services van Microsoft, waarin .NET - en dus ook C# - een belangrijk onderdeel is.
Gevorderde programmeerconcepten: Design Patterns, Dependency Injection, SOLID programming, enz. zijn allemaal taal-agnostische programmeerconcepten. Wat wil zeggen dat je ze kan toepassen op je programmeerproblemen, onafhankelijk van de programmeertaal die je hanteert. Je zal namelijk ontdekken dat bepaalde problemen vaak herleid kunnen worden tot een specifieke groep van problemen. Voor deze problemen hebben slimmere mensen dan ik "oplossings-recepten" (design patterns) uitgedokterd.
Bepaalde code zal je vaak opnieuw schrijven. Er zitten in VS tal van shortcuts om deze typische lijnen code sneller te schrijven. Schrijf een van volgende stukken code en druk dan 2x op de [tab]-toets:
In explorer (linkerzijde) zie je je project (klik als je geen explorer balk ziet):
Open de Program.cs file:
OPGELET: we moeten nog 1 ding doen voor we kunnen beginnen.
Klik met je muis op de eerste lijn code (// See https://aka.ms/new-console-template for more information) zodat je cursor er staat. Er zou nu aan de linkerzijde een geel lampje moeten verschijnen:
Klik op gele lampje en kies Convert to program.main style program:
Je kan delen van je code in handige inklapbare secties zetten door deze als regions aan te duiden, als volgt:
#region My Epic code
Console.WriteLine("I am the greatest!");
Console.WriteLine("Echt waar!");
#endregion
Je zal vanaf dan in Visual Studio rechts van de start van de region een minnetje zien waar je op kunt klikken om de hele region tot aan #endregion in te klappen. De code zal nog steeds gecompileerd worden, maar je bladspiegel is weer wat ordelijker geworden.
String interpolatie met het $-teken is een nieuwe C# aanwinst. Je zal echter geregeld documentatie en online code tegenkomen die nog met String.Format werkt (ook zijn er nog zaken waar het te verkiezen is om String.Format te gebruiken i.p.v. 1 van vorige manieren). Om die reden bespreken we dit nog in dit boek.
String.Format is een ingebouwde methode die string-interpolatie toelaat op een iets minder intuïtieve manier, als volgt:
string result = String.Format("Ik ben {0} en ik ben {1} jaar.", naam, leeftijd);
Het getal tussen de accolades geeft aan welke parameter op die plek moet komen. 0 betekent de eerste, 1 betekent de tweede, enzovoort.
De eerste parameter is naam, de tweede is leeftijd.
Volgende code zal een ander resultaat geven:
string result = String.Format("Ik ben {1} en ben {1} jaar.", naam, leeftijd);
Namelijk: Ik ben 13 en ik ben 13 jaar oud.
Je kan deze vorm van formateren ook toepassen in Console.WriteLine zonder dat je expliciet String.Format hiervoor moet aanroepen:
Console.WriteLine("Gratis formateren. {0} maal hoera voor .NET!", 3);
Parameters kun je op twee manieren aan een methode doorgeven: by value (via de waarde) of by reference (via het geheugenadres). Welke manier gebruikt wordt, hangt af van het datatype. Primitieve datatypes zoals int en double worden by value doorgegeven. Arrays worden by reference doorgegeven.
Je kunt primitieve datatypes ook by reference doorgeven. Dit geeft de methode directe toegang tot de variabele, in plaats van een kopie. Dit kan handig zijn, maar kan ook ongewenste bugs veroorzaken. Wees dus voorzichtig.
Je plaatst het ref keyword in de methode signatuur voor de formele parameter dat by reference moet meegegeven worden. Vanaf dan heeft de methode toegang tot de originele parameter en dus niet tot de kopie. Je dient ook expliciet het keyword voor de actuele parameter bij de aanroep van de methode te plaatsen:
static void VerhoogWaarde(ref int getal)
{
getal++;
}
static void Main(string[] args)
{
int eerste = 1;
Console.WriteLine(eerste); //er verschijnt 1 op het scherm
VerhoogWaarde(ref eerste); //let op het ref keyword!
Console.WriteLine(eerste); //er verschijnt 2 op het scherm
}
Door het out keyword te gebruiken geven we expliciet aan dat we beseffen dat de parameter in kwestie pas binnen de methode een waarde zal toegekend krijgen. Wat ik hier toon:
static void GeefWaarde(out int getal)
{
getal = 5;
}
static void Main(string[] args)
{
int eerste;
GeefWaarde(out eerste);
Console.WriteLine(eerste); //er verschijnt 5 op het scherm
}
Vaak wil je de invoer van de gebruiker verwerken/omzetten naar een getal. Denk maar aan volgende applicatie:
Console.WriteLine("Geef je leeftijd");
string invoer = Console.ReadLine();
int leeftijd = int.Parse(invoer);
leeftijd += 10;
Console.WriteLine($"Over 10 jaar ben je {leeftijd} jaar oud");
Deze applicatie zal falen indien de gebruiker iets invoert dat niet kan geconverteerd worden naar een int. We lossen dit op met behulp van TryParse.
De primitieve datatypes int, double, float enz. hebben allemaal een TryParse methode. Je kan deze gebruiken om de invoer van een gebruiker te proberen om te zetten, als deze niet lukt dan kan je dit ook weten zonder dat je programma crasht door een exception op te werpen.
De werking van TryParse is als volgt:
bool gelukt = int.TryParse(invoer,out int leeftijd);
De methode TryParse probeert de string in de eerste parameter (invoer) om te zetten naar een int. Als dit lukt, wordt het resultaat opgeslagen in de variabele int leeftijd. Let op dat we out voor de parameter moeten zetten, zoals eerder uitgelegd.
Het return resultaat van de methode is bool: indien de conversie gelukt is dan zal deze true teruggeven, anders false.
We kunnen nu onze applicatie herschrijven en minder foutgevoelig maken voor slechte invoer van de gebruiker:
Console.WriteLine("Geef je leeftijd");
string invoer = Console.ReadLine();
bool gelukt = int.TryParse(invoer,out int leeftijd);
if (gelukt)
{
leeftijd += 10;
Console.WriteLine($"Over 10 jaar ben je {leeftijd} jaar oud");
}
else
{
Console.WriteLine("Geen geldige invoer gegeven!");
}
Daar TryParse een bool teruggeeft kunnen we deze ook gebruiken in loops als logische expressie. Volgende applicatie zal aan de gebruiker een komma getal vragen en pas verder gaan indien de gebruiker een geldige invoer heeft gegeven:
double temperatuur;
string invoer = "";
do
{
Console.WriteLine("Geef temperatuur");
invoer = Console.ReadLine();
} while (! double.TryParse(invoer, out temperatuur));
//enkel verdergaan van zodra temperatuur een geldige waarde heeft gekregen
Let er op dat de scope hier van belang is: invoer en temperatuur moet gekend zijn buiten de loop waar technisch gezien ook de TryParse zal gebeuren.
internal class Kassa
{
public int Totaal {get;set;}
public int Bouwjaar {get;set;}
}
Je maakt even later twee kassa's aan met de nodige informatie:
Kassa benedenKassa = new Kassa(){Totaal = 50, Bouwjaar = 1981};
Kassa bovenKassa = new Kassa(){Totaal = 40, Bouwjaar = 2000};
Even later wordt besloten dat beide kassa's moeten samengevoegd worden tot een gloednieuwe kassa voor beide verdiepingen samen. Bedoeling is dat het totale geld in beide kassa's opgeteld in de nieuwe kassa moet gezet worden. Het bouwjaar van de nieuwe kassa moet het bouwjaar van de oudste van de 2 originele kassa's zijn.
Je zou willen schrijven:
Kassa nieuw = benedenKassa + bovenKassa;
Uiteraard heeft C# geen flauw benul hoe de + operator moet toegepast worden op objecten van klassen die je zelf geschreven hebt.
Je kan in een klasse bestaande operators (+,-,*, enz.) overloaden. Dit betekent dat je aan C# vertelt hoe een operator moet werken voor objecten van die klasse.
Stel dat je de + wilt overloaden in je klasse dan voeg je volgende methode toe:
internal class Kassa
{
public int Totaal {get;set;}
public int Bouwjaar {get;set;}
public static Kassa operator+ (Kassa a, Kassa b)
{
//Zie verder
}
}
Laten we deze syntax even bekijken:
Operator overloading methoden zijn altijd static.
Het returntype is idealiter het type van de klasse zelf (logisch: twee kassa's optellen geeft een nieuwe kassa).
operator+ geeft aan welke operator je wenst te overloaden. Zie verderop met een link naar alle operators die je kan overloaden.
Als je een operator hebt die twee operanden gebruikt (zoals de +), dan heeft de methode ook twee parameters nodig van hetzelfde type als de klasse. Dit zijn de twee elementen (operanden) die je wilt optellen met de operator.
Bekijk zeker eens de officiële documentatie1 om te zien welke operators je allemaal kan overloaden. Tip: het zijn er veel!
Vervolgens moeten we nu beschrijven hoe de operator moet werken. Finaal zal de methode een nieuw object moeten teruggeven waarin het resultaat van de operatie zit.
In het voorbeeld dat we maken, willen we dus het volgende:
public static Kassa operator+ (Kassa a, Kassa b)
{
Kassa resultaat = new Kassa()
{
Totaal = a.Totaal+b.Totaal,
Bouwjaar = a.Bouwjaar
};
if(a.Bouwjaar < b.Bouwjaar)
{
resultaat.Bouwjaar = b.Bouwjaar;
}
return resultaat;
}
Zoals je ziet maken we een nieuw object resultaat waarin we de som van de twee meegegeven kassa's hun totalen plaatsen, alsook het bouwjaar van de oudste van de 2 kassa's.
Wanneer je methoden, constructors of properties schrijft waar exact 1 expressie (1 lijn code die een resultaat teruggeeft) nodig is dan kan je gebruik maken van de expression bodied member syntax (EBM).
Deze is van de vorm:
member => expression
Dankzij EBM kan je veel kortere code schrijven.
Ik toon telkens een voorbeeld hoe deze origineel is en hoe deze naar EBM syntax kan omgezet worden.
Sinds C# 14 is er een nieuw keyword: field.
Dit keyword geeft je toegang tot de onderliggende instantievariabele (backing field) van een property, zelfs als je deze niet expliciet hebt aangemaakt bovenaan je klasse.
Dit is vooral handig wanneer je validatie wilt toevoegen aan een property, maar niet de volledige syntax van een full property wilt schrijven waar je manueel de private instantievariabele én de property moet typen.
Stel dat je een property hebt waarbij je wilt controleren dat de waarde niet negatief is.
Vroeger (Full property):
Je moest zowel de private instantievariabele (leeftijd) aanmaken als de publieke property.
private int leeftijd;
public int Leeftijd
{
get { return leeftijd; }
set
{
if (value < 0) throw new ArgumentException("Leeftijd mag niet negatief zijn");
leeftijd = value;
}
}
Met field:
Je hebt geen private instantievariabele meer nodig in je code. Via field spreekt de property rechtstreeks de, door de compiler gegenereerde, achterliggende variabele aan.
public int Leeftijd
{
get;
set
{
if (value < 0) throw new ArgumentException("Leeftijd mag niet negatief zijn");
field = value;
}
}
Merk op hoe je field gebruikt om de waarde toe te wijzen aan de interne staat van het object. De get kan gewoon get; blijven.
Auto-properties (bv. public int Leeftijd { get; set; }) zijn eigenlijk een afkorting waarbij de compiler voor jou een onzichtbare instantievariabele aanmaakt en de get en set implementeert.
Met het field keyword kan je nu het beste van twee werelden combineren:
Zoals auto-properties: Je hoeft geen aparte private variabele aan te maken.
Zoals full properties: Je kan eigen logica (validatie, logging, etc.) toevoegen aan de get of set.
In het voorbeeld hierboven zie je dat we de get nog steeds schrijven als een auto-property (get;), terwijl we de set zelf implementeren en gebruik maken van field.
Vaak schrijf je methoden die hetzelfde doen, maar waarvan enkel het type van de parameters en/of het returntype verschilt. Stel dat je een methode hebt die de elementen in een array onder elkaar toont. Je wil dit werkende hebben voor arays van het type int, string, enz. Zonder generics moeten we dan per type een methode moeten schrijven:
public static void ToonArray(int[] array)
{
foreach (var i in array)
{
Console.WriteLine(i);
}
}
public static void ToonArray(string[] array)
{
foreach (var i in array)
{
Console.WriteLine(i);
}
}
Dankzij generics kunnen we nu het deel dat generiek moet zijn aanduiden (in dit geval met T) en onze methode eenmalig definiëren. We gebruiken hierbij de < > aanduiding die aan de compiler vertelt "dit stuk is een generiek type":
public static void ToonArray<T>(T[] array)
{
foreach (T item in array)
{
Console.WriteLine(item);
}
}
Vanaf nu kun je eender welk soort array aan deze ene methode geven en de array zal naar het scherm afgedrukt worden:
We kunnen niet alleen generieke methoden schrijven, maar ook eigen klassen én interfaces definiëren die generiek zijn. In het volgende codevoorbeeld is te zien hoe een eigen generic class in C# gedefinieerd en gebruikt kan worden. Merk het gebruik van de aanduiding T, deze geeft weer aan dat hier een type (zoals int, double, Student, enz.) zal worden ingevuld tijdens het compileren.
De typeparameter <T> wordt pas voor de specifieke instantie van de generieke klasse of type ingevuld bij het compileren. Hierdoor kan de compiler per instantie controleren of alle parameters en variabelen die in samenhang met het generieke type gebruikt worden wel kloppen.
De afspraak is om .NET een T te gebruiken indien het type nog dient bepaald te worden. Dit is niet verplicht maar wordt aanbevolen als je maar 1 generiek type nodig hebt.
We wensen nu een klasse te maken die de locatie in X,Y,Z coördinaten kan bewaren. We willen echter zowel float, double als int gebruiken om deze X,Y,Z coördinaten in bij te houden:
internal class Locatie<T>
{
public T X {get;set;}
public T Y {get;set;}
public T Z {get;set;}
}
We kunnen deze klasse nu als volgt gebruiken:
var plaats = new Locatie<int>();
plaats.X = 34;
plaats.Y = 22;
plaats.Z = 56;
var plaats2 = new Locatie<double>();
plaats2.X = 34.5;
plaats2.Y = 22.2;
plaats2.Z = 56.7;
var plaats3 = new Locatie<string>();
plaats3.X = "naast de kerk";
plaats3.Y = "links van de bakker";
plaats3.Z = "onder het hotel";
Merk op dat het keyword var hier handig is: het verkort de ellenlange stukken code waarin we toch maar gewoon het datatype herhalen dat ook al rechts van de toekenningsoperator staat.
Voorgaand voorbeeld is natuurlijk maar de tip van de ijsberg. We kunnen bijvoorbeeld volgende klasse maken die we kunnen gebruiken met eender welk type om de meetwaarde van een meting in op te slaan. Merk op hoe we op verschillende plaatsen in de klasse het element T gebruiken als een datatype:
internal class Meting<T>
{
public T Waarde {get;set;}
public Meting(T waardein)
{
Waarde = waardein;
}
}
Een voorbeeldgebruik van dit nieuwe type kan zijn:
var m1 = new Meting<int>(44);
Console.WriteLine(m1.Waarde);
var m2 = new Meting<string>("slechte meting");
Console.WriteLine(m2.Waarde);
Zoals reeds eerder vermeld is de T aanduiding enkel maar een afspraak. Je kan echter zoveel T-parameters meegeven als je wenst. Stel dat je bijvoorbeeld een klasse wenst te maken waarbij 2 verschillende types kunnen gebruikt worden. De klassedefinitie zou er dan als volgt uit zien:
internal class DataBewaarder<Type1, Type2>
{
public Type1 Waarde1 {get;set;}
public Type2 Waarde2 {get;set;}
public DataBewaarder(Type1 w1, Type2 w2)
{
Waarde1 = w1;
Waarde2 = w2;
}
}
Een object aanmaken zal nu als volgt gaan:
DataBewaarder<int, string> d1 = new DataBewaarder<int, string>(4, "Ok");
We willen soms voorkomen dat bepaalde types wel of niet gebruikt kunnen worden in je zelfgemaakte generieke klasse.
Stel bijvoorbeeld dat je een klasse schrijft waarbij je de CompareTo() methode wenst te gebruiken. Dit gaat enkel indien het type in kwestie de IComparable interface implementeert. We kunnen als constraint (beperking) dan opgeven dat de volgende klasse enkel kan gebruikt worden door klassen die ook effectief die interface implementeren (en dus de CompareTo()-methoden hebben). We doen dit in de klasse-definitie met het nieuwe where keyword. We zeggen dus letterlijk: "waar T overerft van IComparable":
internal class Wijziging<T> where T : IComparable
{
public T VorigeWaarde {get;set;}
public T Huidigewaarde {get;set;}
public Wijziging(T vorig, T huidig)
{
VorigeWaarde = vorig;
Huidigewaarde = huidig;
}
public bool IsGestegen()
{
return Huidigewaarde.CompareTo(VorigeWaarde) > 0;
}
}
Volgende gebruik van deze klasse zou dan True op het scherm tonen:
Wijziging<double> w = new Wijziging<double>(3.4, 3.65);
Console.WriteLine(w.IsGestegen());
Verschillende zaken kunnen als constraint optreden. Naast de verplichting dat een bepaalde interface moet worden geïmplementeerd kunnen ook volgende constraints gelden (bekijk de online documentatie voor meer informatie hierover):
Soms wil je enkele variabelen die bij elkaar horen, samenvoegen in één geheel. Stel dat je de positie van een speler in een spel wilt bijhouden. Zonder struct zou je twee losse variabelen moeten maken:
int spelerX = 10;
int spelerY = 20;
Handiger is om deze te groeperen. Een struct is ideaal voor dit soort kleine verzamelingen van data. Je maakt hiervoor een eigen type aan met de variabelen die je wilt groeperen (we noemen dit fields):
struct Positie
{
public int X;
public int Y;
}
Je hebt nu je eigen type gemaakt en kunt dit als één variabele gebruiken:
Een struct (structure) lijkt qua syntax erg op een klasse, maar werkt intern anders. Het belangrijkste verschil is dat een struct een Value Type is, terwijl een klasse een Reference Type is.
Value Type: Wanneer je een struct toewijst aan een nieuwe variabele, wordt de volledige data gekopieerd. Bij een klasse wordt enkel de referentie (het adres) gekopieerd.
Stack Allocation: Structs leven meestal op de Stack (tenzij ze onderdeel zijn van een klasse), wat sneller geheugenbeheer toelaat dan de Heap (waar klassen leven).
Geen overerving: Een struct kan niet erven van een andere struct of klasse (wel interfaces implementeren).
Sinds C# 9.0 is het mogelijk om record-types te maken. Een record is (standaard) een Reference Type, net als een klasse, maar is ontworpen met onveranderlijkheid (immutability) en data-equality in het achterhoofd.
Class: Standaard keuze voor de meeste objecten met gedrag en data.
Record: Gebruik voor data-containers waarbij onveranderlijkheid gewenst is (API responses, config, domein objecten).
Struct: Gebruik enkel voor zeer kleine datastructuren (< 16 bytes) die extreem veel worden aangemaakt en waar performantie kritiek is (bv. game development, high-performance computing).
Je bent eindelijk klaar. Je hebt de ultieme applicatie gemaakt en bent zo fier als een gieter. Uiteraard wil je je creatie met de wereld delen. Maar hoe?! Hebben je klanten ook Visual Studio nodig? Moeten zij ook de .NET runtime hebben? En zo ja, de welke? Veel vragen, die je in principe zou moeten kunnen beantwoorden (tip, de antwoorden in volgorde zijn: "neen", "ja", "hangt af van de runtimeversie waar je naar compileert"). Maar het gelukkig ook veel eenvoudig.
Visual Studio heeft een ingebouwde manier om snel een installer voor je applicatie te maken. Deze installer zal er zelf voor zorgen dat de nodige zaken correct gedownload worden moest jouw applicatie dat nodig hebben om uitgevoerd te kunnen worden. Zo zal de installer zelf kijken of de vereiste .NET runtime op het doelsysteem staat, en indien niet zal de juiste versie eerst geïnstalleerd worden. Ook zal de installer ervoor zorgen dat de gebruiker je applicatie op een mooie manier kan verwijderen en dat je applicatie vanuit het startmenu kan gestart worden.
In programmeren zijn we streng in het verbeteren van code. Volgende afspraken worden gehanteerd bij de AP Hogeschool bij het verbeteren van vaardigheidsproeven.
Er zal steeds een puntenverdeling staan per sectie waar je punten kan scoren op het maken van de gevraagde functionaliteit. Het maximum van de score behaal je enkel voor deze sectie als je de vereisten van deze sectie perfect hebt geïmplementeerd én met meest logische oplossingsstrategie (vb. geen loops gebruikt, maar alles hardcoded) .
MAAR indien je volgende zaken in je code hebt staan dan zullen er punten van totaalscore afgetrokken worden.
Dit is hopelijk duidelijk? Wanneer we op "compile & run" klikken willen we je code in actie zien. Geen werkend project kost je.
Tip: de deadline van het examen nadert? Zet de stoute code in commentaar.
Je moet voor een opgave 2 of meerdere klassen maken? Plaats IEDERE KLASSE IN EEN APART bestand.
Moet je dus Student, Leraar en School klasse maken? Dan ontdekken we hopelijk in je project minstens 3 bestanden genaamd "Student.cs", "Leraar.cs" en "School.cs".
Oh wee je gebeente als je één groot bestand genaamd "Klassen.cs" (o.i.d.) in je project hebt staan.
double loop1 = Casino(start, 10);
Console.WriteLine($"Als je 10 keer roulette speelt zou je eindkapitaal {loop1} zijn, dat is een verschil van {loop1-start}");
double loop2 = Casino(start, 100);
Console.WriteLine($"Als je 100 keer roulette speelt zou je eindkapitaal {loop2} zijn, dat is een verschil van {loop2 - start}");
double loop3 = Casino(start, 10000);
Console.WriteLine($"Als je 10000 keer roulette speelt zou je eindkapitaal {loop3} zijn, dat is een verschil van {loop3 - start}");
double loop4 = Casino(start, 1000000);
Console.WriteLine($"Als je 1000000 keer roulette speelt zou je eindkapitaal {loop4} zijn, dat is een verschil van {loop4 - start}");
Kan herschreven worden m.b.v. loops en een array:
int[] prijzen ={10, 100, 10000, 1000000};
for(int i=0; i<prijzen.Length; i++)
{
double winst = Casino(start, prijzen[i]);
Console.WriteLine($"Als je 10 keer roulette speelt zou je eindkapitaal {winst} zijn, dat is een verschil van {winst-start}");
}
We hebben er geen probleem mee dat je al je methoden en variabelen Engelse of Nederlandse namen geeft. Maar wees wel consistent: ga ofwel full Dutch oftewel full English.
Ter zijde: onze DuoLingo skillz zijn beperkt. Gelieve dus géén andere talen te gebruiken.
Zonder in detail te gaan, weet dat je bij arrays dankzij Linq een aantal handige methoden hebt die je niet mag gebruiken. Dit jaar moet je al je bewerkingen op arrays manueel m.b.v. loops doen.
Iedere methode definieer je (t.e.m. hoofdstuk 8) op hetzelfde niveau in het "Program.cs" bestand. Je mag dus nooit methoden in methoden schrijven. (opgelet: je mag uiteraard wel methoden in een andere methode aanroepen.)



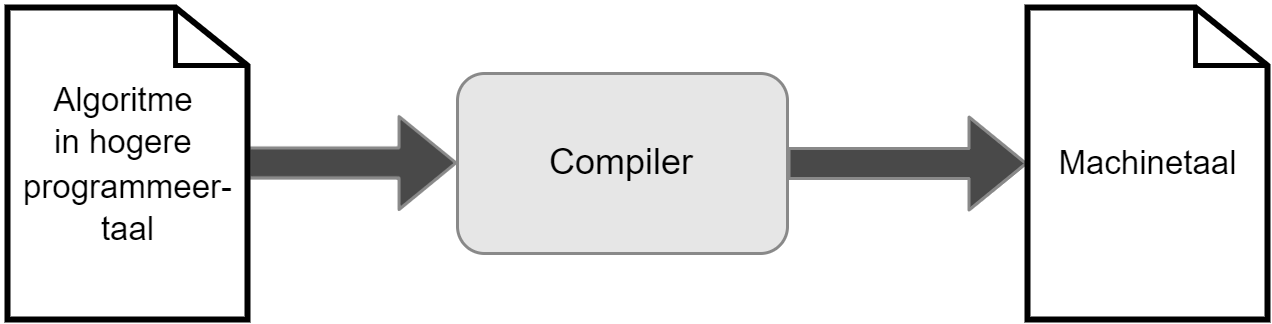
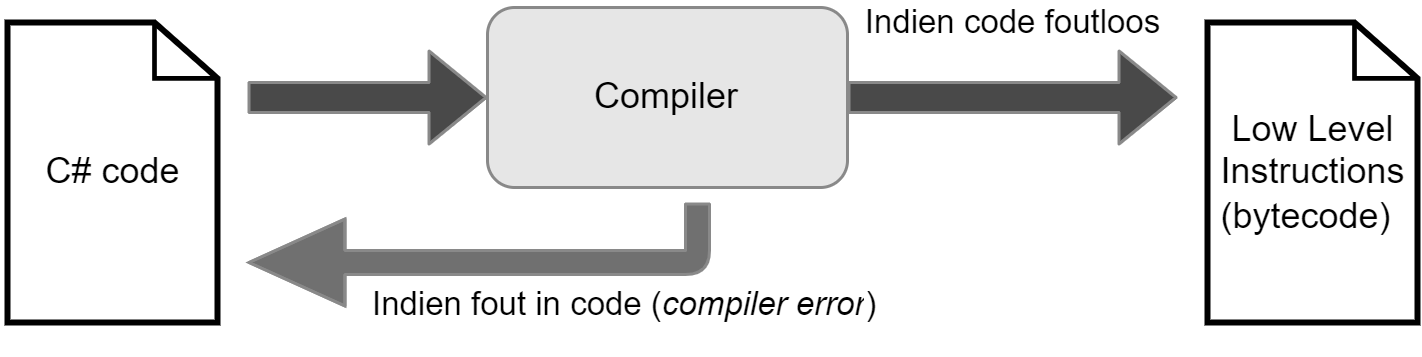

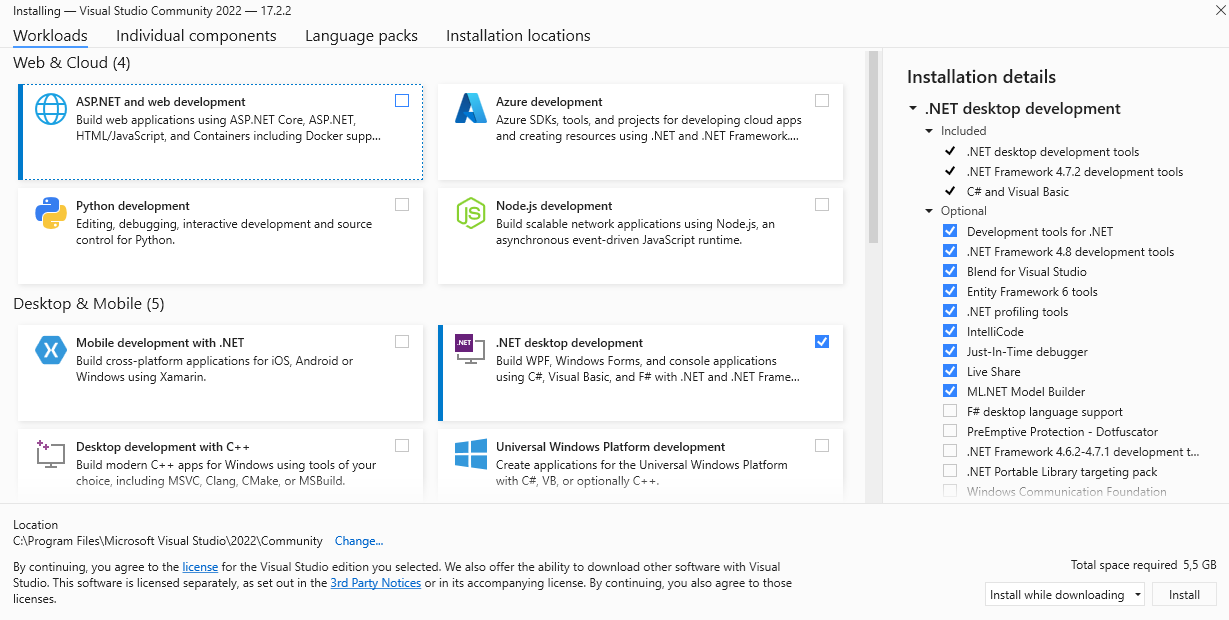

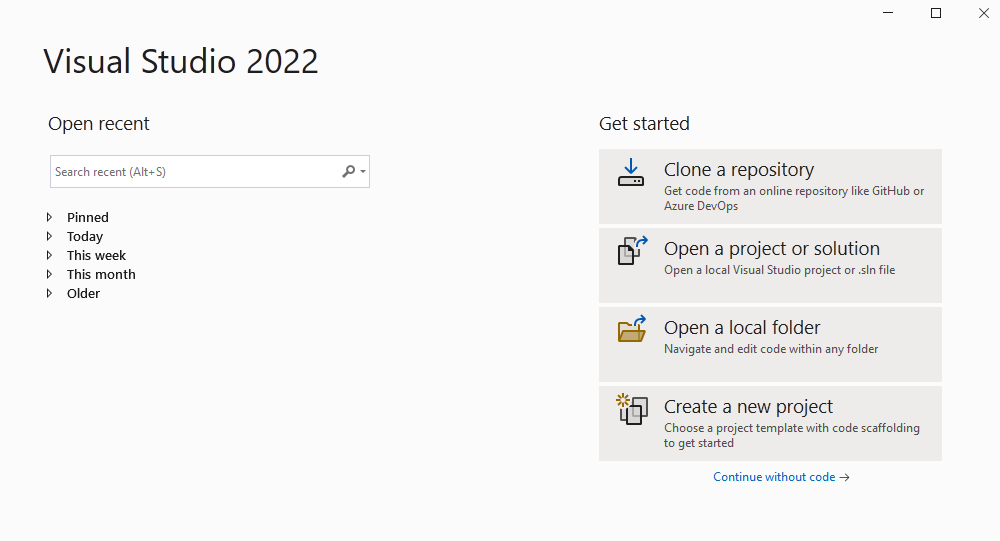
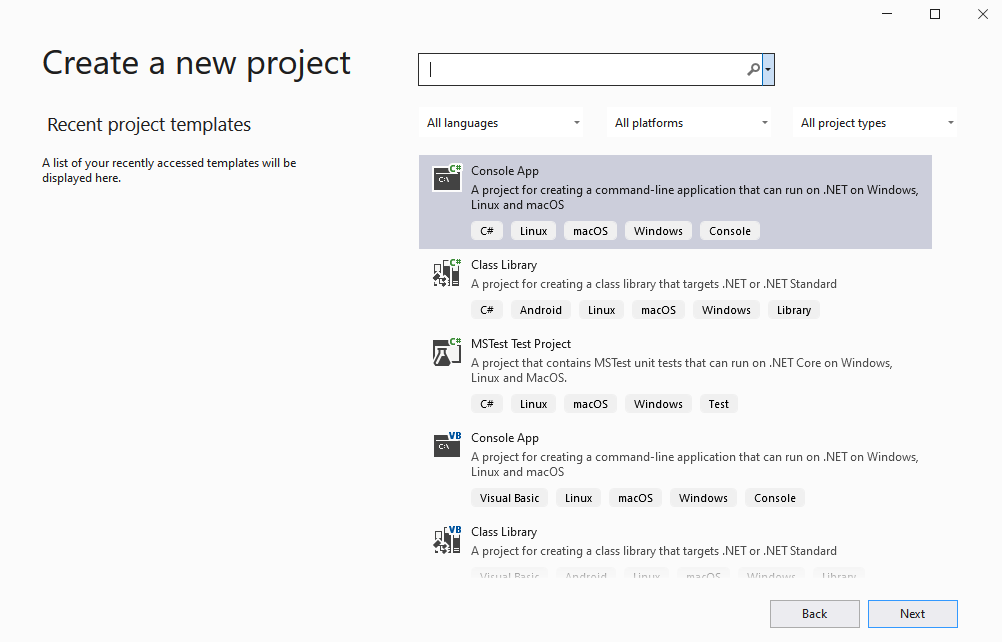
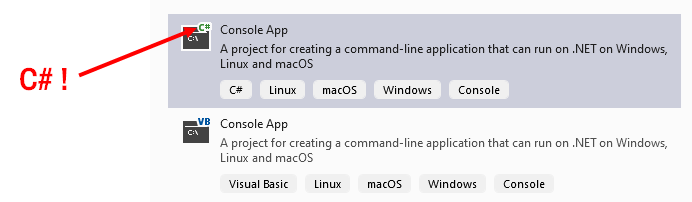
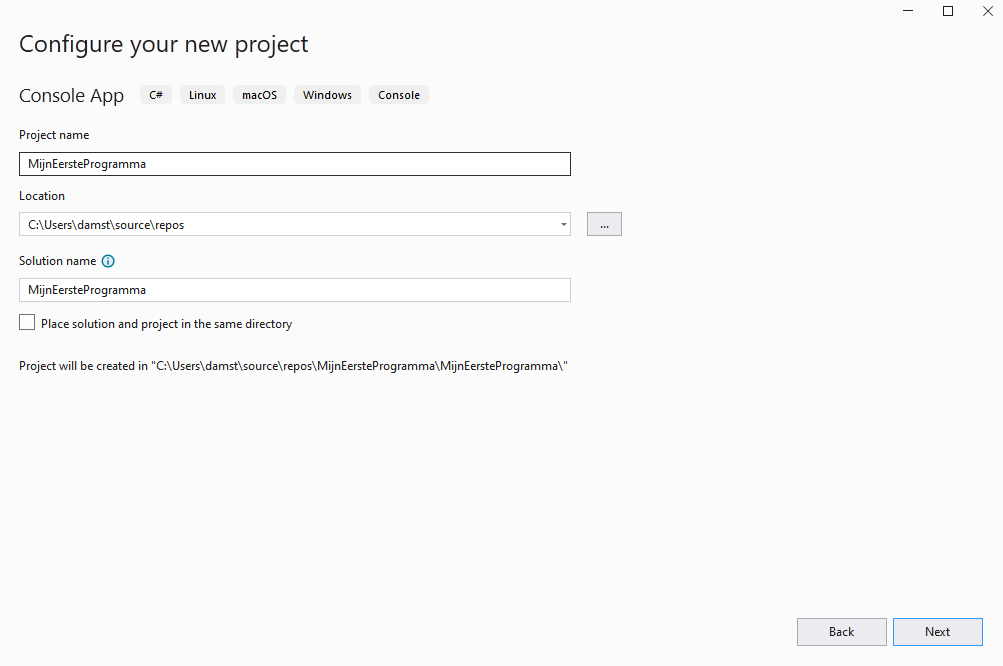
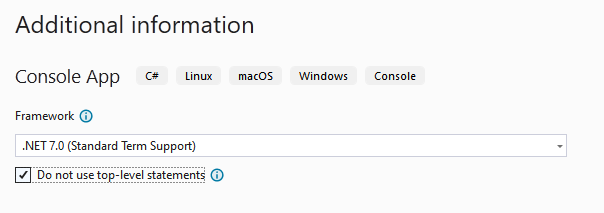
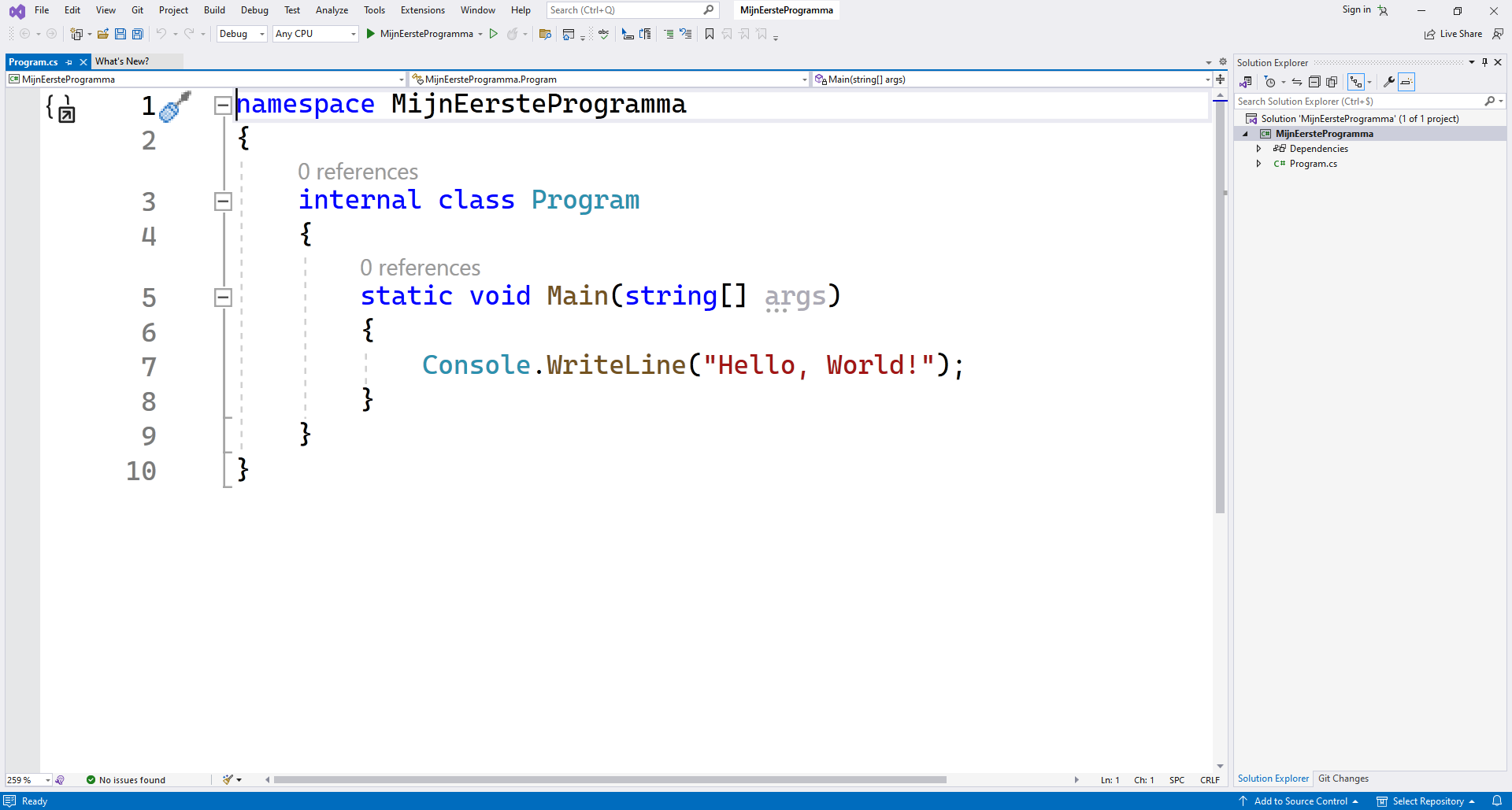
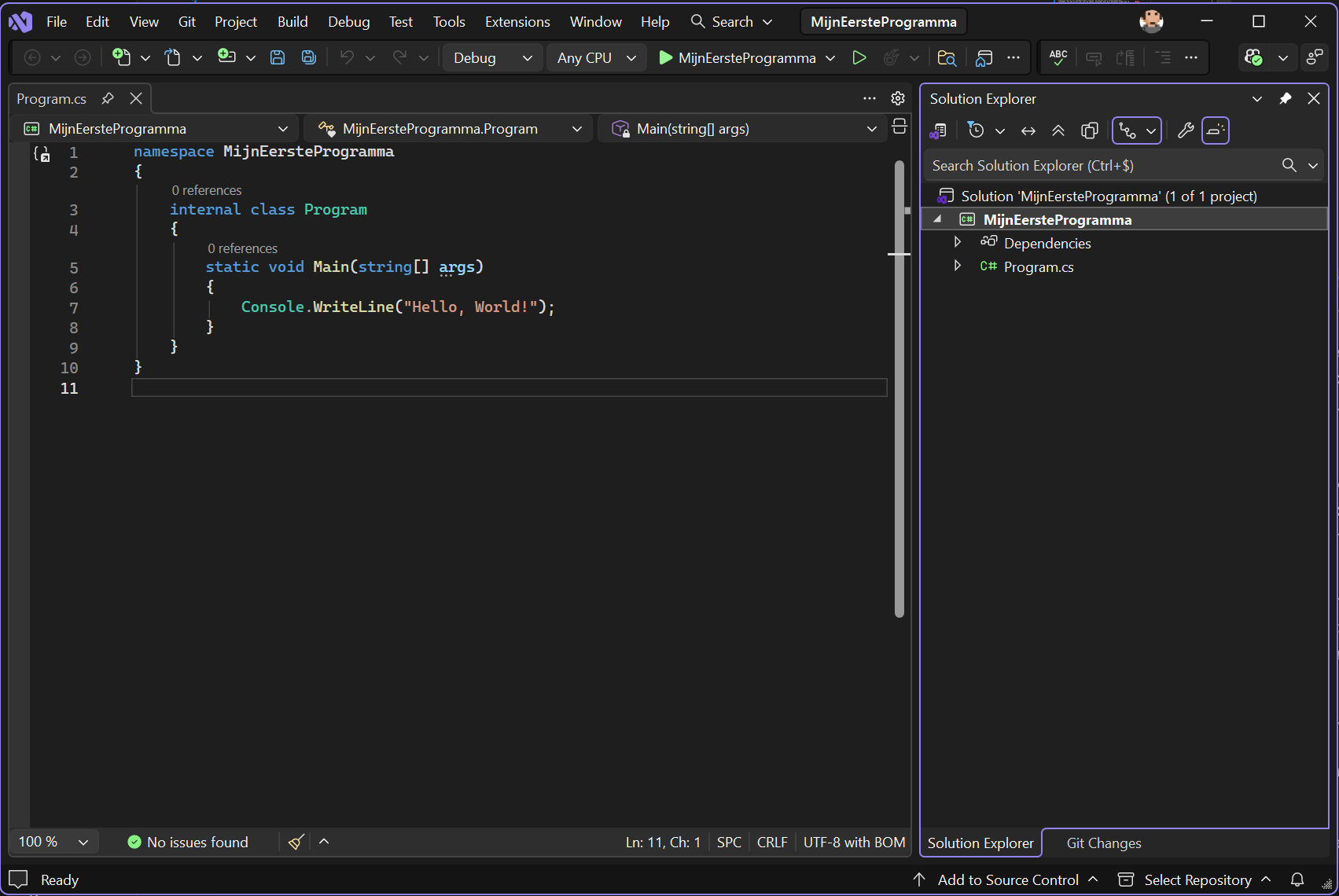
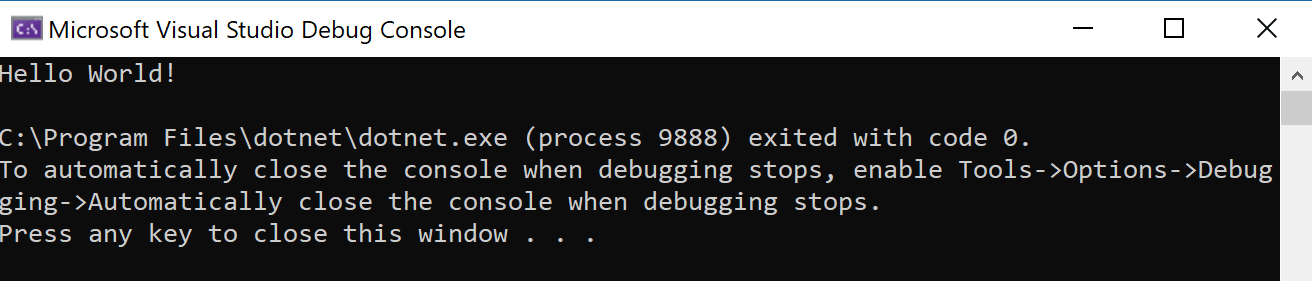

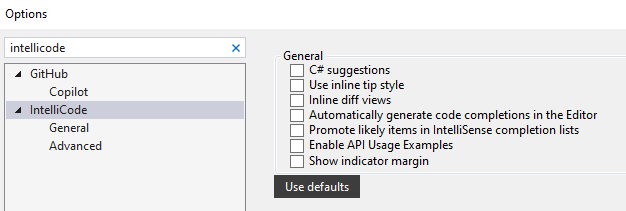
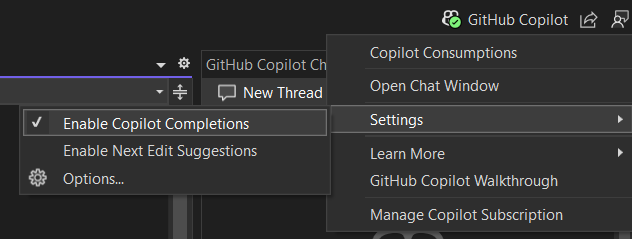

Jawadde...Wat was dit allemaal?! We hebben al aardig wat vreemde code zien passeren en het is niet meer dan normaal dat je nu denkt "dit ga ik nooit kunnen". Wees echter niet bevreesd: je zal sneller dan je denkt bovenstaande code als 'kinderspel' gaan bekijken. Een tip nodig? Test en experimenteer met wat je al kunt!
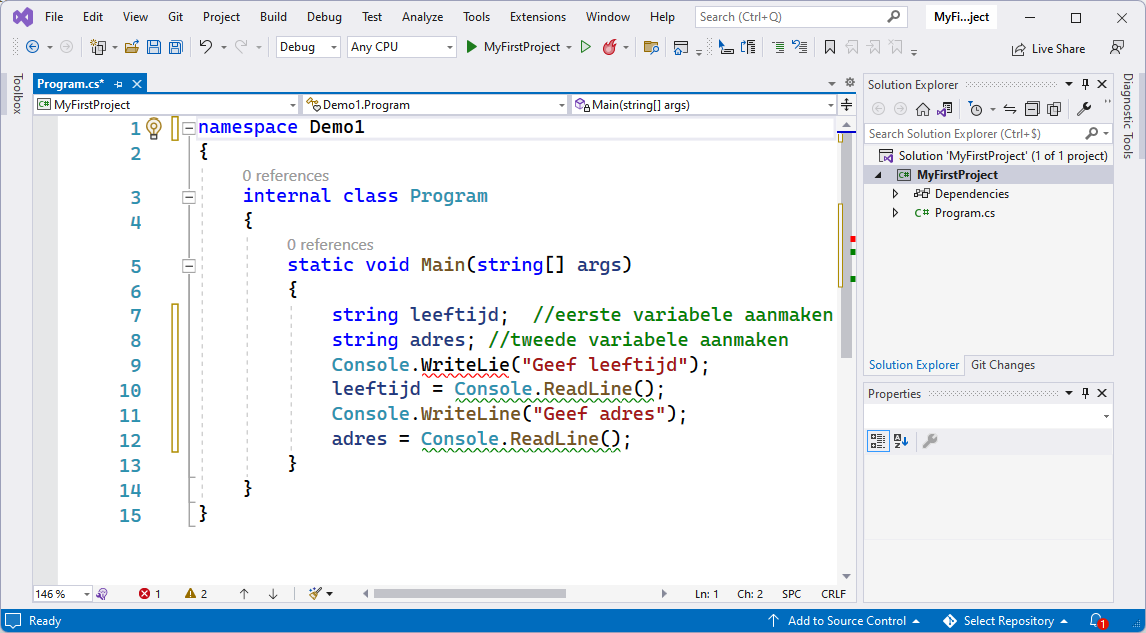


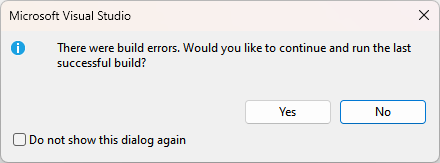
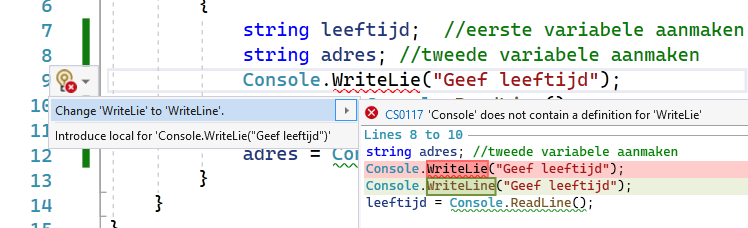
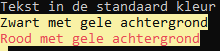
Aandacht, aandacht! Step away from the keyboard! I repeat. Step away from the keyboard. Hierbij wil ik u attent maken op een belangrijke, onbeschreven, wet voor C# programmeurs: "NEVER EVER USE GOTO"
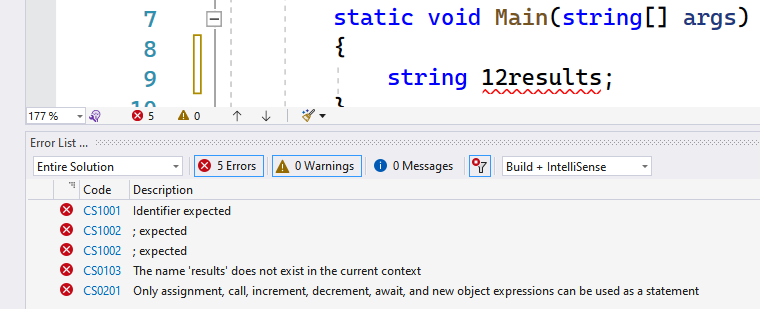

"Wow. Moet je al die datatypes uit het hoofd kennen? Ik was al blij dat ik tekst op het scherm kon tonen."
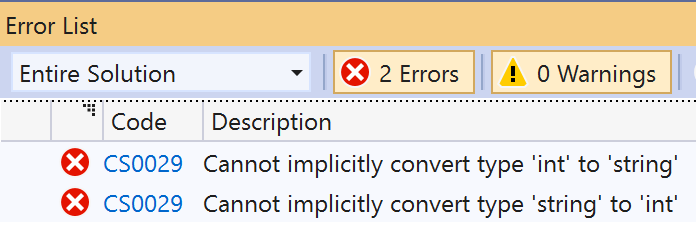
Gegroet! Zet je helm op en let alsjeblieft goed op. Als je de volgende sectie goed begrijpt dan heb je al een grote stap vooruit gezet in de wondere wereld van C#.
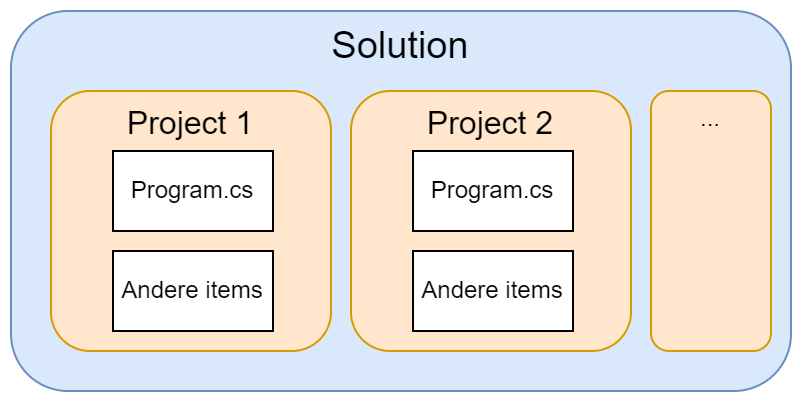
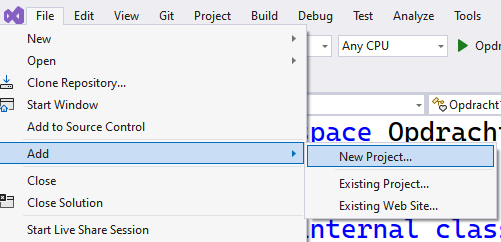
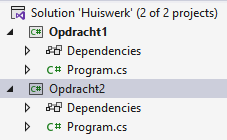
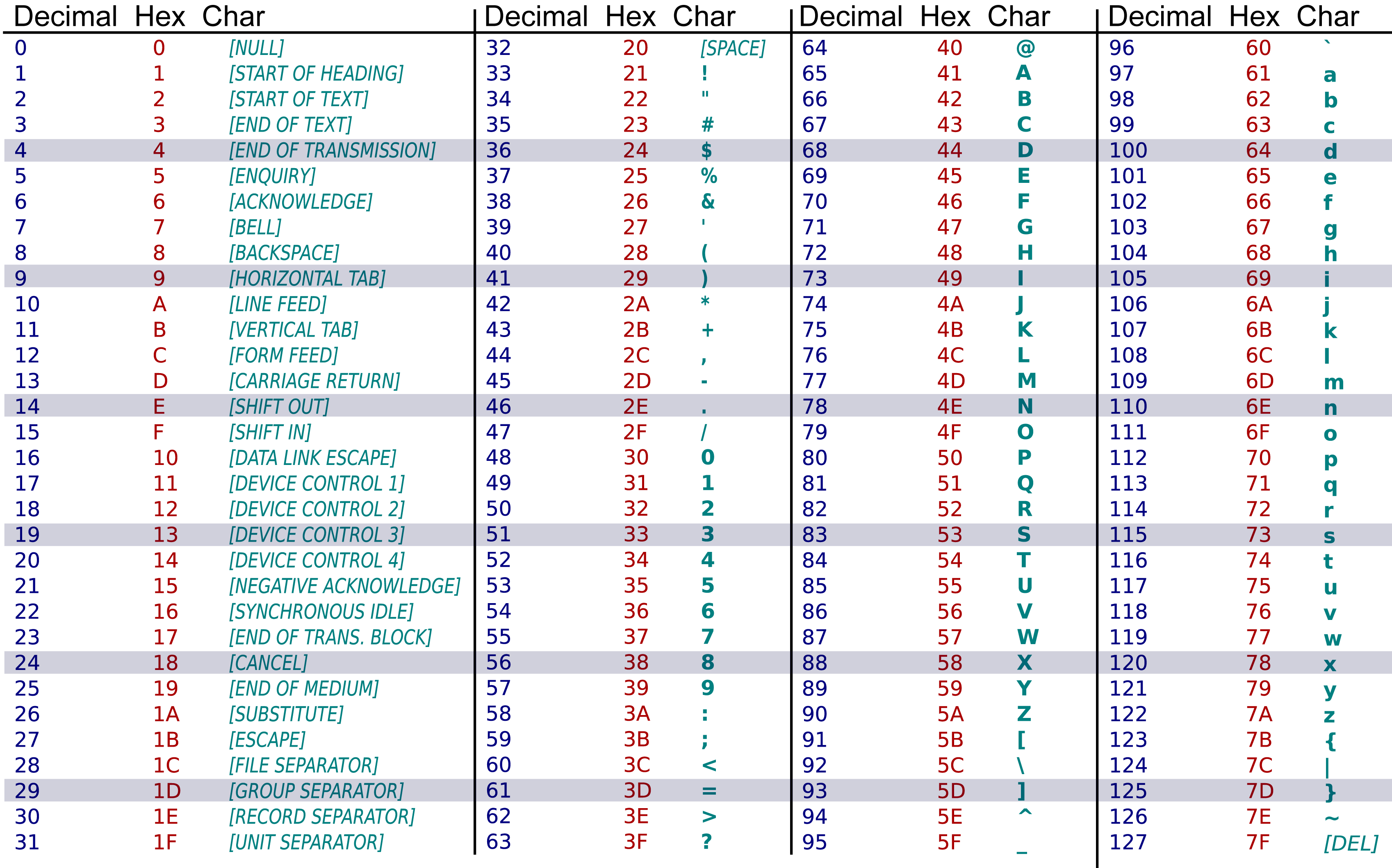
De voorman hier! Escape characters zijn niet de boeiendste materie om te bespreken. Je zou nog kunnen hopen dat het een opvolger is van Prison Break of zo. Helaas is dat niet zo. Echter: als je escape characters beheerst zal je veel eenvoudiger én mooier tekst op je scherm kunnen toveren. Let dus even goed op a.u.b.
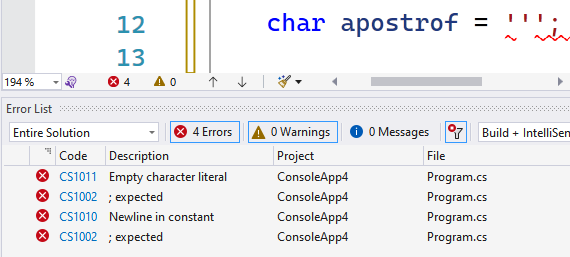

Mogelijk was deze laatste sectie wat verwarrend. Dat is bewust gedaan...sort of. C# leren kan in het begin soms nogal saai lijken. Daarom dat ik ervoor kies om hier en daar een iets meer geavanceerd aspect te bespreken.

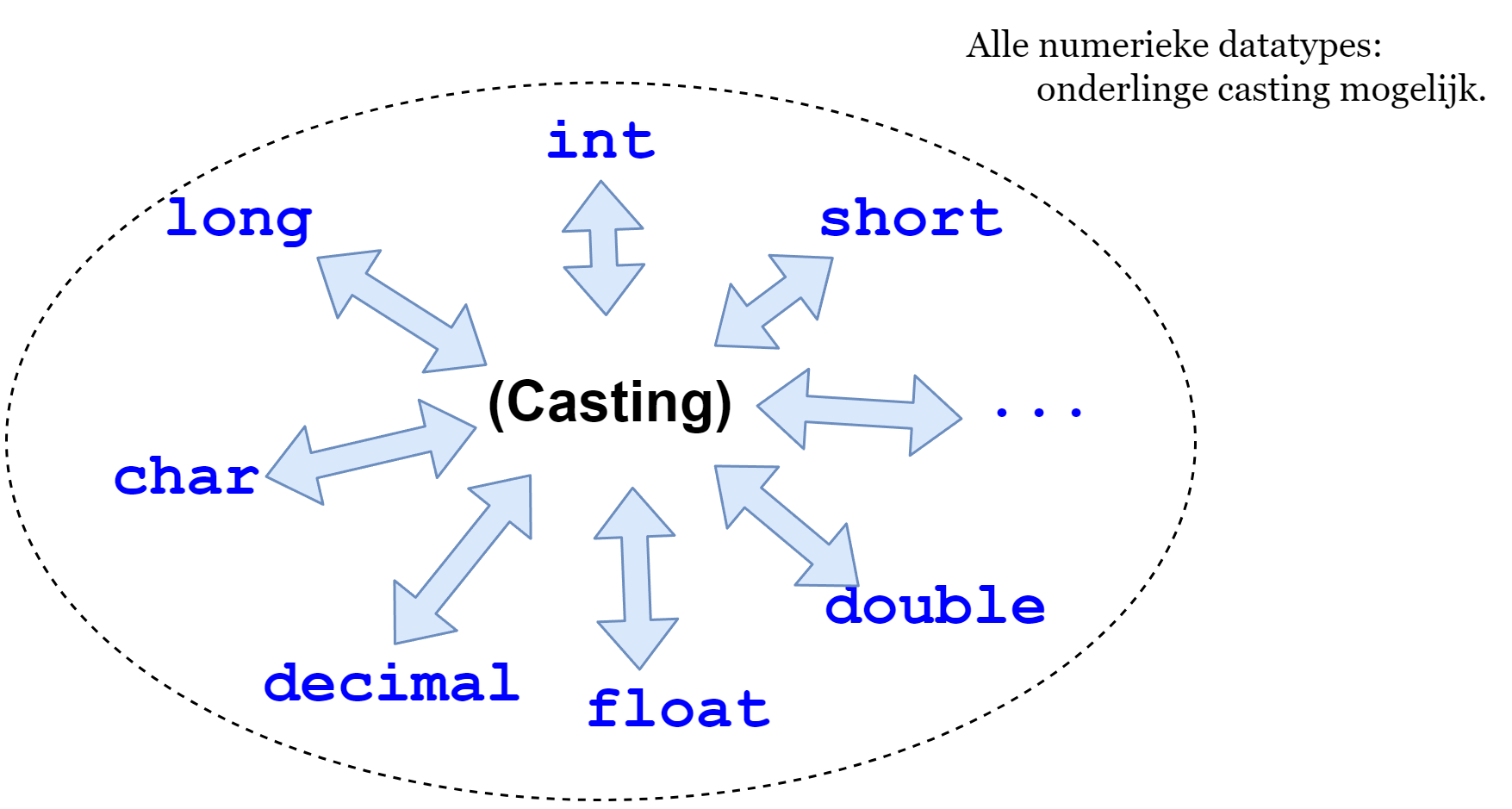
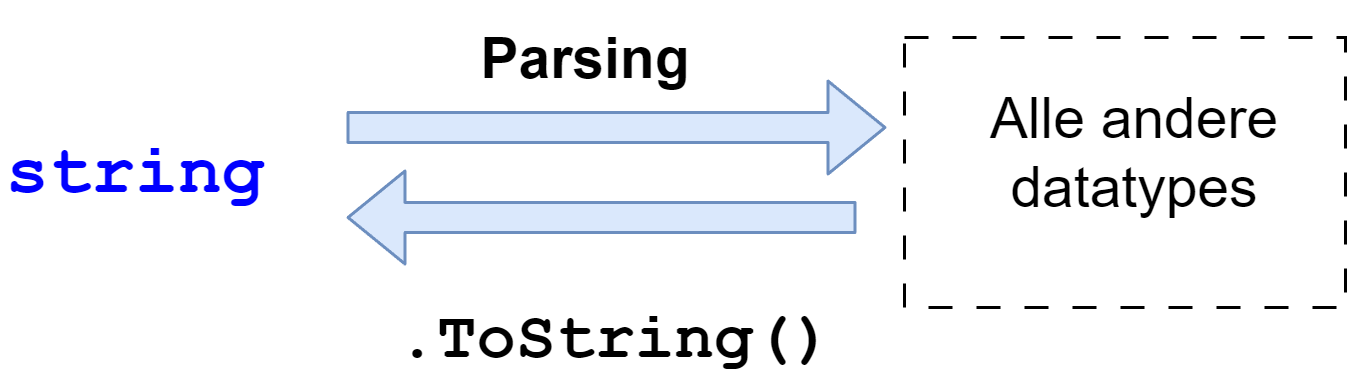

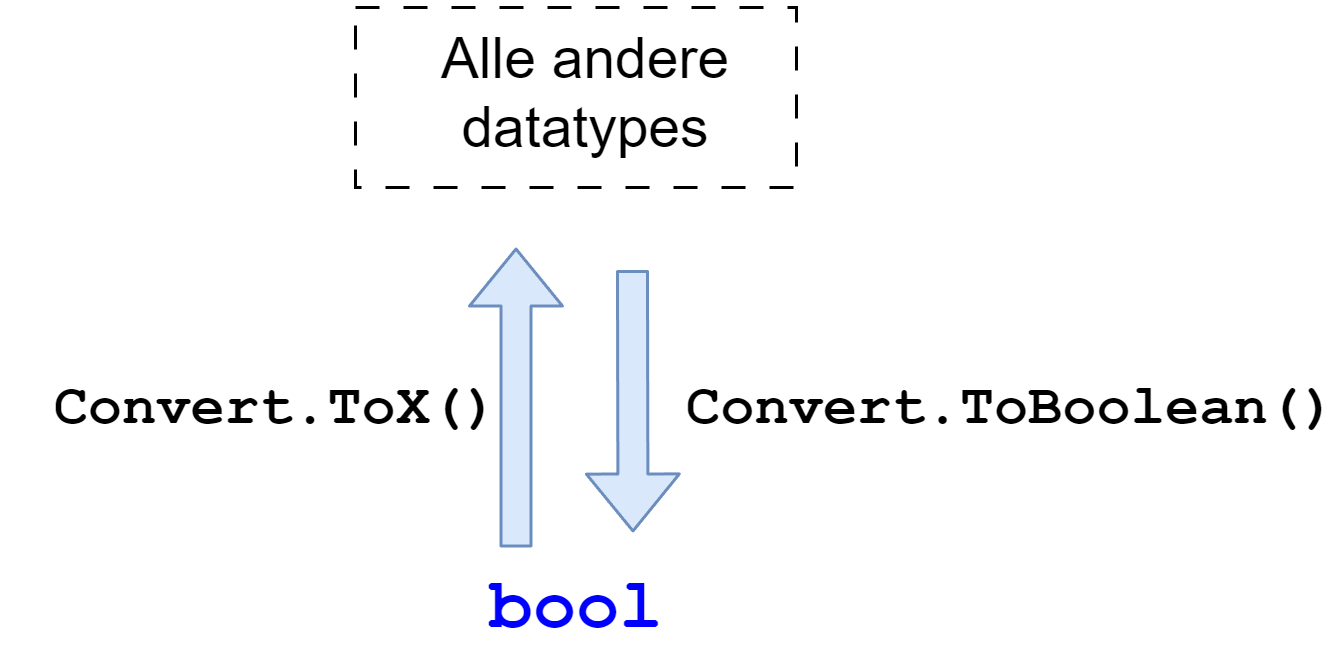
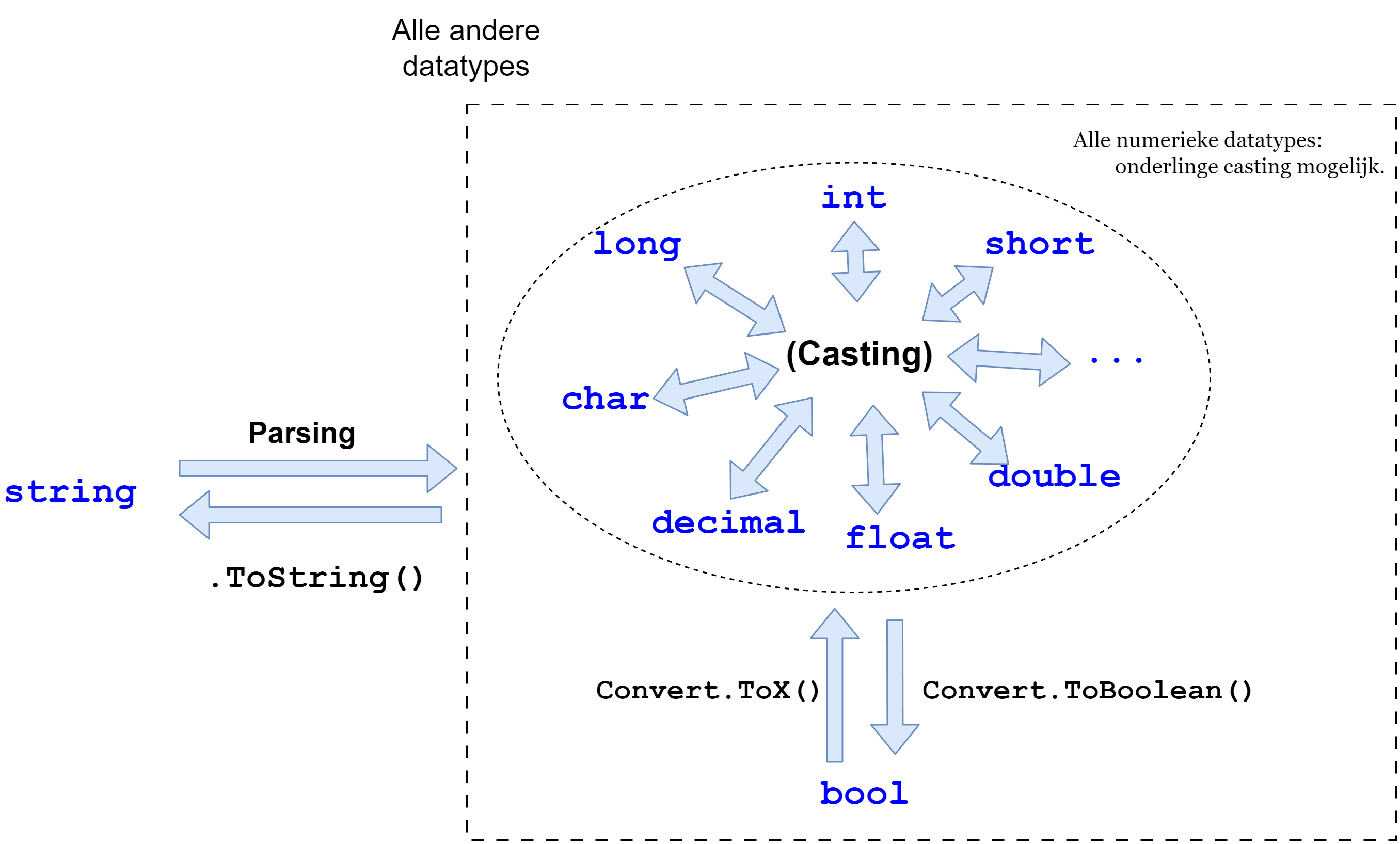

"Help! Ik krijg steeds dezelfde random getallen? Wat nu?"


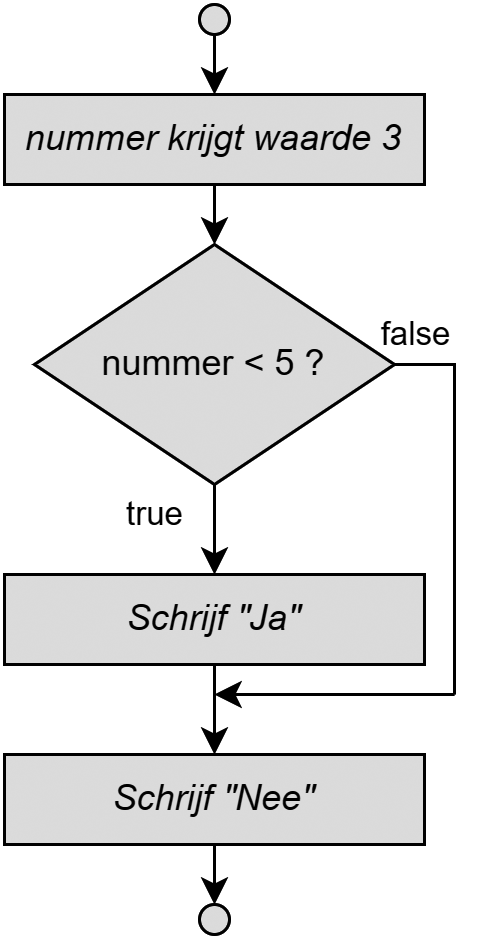
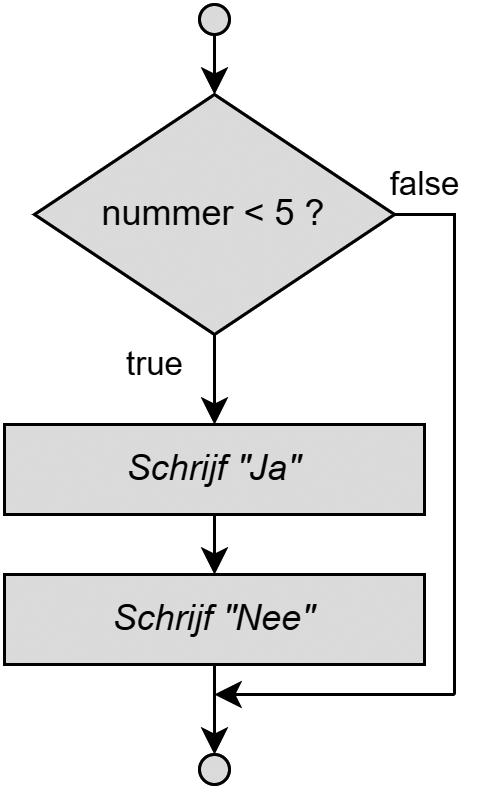
Voorman hier! Je hebt me gemist. Ik merk het. Het ging goed de laatste tijd. Maar nu wordt het tijd dat ik je weer even wakker schud want de code die je nu gaat bouwen kan érg vreemde gedragingen krijgen als je niet goed oplet. Luister daarom even naar deze lijst van veel gemaakte fouten wanneer je met
Laat deze tiental bladzijden uitleg je niet de indruk geven dat code schrijven met
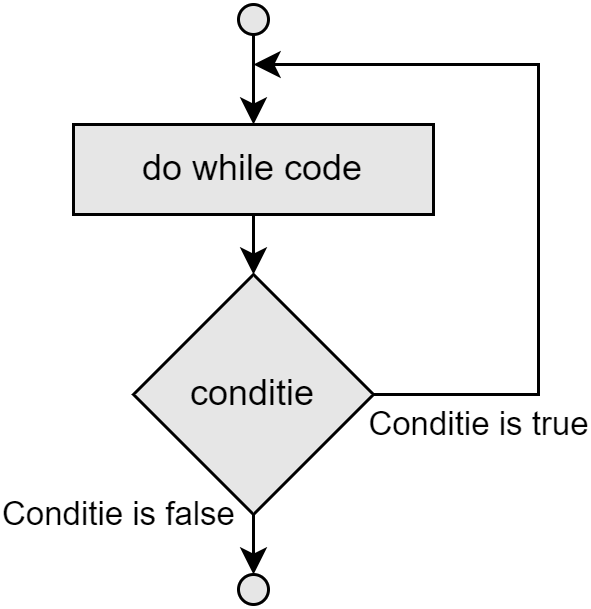
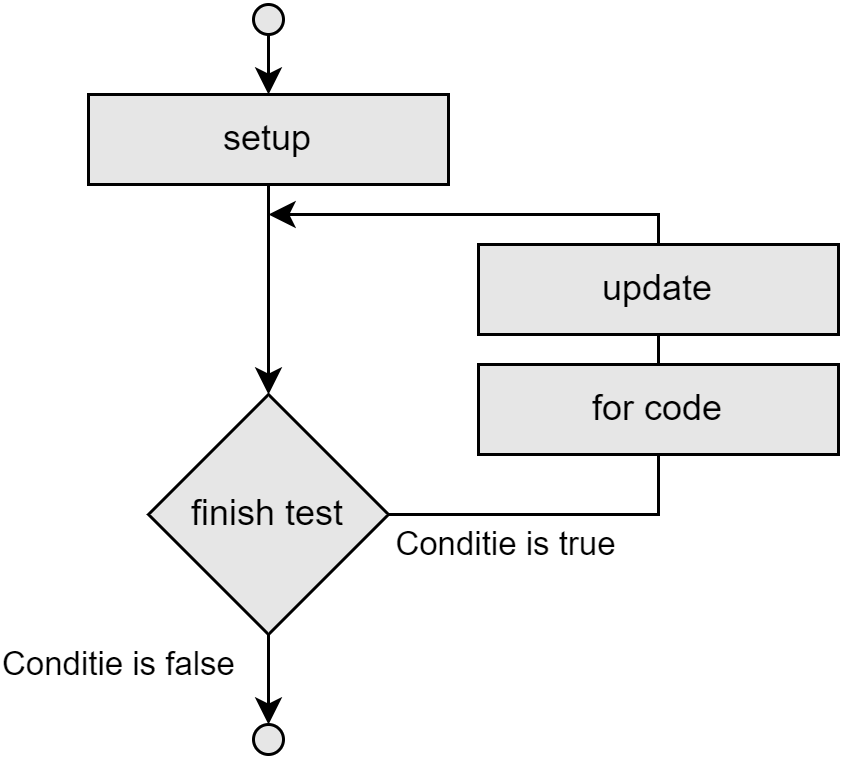

Olla!? Wat denken we dat we aan het doen zijn? Gelieve die keywords ogenblikkelijk terug uit je code te verwijderen. Bedankt.
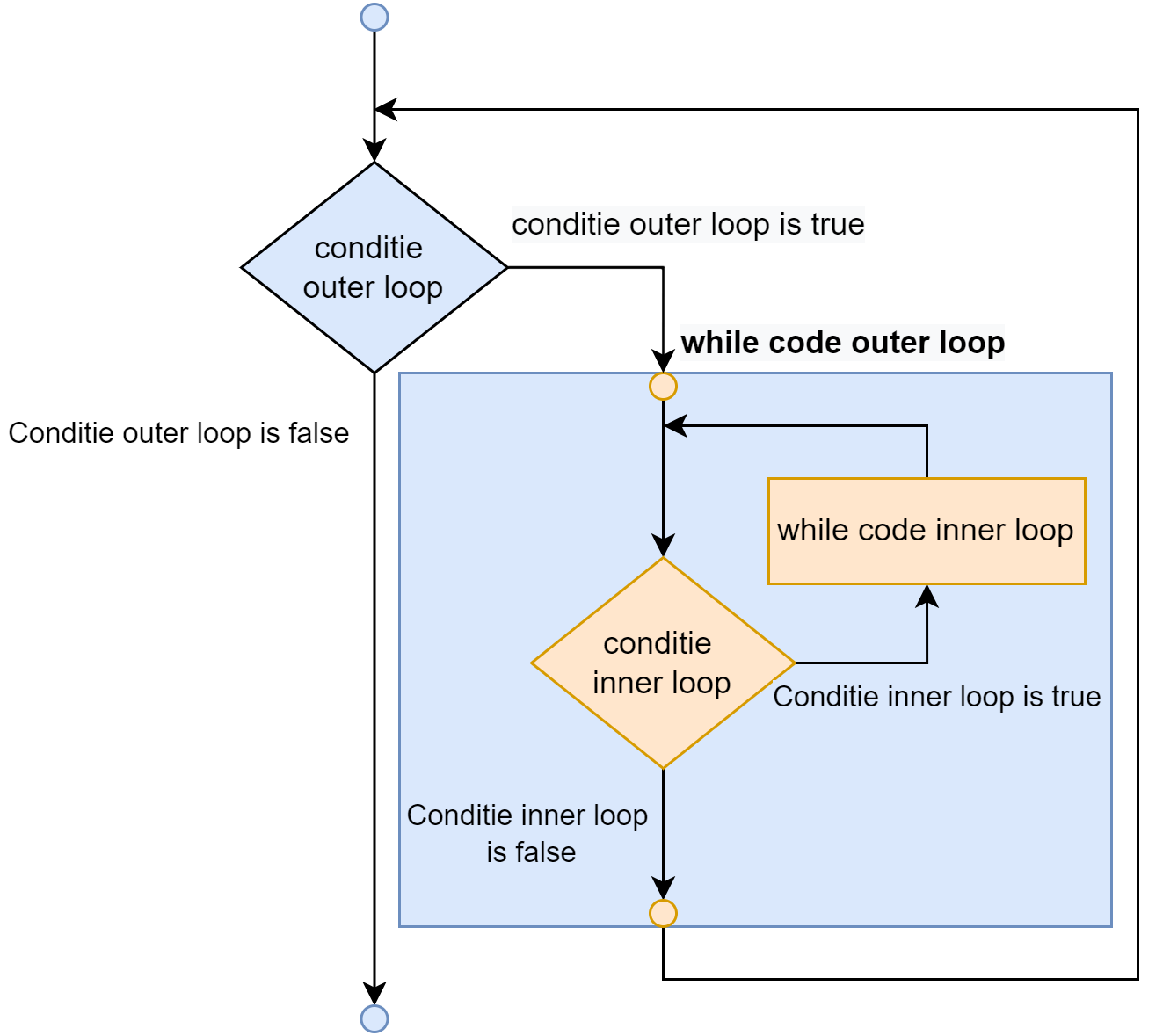
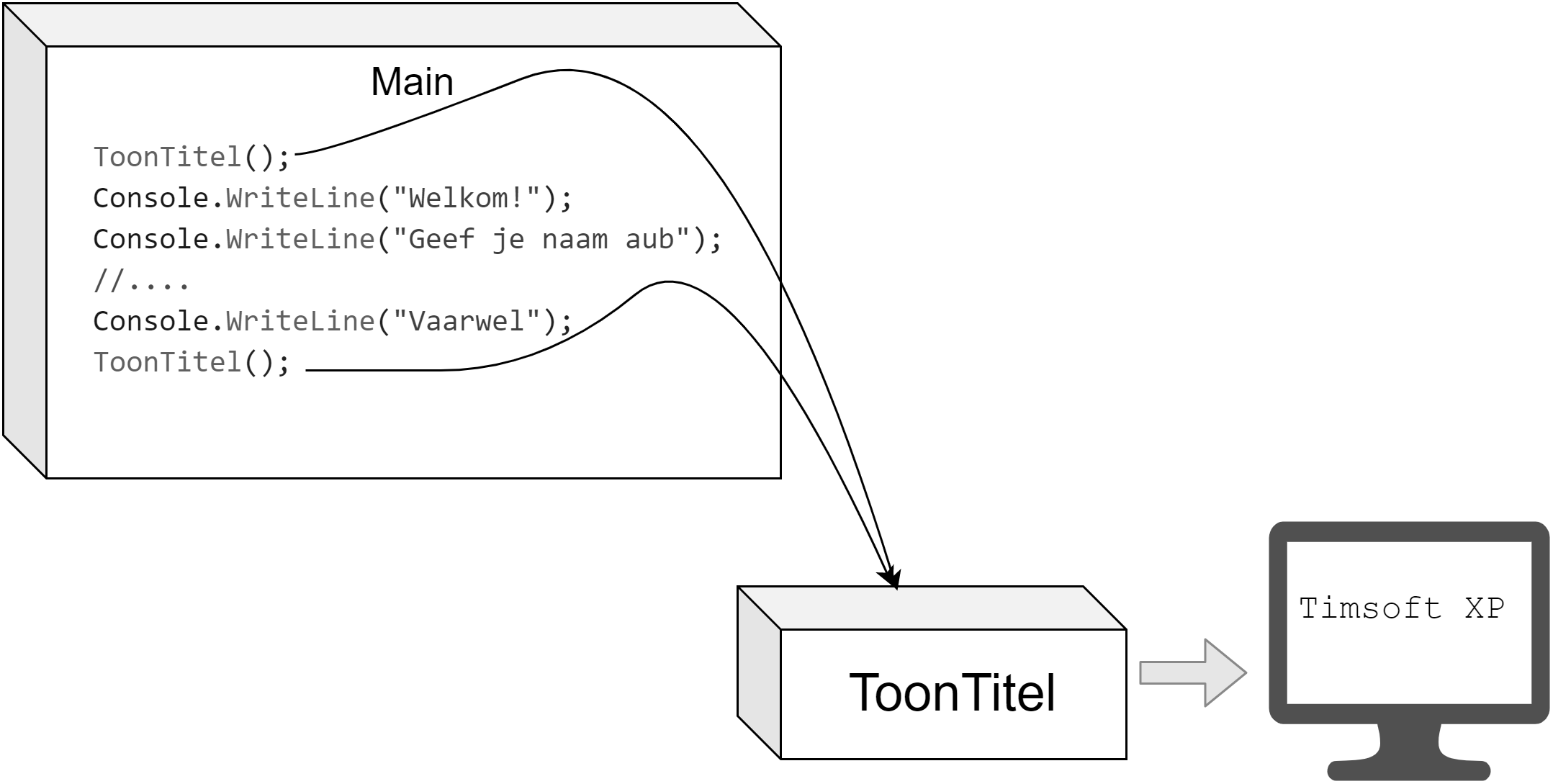
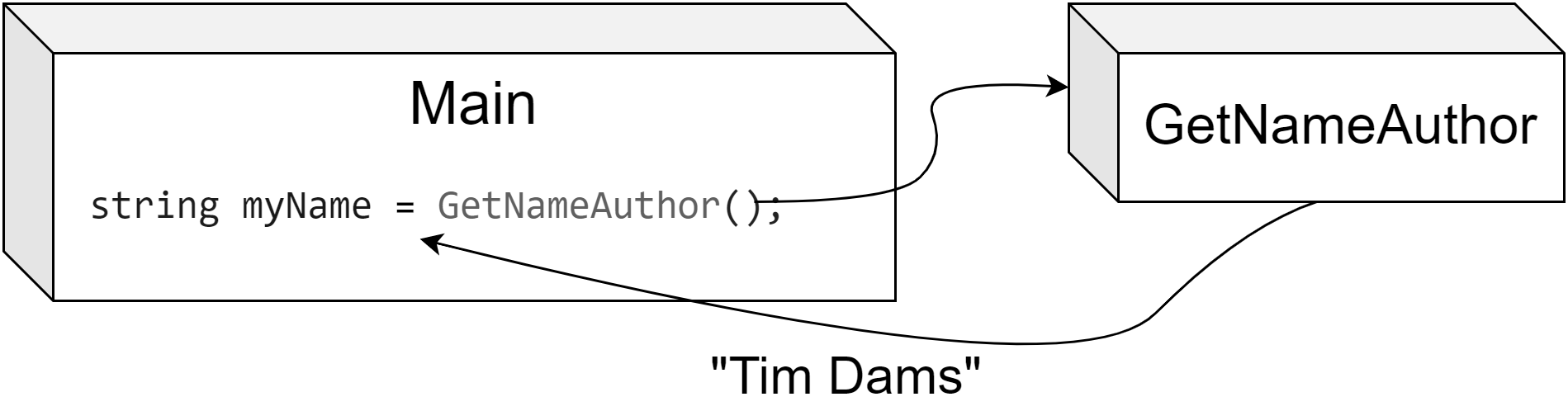
Dacht je nu echt dat ik weg was?! Het is me opgevallen dat je niet altijd de foutboodschappen in VS leest. Ik blijf alvast uit jouw buurt als je zo doorgaat. Doe jezelf (en mij) dus een plezier en probeer die foutboodschappen in de toekomst te begrijpen. Er zijn er maar een handvol en bijna altijd komen ze op hetzelfde neer. Neem nou de volgende:Not all code paths return a value Die ga je nog vaak tegenkomen!



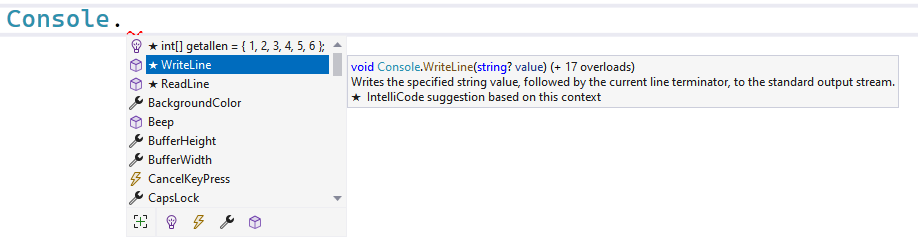


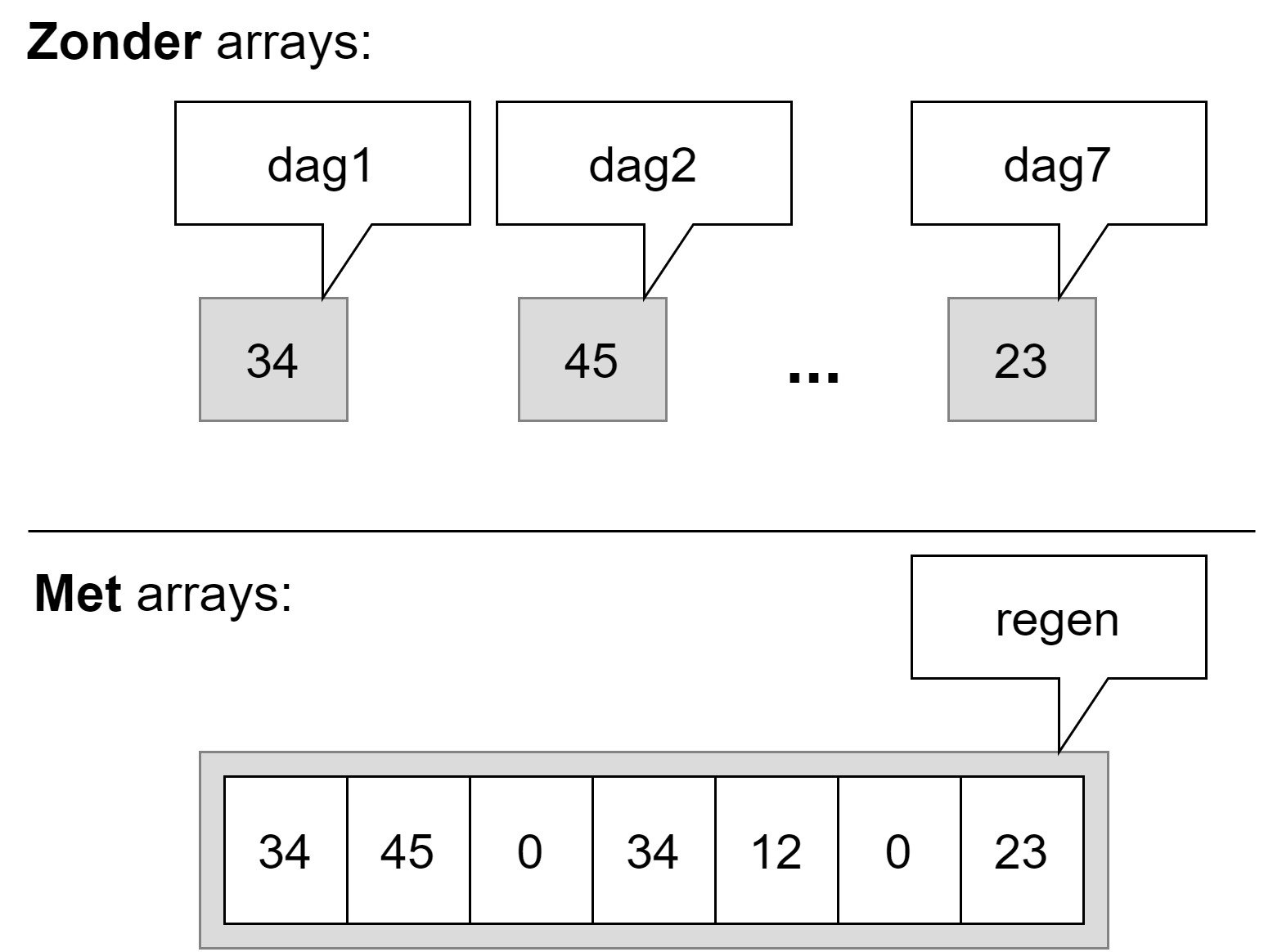
 Sorry dat we weer even in het diepe water zijn gedoken. Het leek ons nuttig om even het totaalplaatje van arrays alvast uit de doeken te doen, zodat je snapt waarom er hier zo enthousiast over arrays wordt gedaan.
Sorry dat we weer even in het diepe water zijn gedoken. Het leek ons nuttig om even het totaalplaatje van arrays alvast uit de doeken te doen, zodat je snapt waarom er hier zo enthousiast over arrays wordt gedaan. 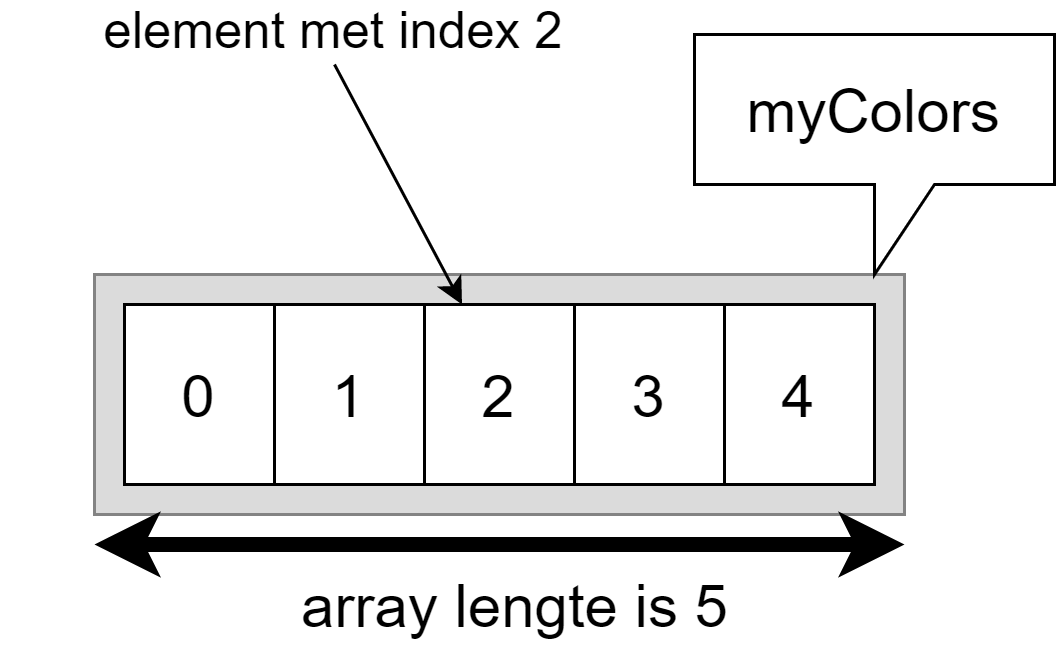
 Veelgemaakte fouten bij arrays gebeuren op de lengte en indexering ervan.
Veelgemaakte fouten bij arrays gebeuren op de lengte en indexering ervan.
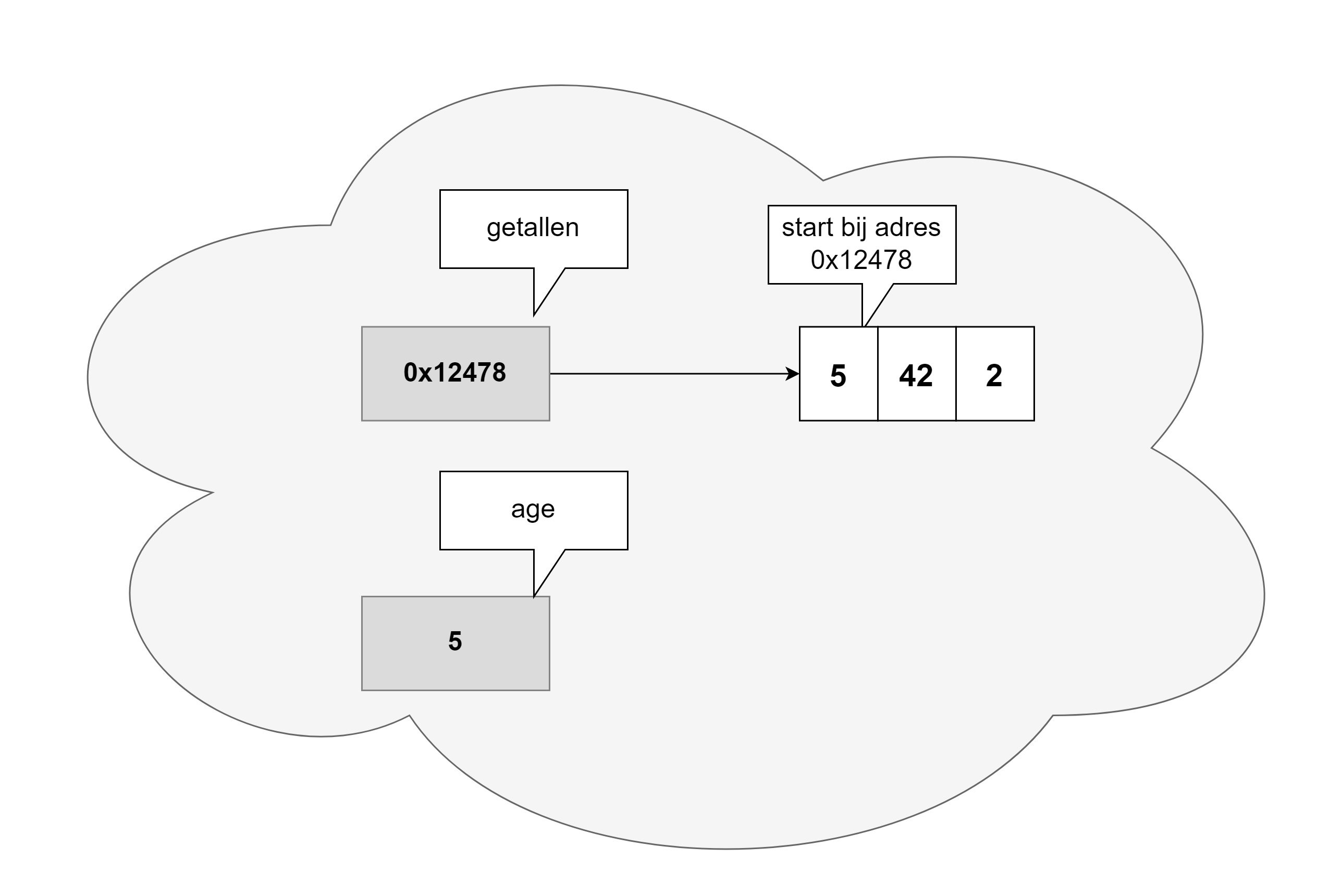
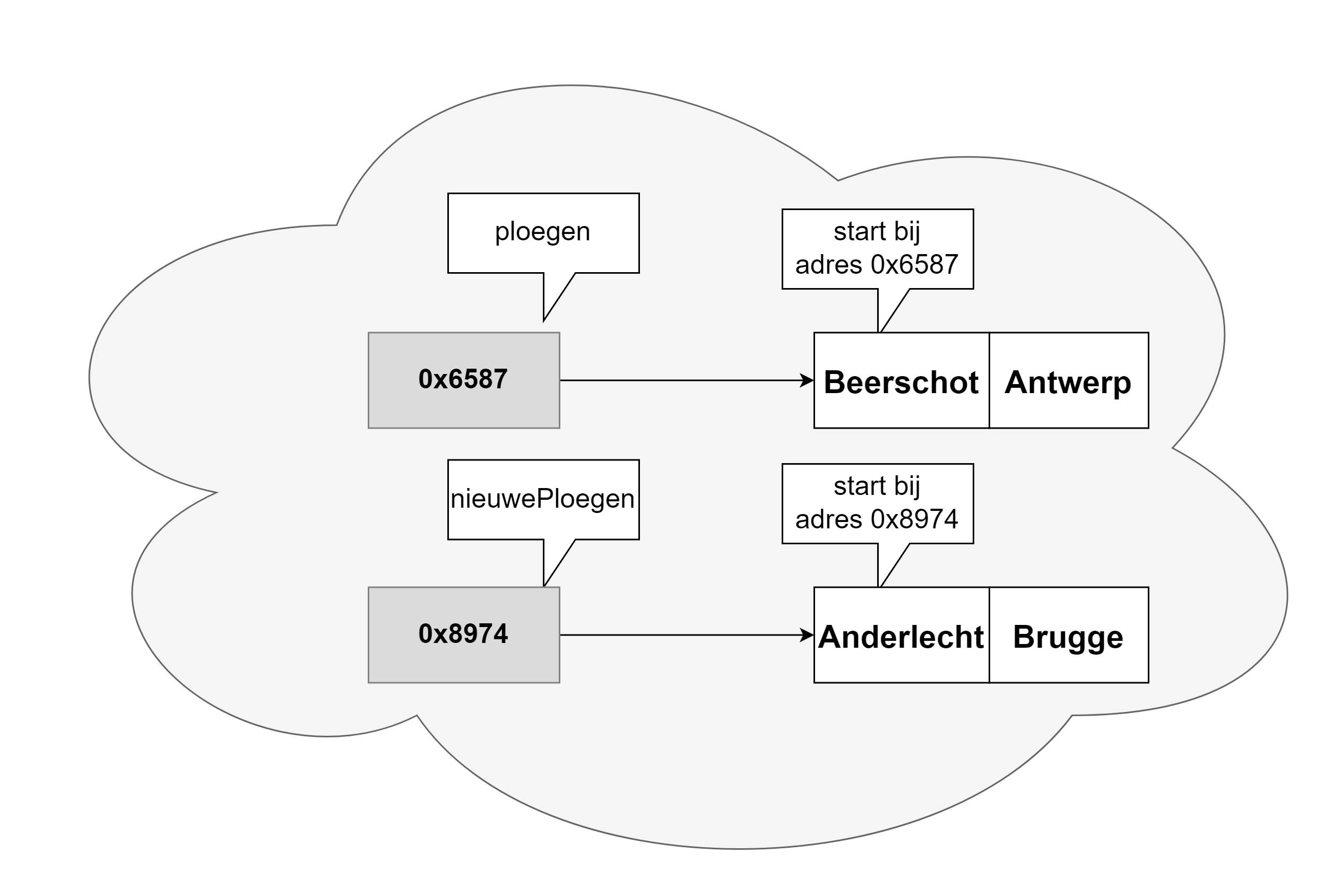
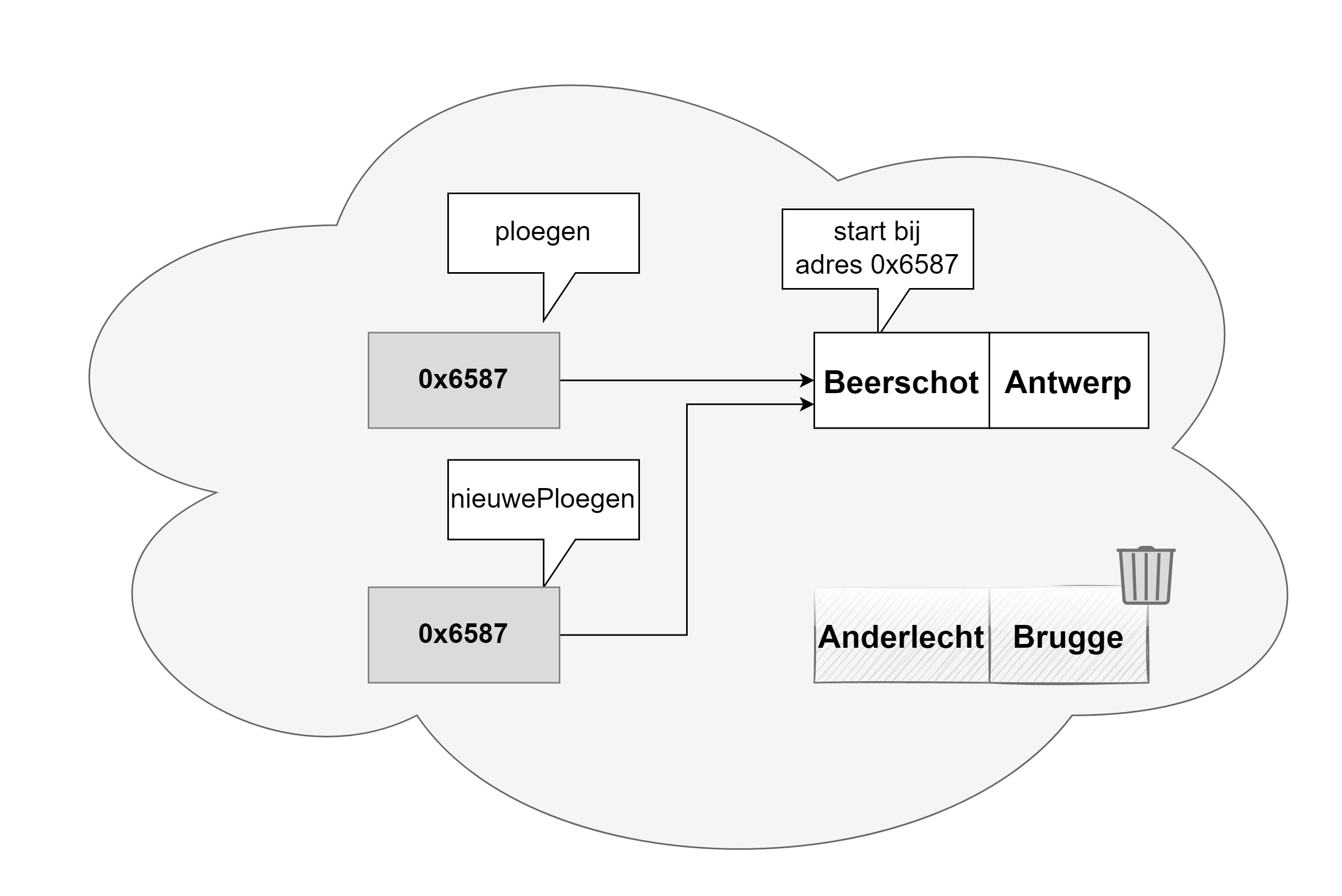

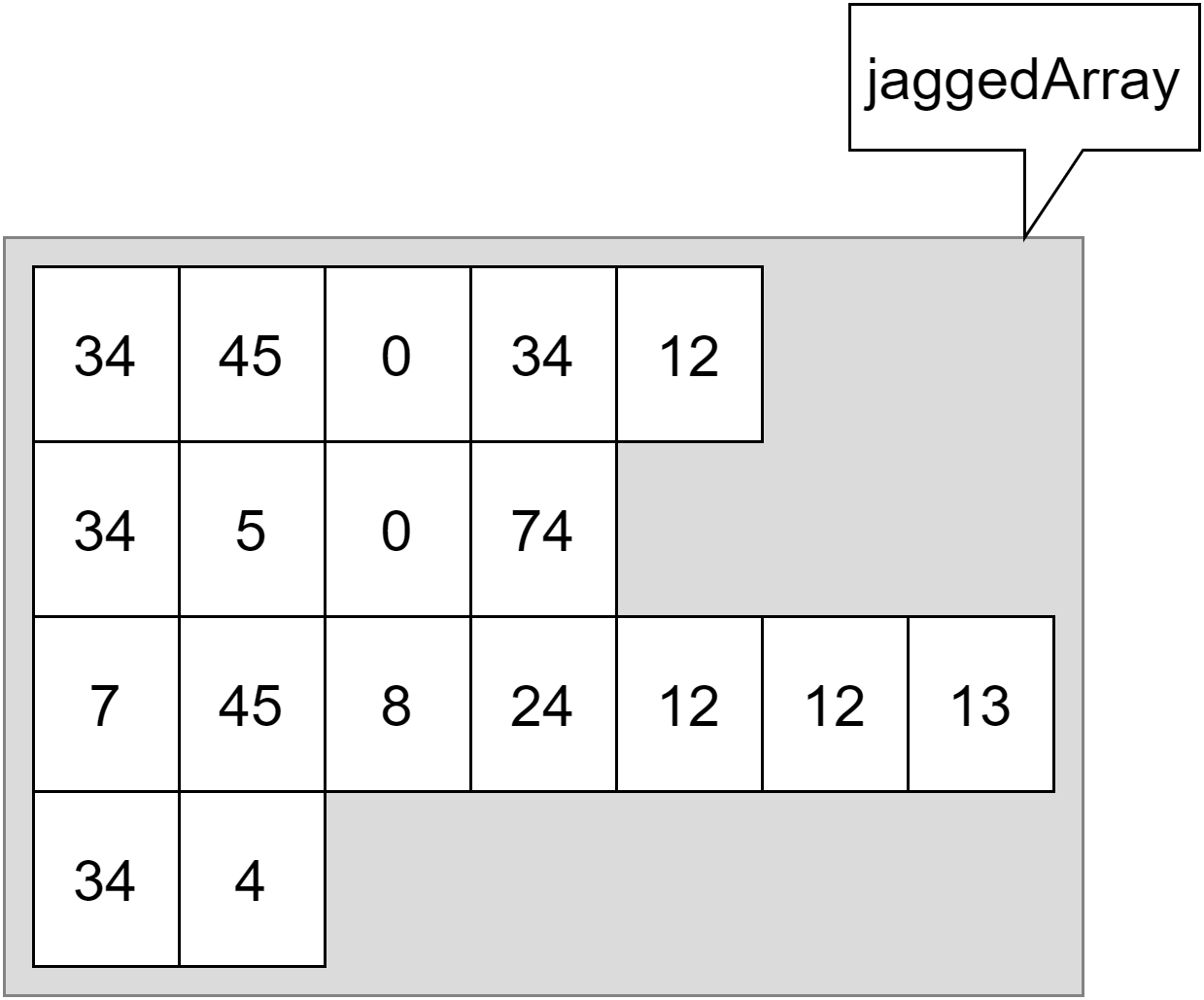
 Ik zet "oplossen" tussen aanhalingstekens. Net zoals alles binnen dit domein ben jij als programmeur uiteindelijk degene die het boeltje moet oplossen. Code, programmeerparadigma's en bibliotheken zijn niet meer dan nuttig gereedschap in jouw arsenaal van programmeertools. Als jij beslist om een hamer als zaag te gebruiken... Tja, dan houd ik m'n hart vast voor het resultaat.
Ik zet "oplossen" tussen aanhalingstekens. Net zoals alles binnen dit domein ben jij als programmeur uiteindelijk degene die het boeltje moet oplossen. Code, programmeerparadigma's en bibliotheken zijn niet meer dan nuttig gereedschap in jouw arsenaal van programmeertools. Als jij beslist om een hamer als zaag te gebruiken... Tja, dan houd ik m'n hart vast voor het resultaat.  Duizend mammoeten en sabeltandtijgers! Ik dacht dat ik nu wel mee zou zijn met alles wat C# me zou voorschotelen. Helaas, wolharige neushoorn-kaas, niet dus. Ik ga een voorspelling doen: van alle hoofdstukken in dit boek, wordt dit hoofdstuk hetgene waar je het meest je tanden op gaat stuk bijten. Hou dus vol, geef niet te snel op en kom geregeld hier terug. Succes gewenst!
Duizend mammoeten en sabeltandtijgers! Ik dacht dat ik nu wel mee zou zijn met alles wat C# me zou voorschotelen. Helaas, wolharige neushoorn-kaas, niet dus. Ik ga een voorspelling doen: van alle hoofdstukken in dit boek, wordt dit hoofdstuk hetgene waar je het meest je tanden op gaat stuk bijten. Hou dus vol, geef niet te snel op en kom geregeld hier terug. Succes gewenst!
 Wat?! Ik ben hier niet voor jou? Omdat je geen
Wat?! Ik ben hier niet voor jou? Omdat je geen 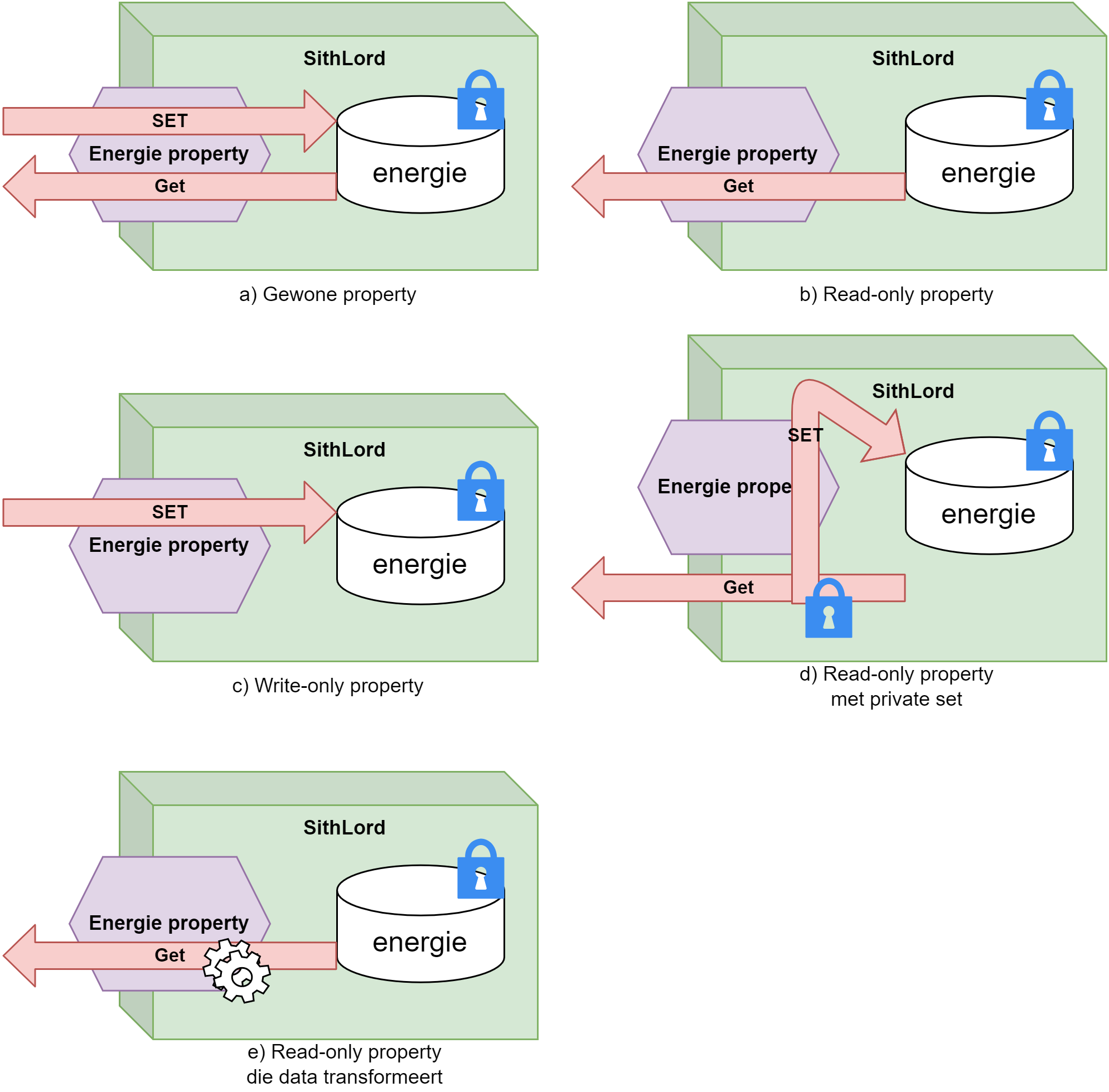
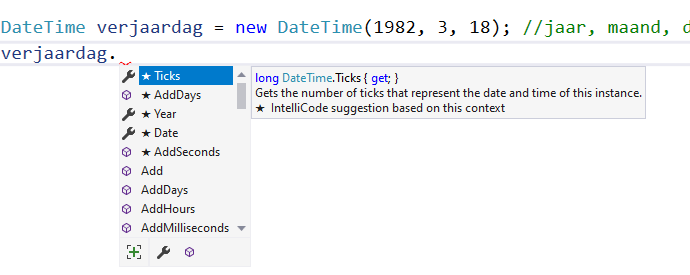
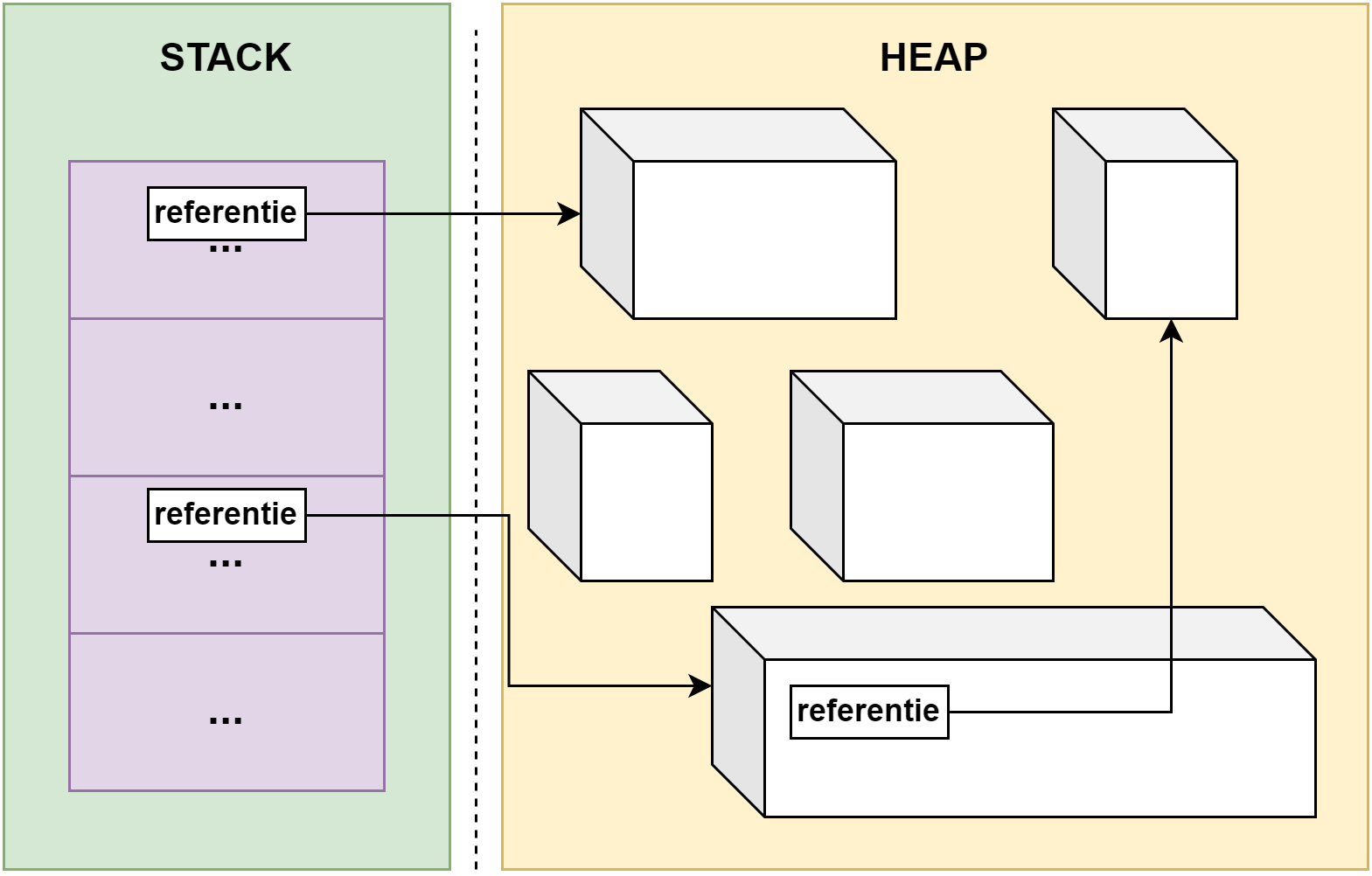
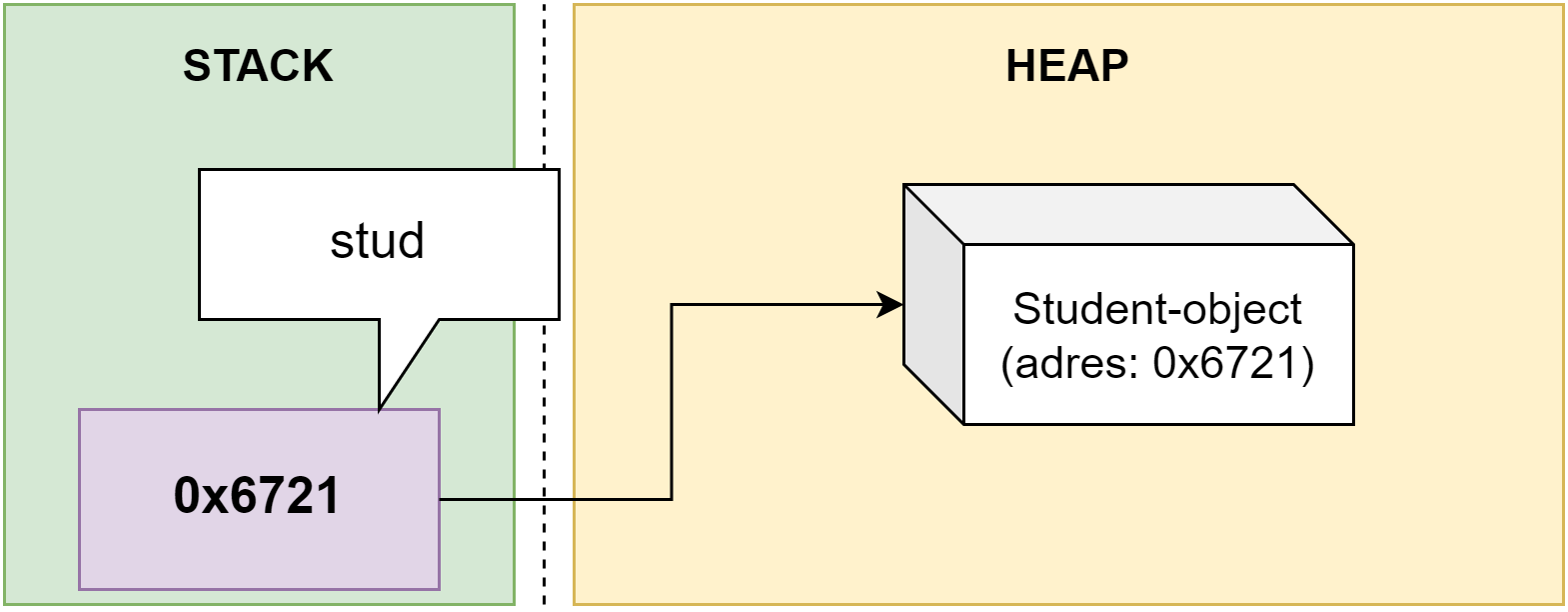
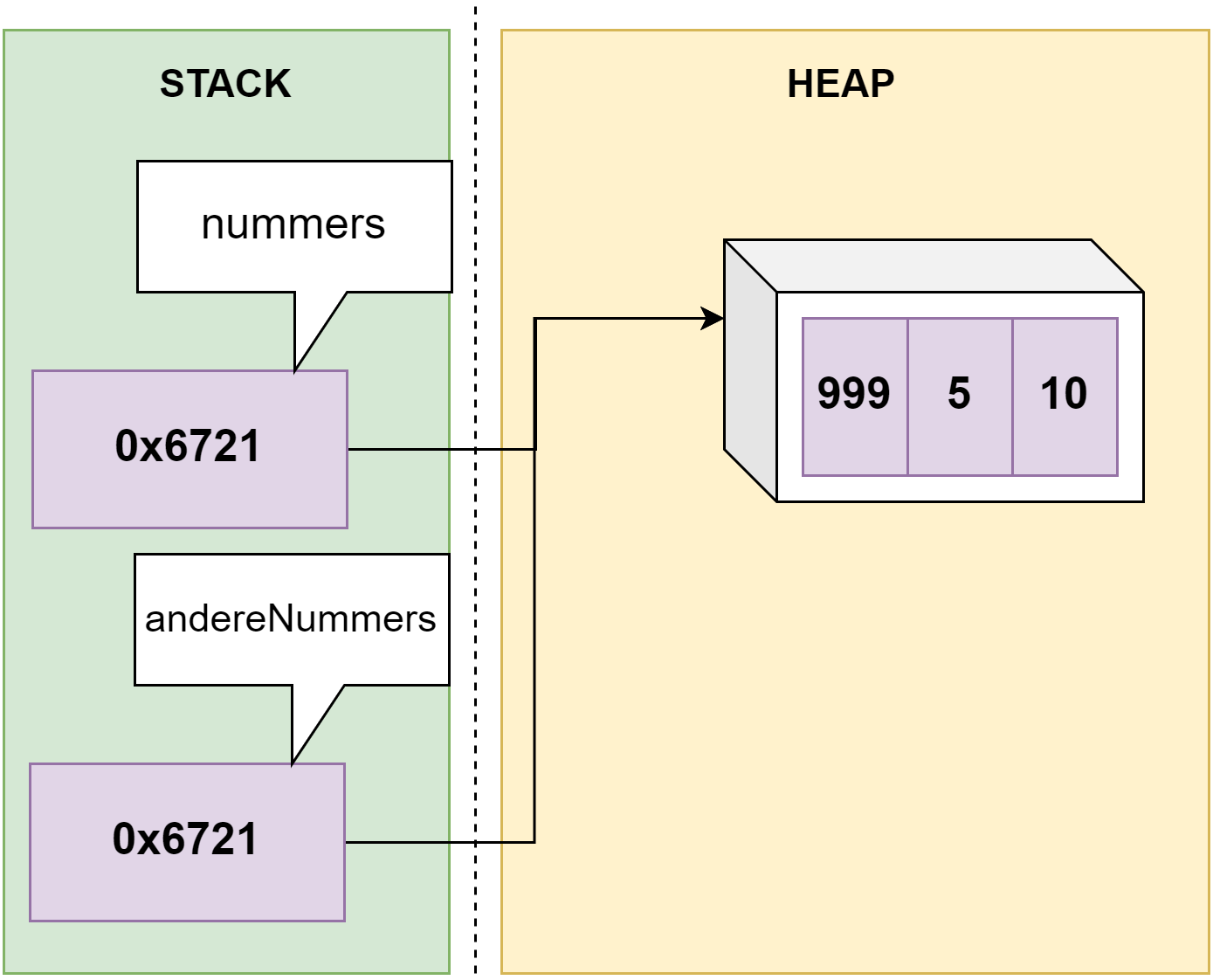
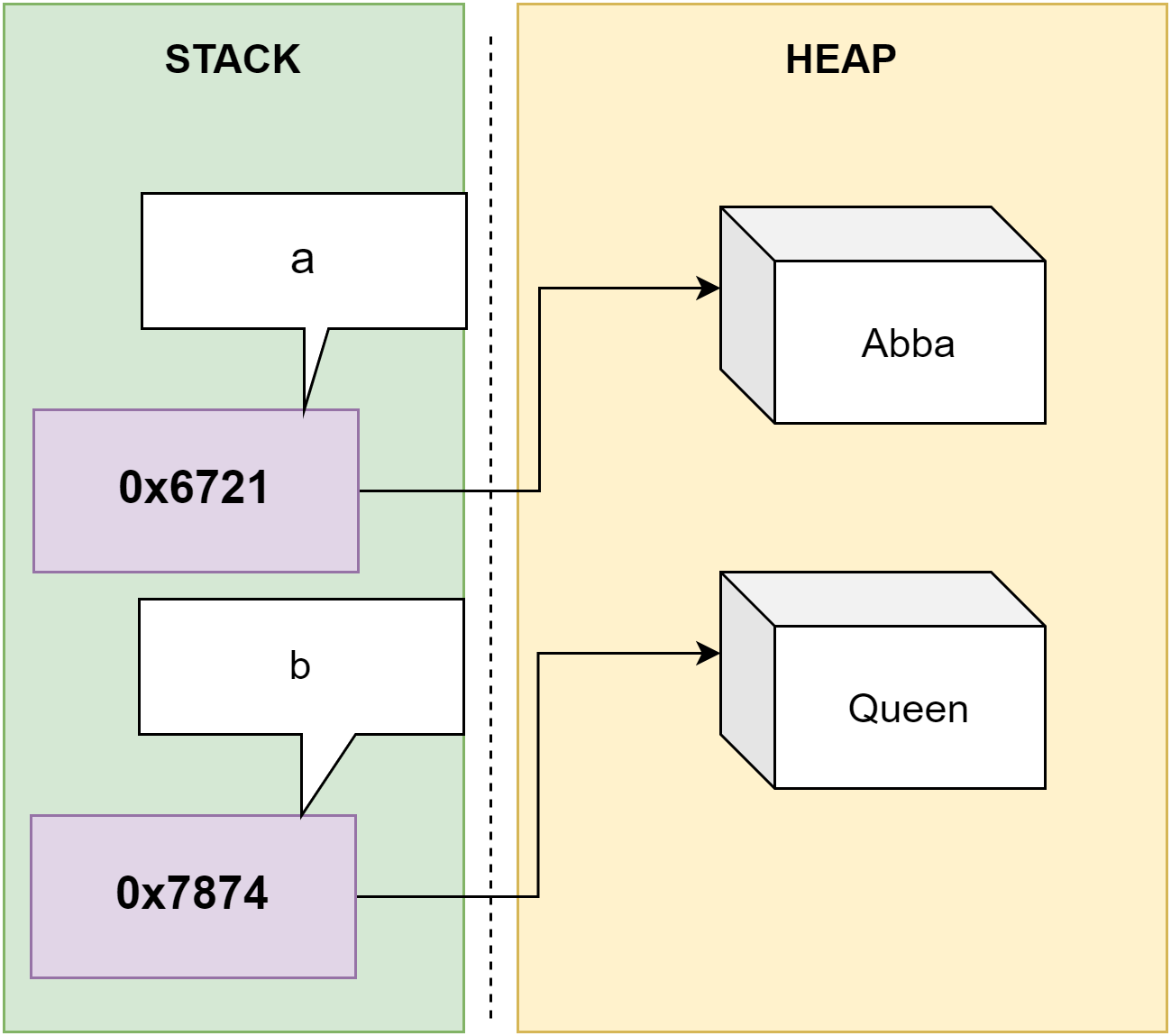
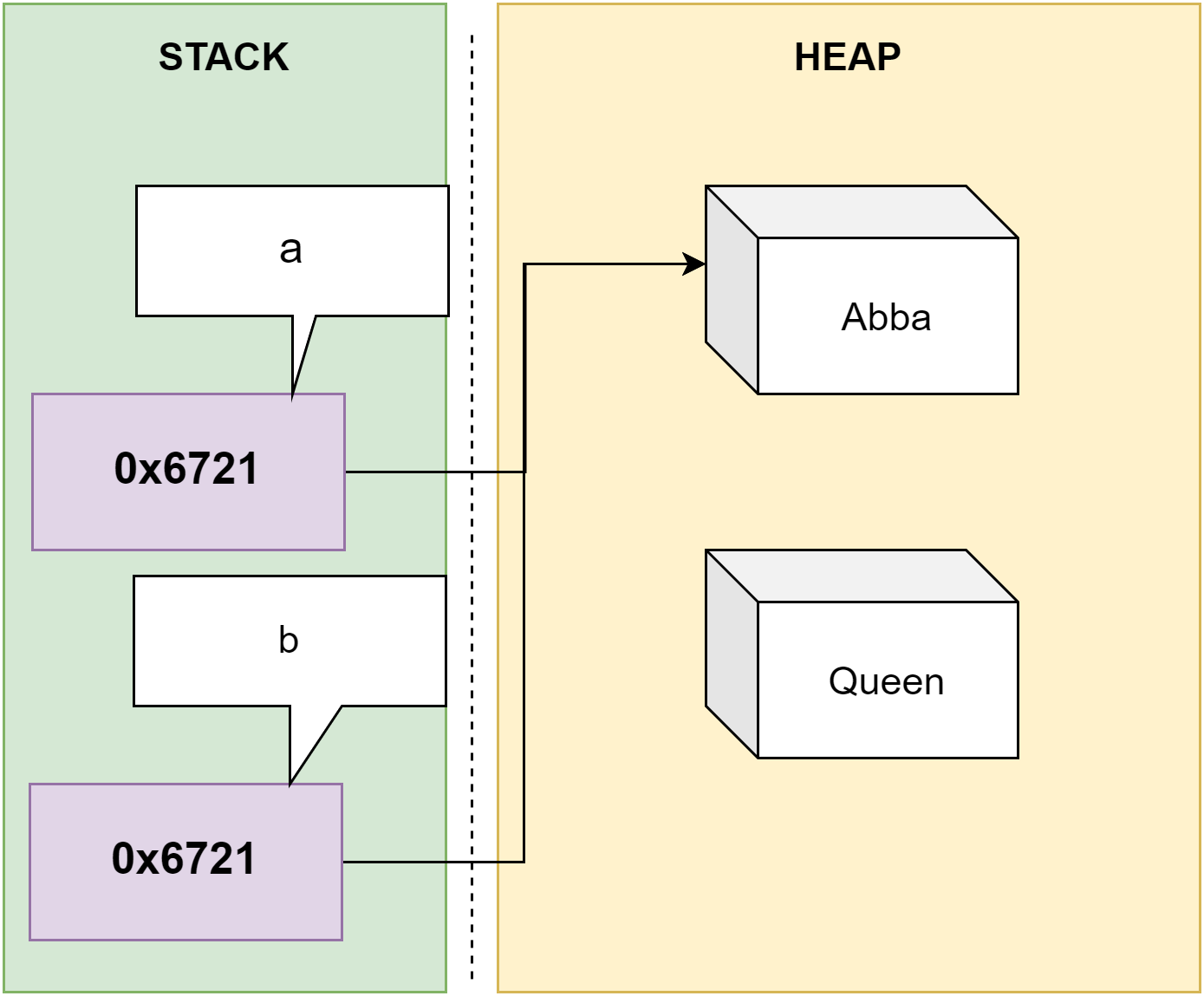
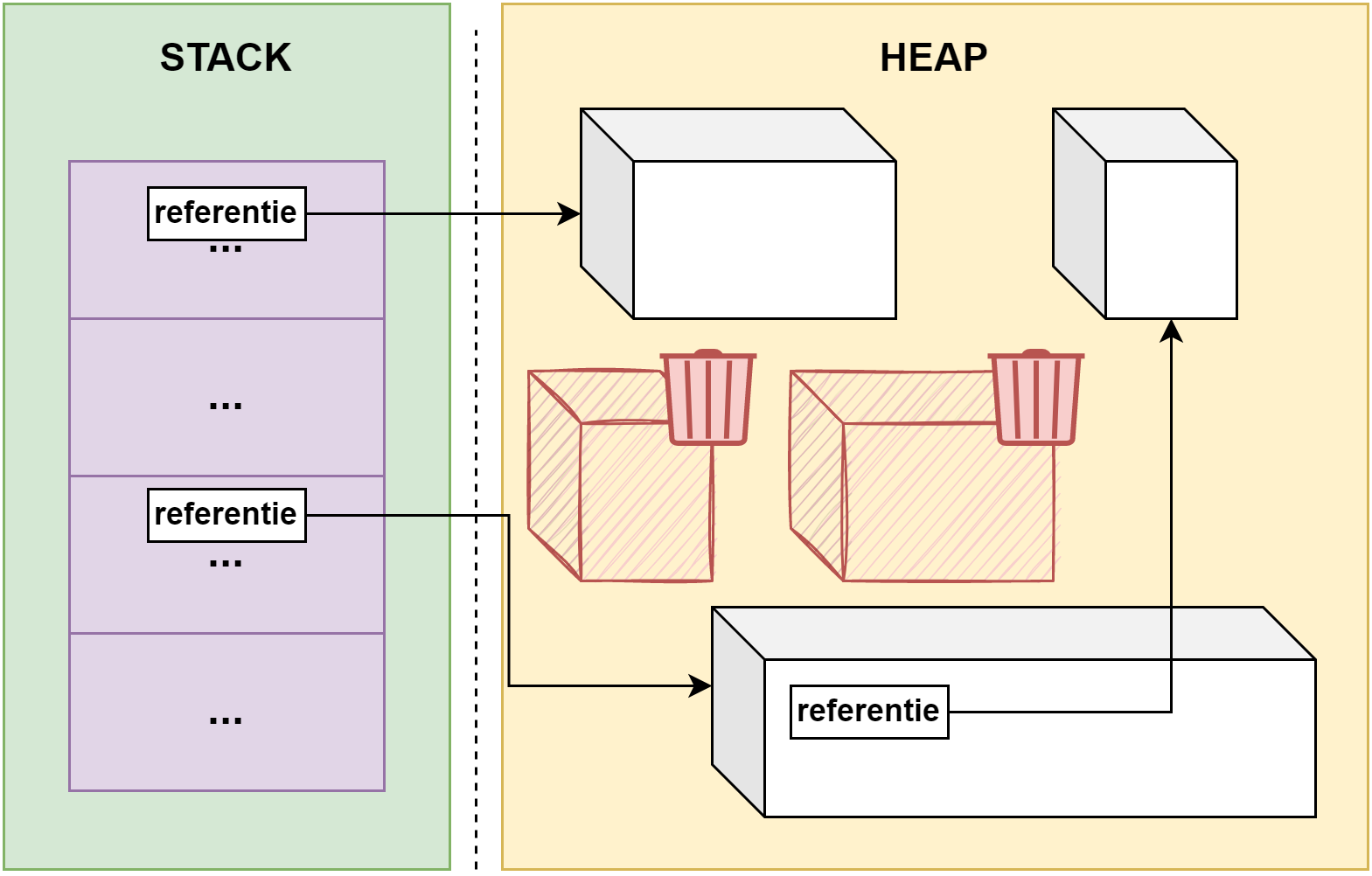
 De politie uw vriend! Inderdaad. De auteur van dit boek heeft klachten gekregen over het feit dat hij het edele beroep van politie-agent ietwat besmeurd. We willen daarom even u attenderen en, zoals een goed agent betaamd, u de weg doorheen de stad wijzen.
De politie uw vriend! Inderdaad. De auteur van dit boek heeft klachten gekregen over het feit dat hij het edele beroep van politie-agent ietwat besmeurd. We willen daarom even u attenderen en, zoals een goed agent betaamd, u de weg doorheen de stad wijzen.

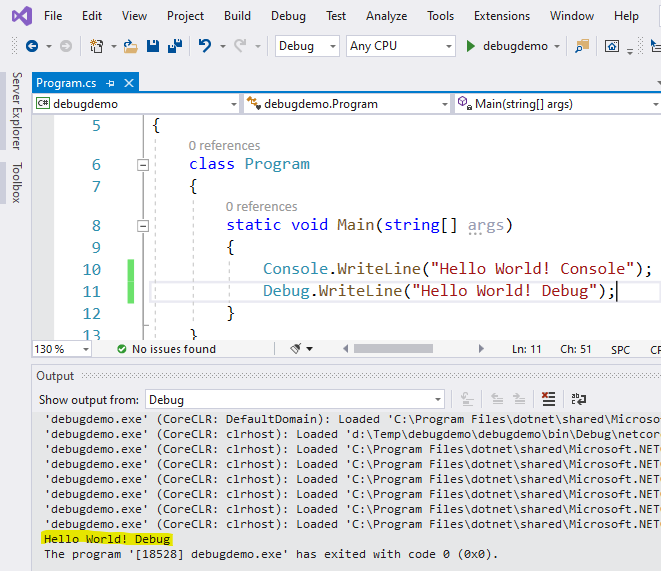
 Mooi zo. Nu we dat hebben bekeken kunnen terug keren naar het gebruik van het
Mooi zo. Nu we dat hebben bekeken kunnen terug keren naar het gebruik van het 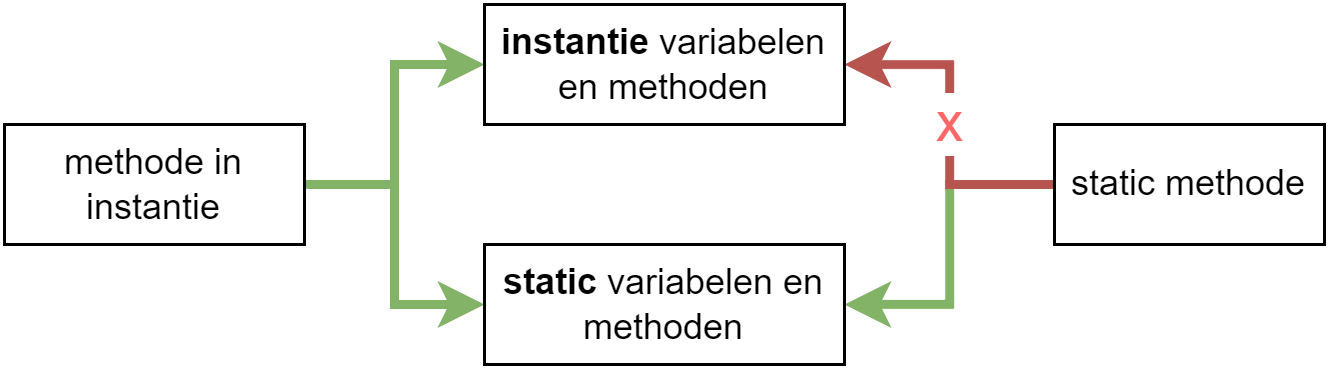
 Je zal
Je zal 
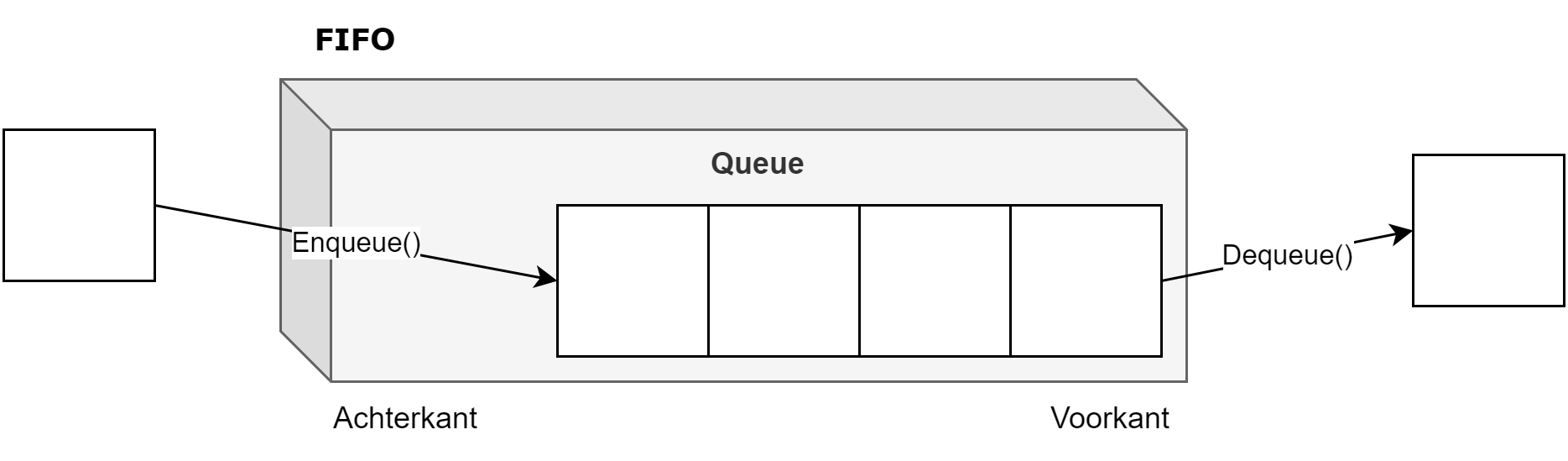
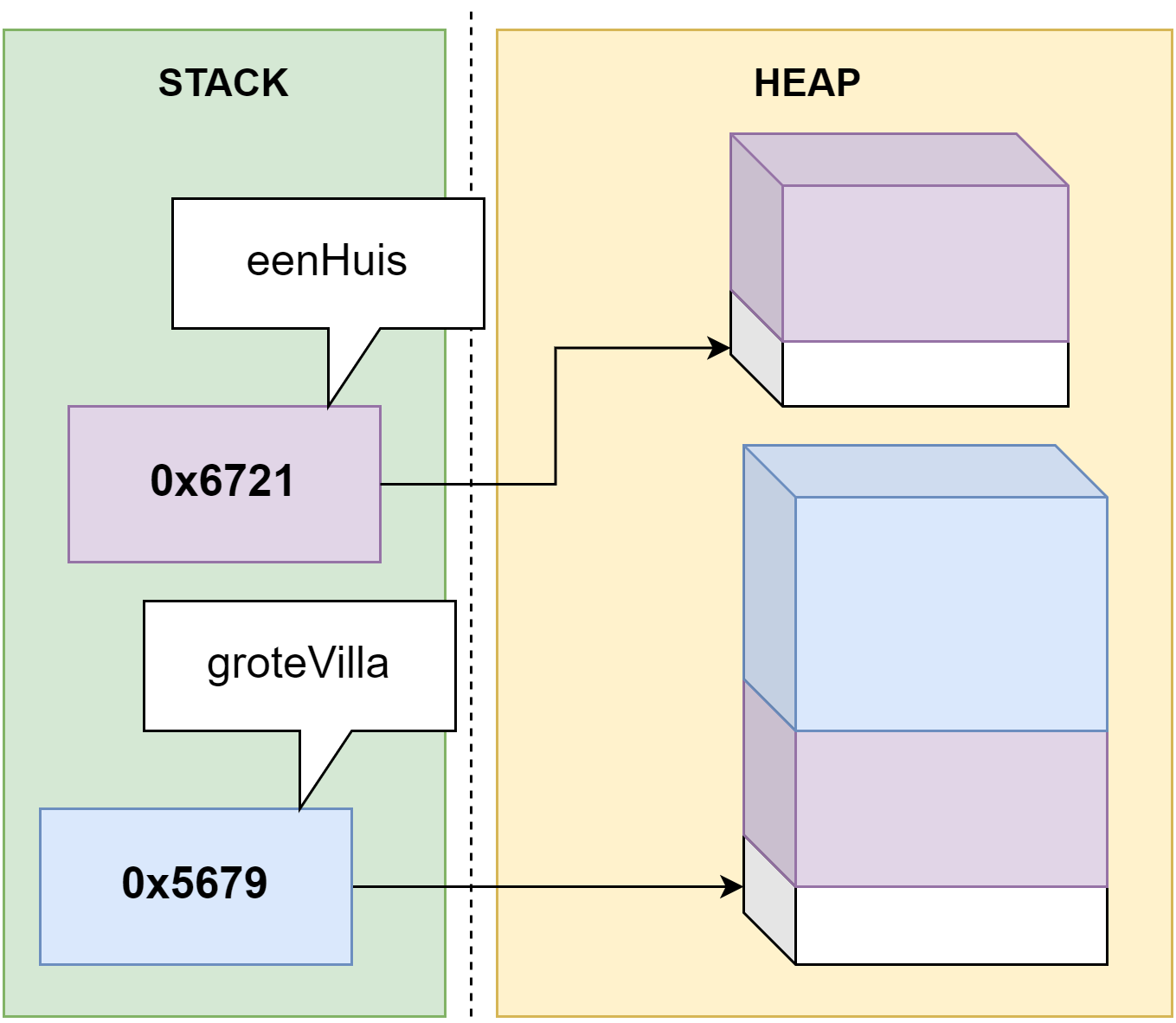


 "Ik denk dat ik een extra voorbeeldje nodig ga hebben."
"Ik denk dat ik een extra voorbeeldje nodig ga hebben."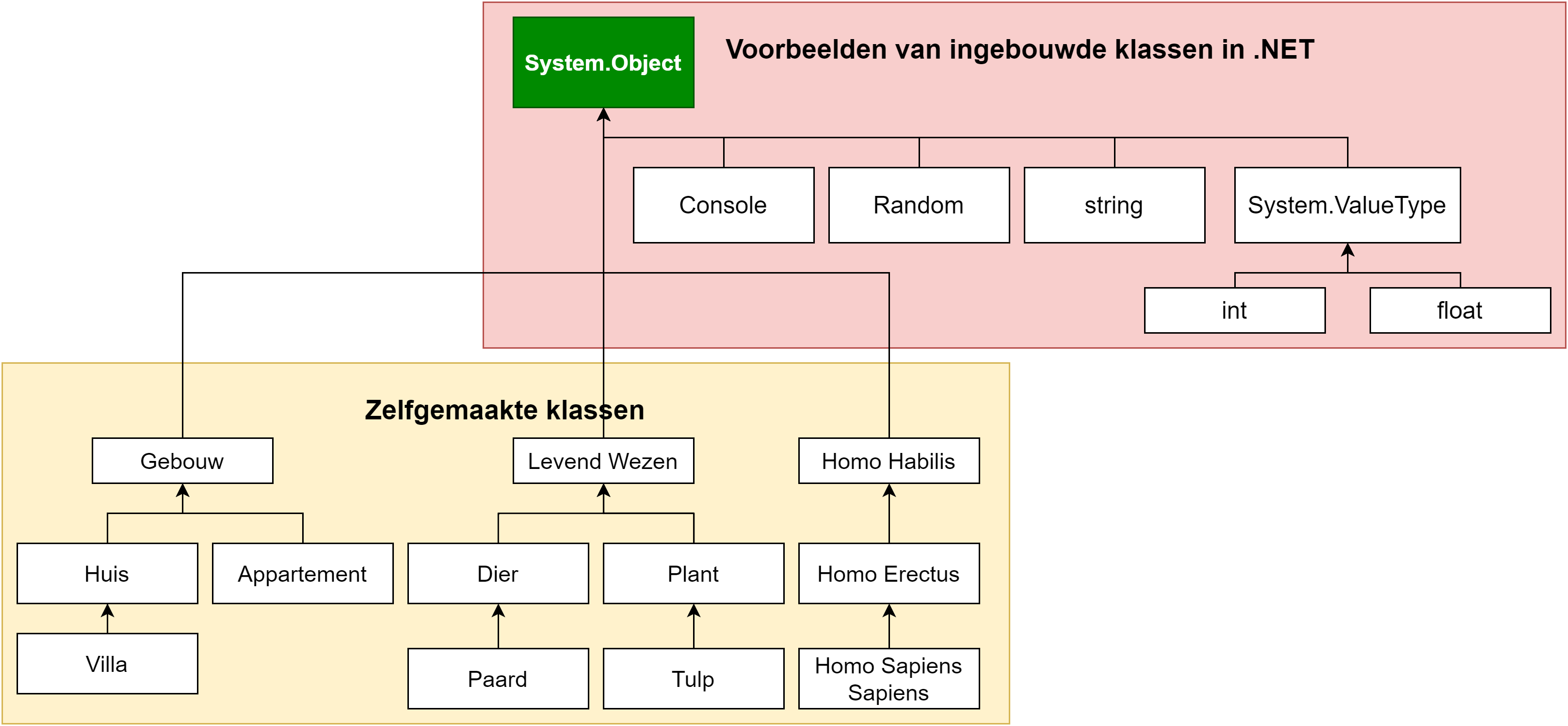
 "Ik ben nog niet helemaal mee..."
"Ik ben nog niet helemaal mee..."
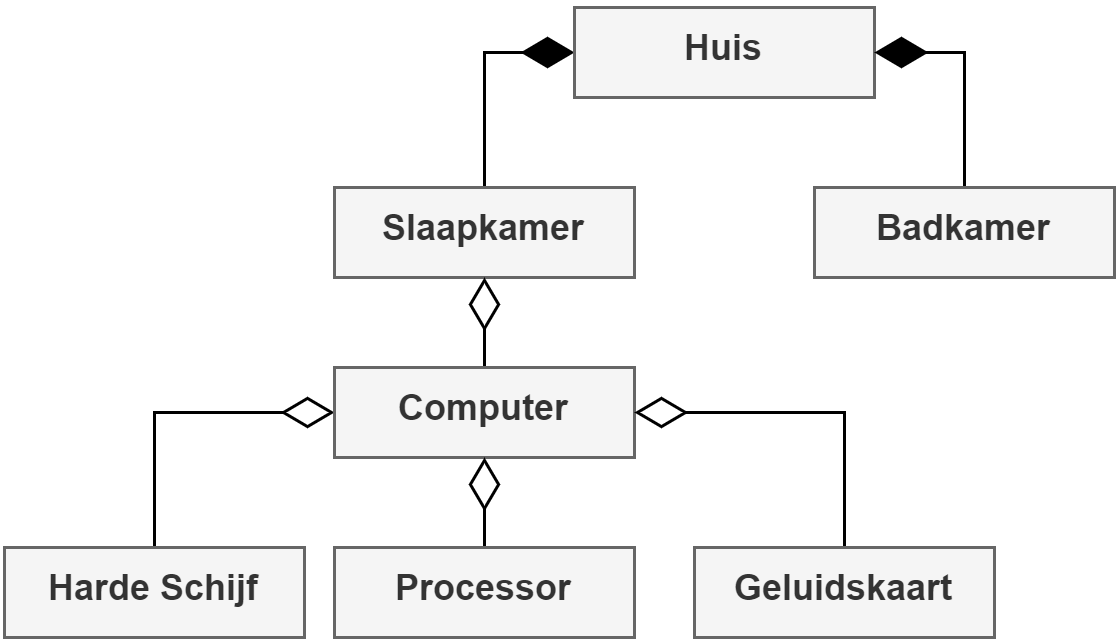
 De lijn
De lijn 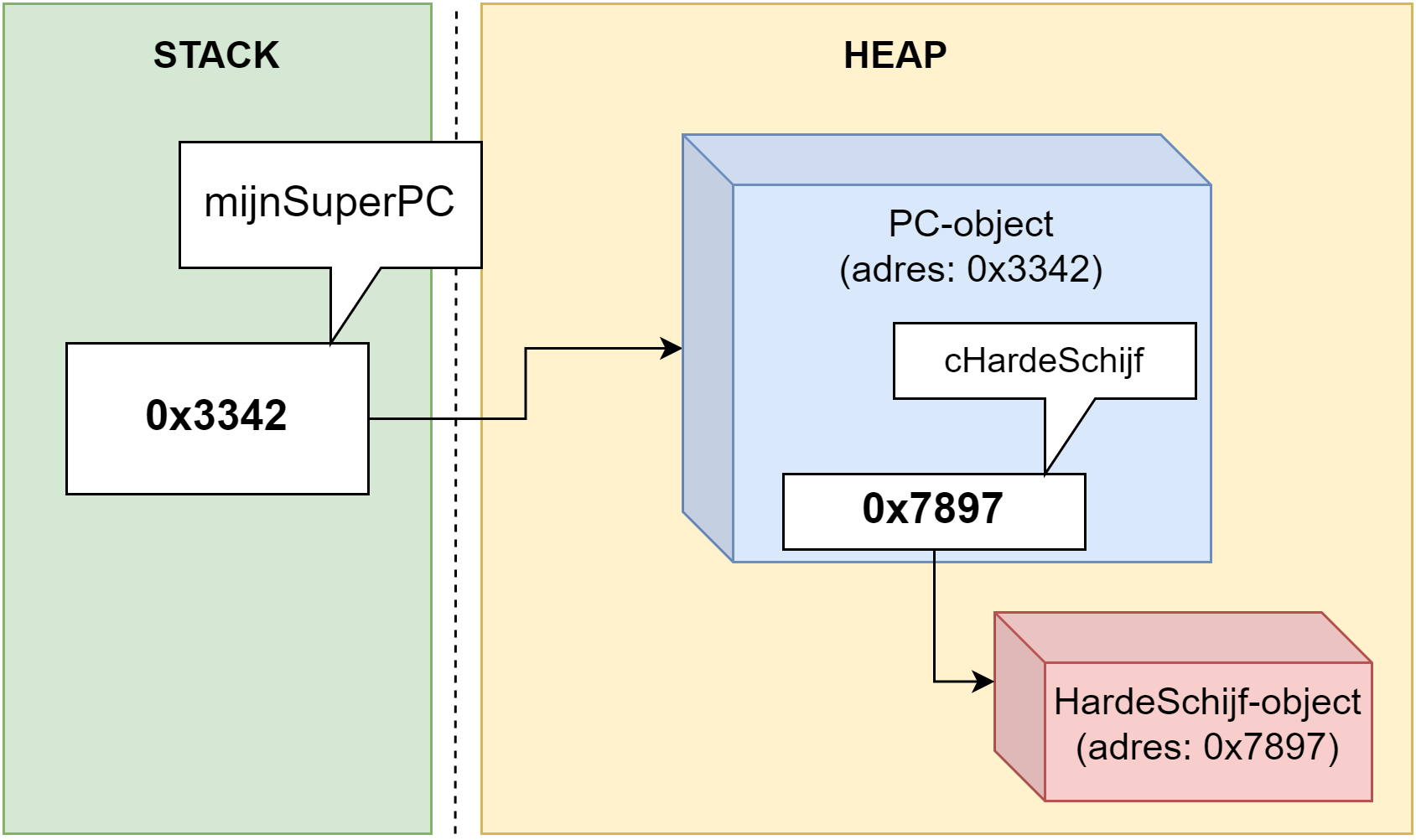
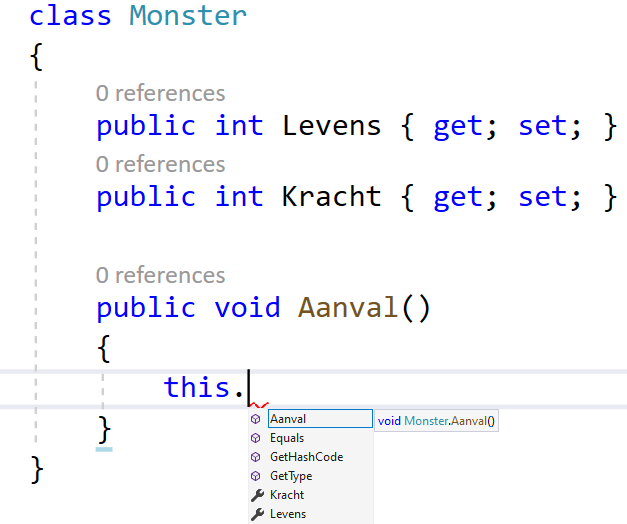
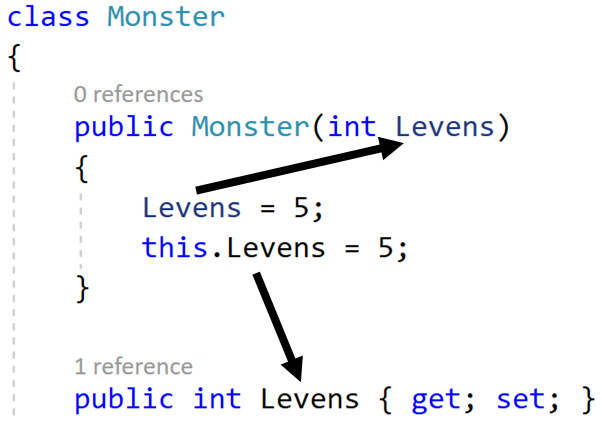
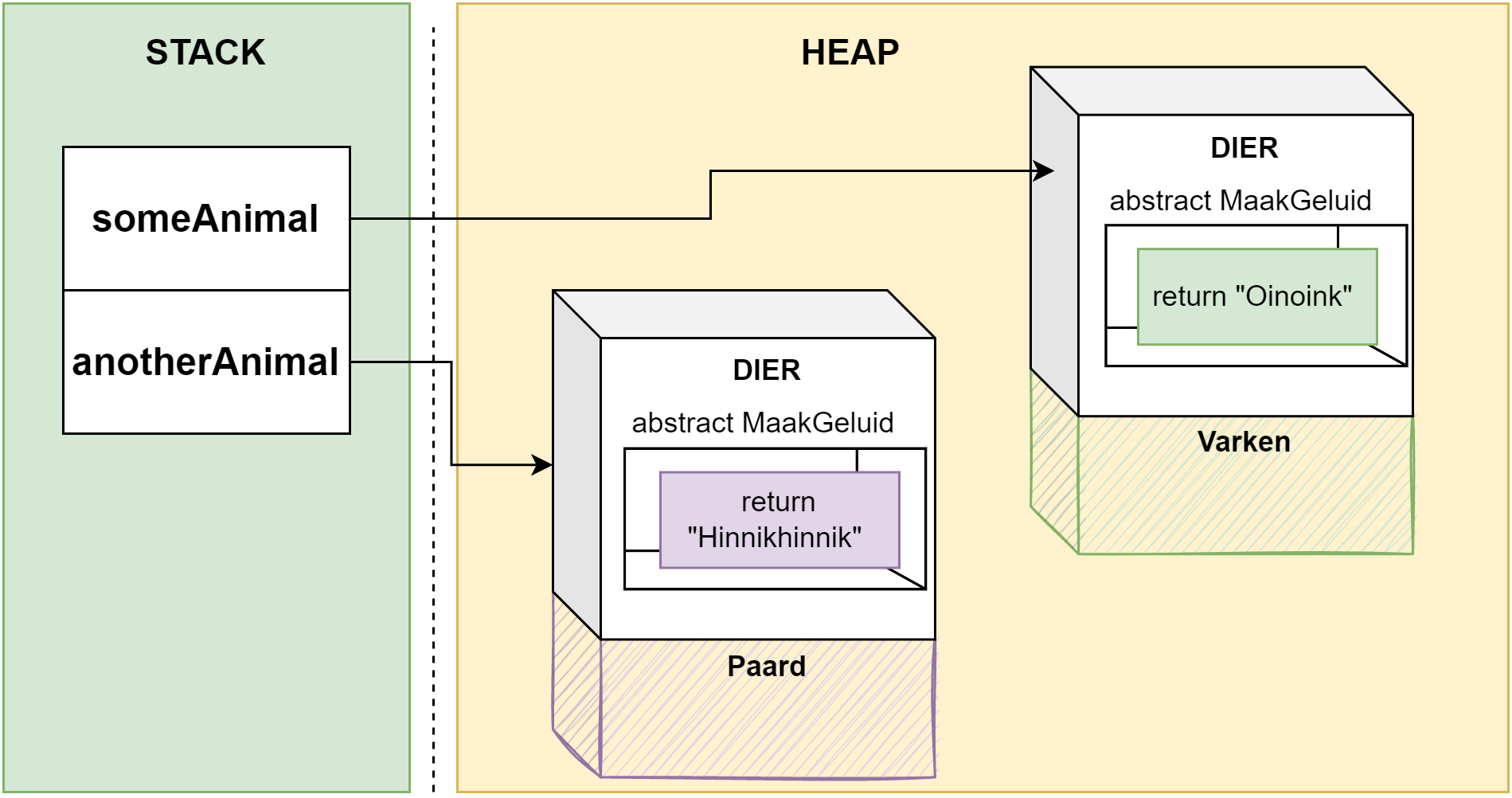
 Polymorfisme is een heel krachtig concept. Door een referentie naar een object te bewaren in een variabele van z'n basistype en, wanneer nodig, ze als 'zichzelf' te gebruiken wordt je code een pak eenvoudiger.
Polymorfisme is een heel krachtig concept. Door een referentie naar een object te bewaren in een variabele van z'n basistype en, wanneer nodig, ze als 'zichzelf' te gebruiken wordt je code een pak eenvoudiger.
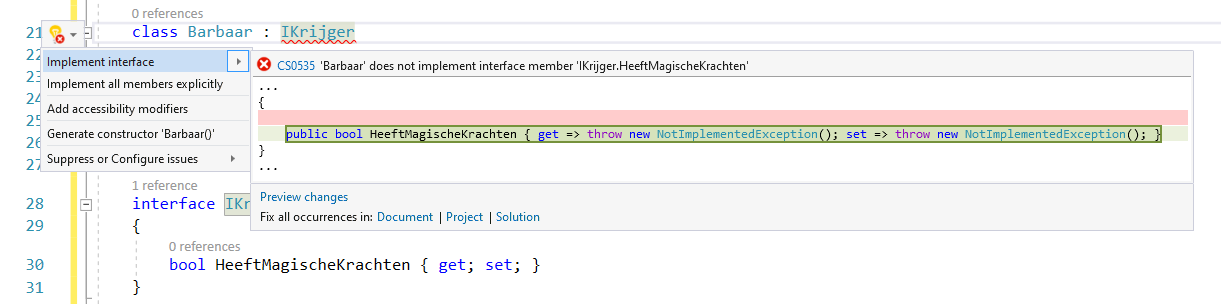
 Hopelijk hebben voorgaande voorbeelden je een beetje hebben kunnen doen proeven van de kracht van interfaces. Gedaan met ons druk te maken wat er allemaal in een klasse gebeurt. Werk gewoon 'tegen' de interfaces van een klasse en we krijgen de ultieme black-box revelatie! See what I did there?
Hopelijk hebben voorgaande voorbeelden je een beetje hebben kunnen doen proeven van de kracht van interfaces. Gedaan met ons druk te maken wat er allemaal in een klasse gebeurt. Werk gewoon 'tegen' de interfaces van een klasse en we krijgen de ultieme black-box revelatie! See what I did there?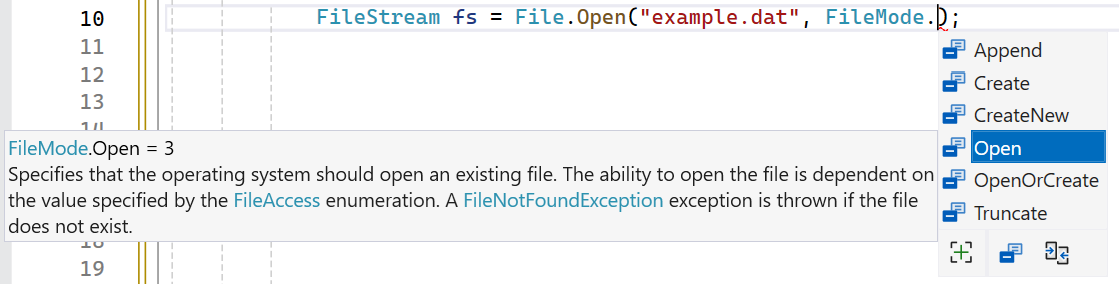



 en zoek op c#.
en zoek op c#.
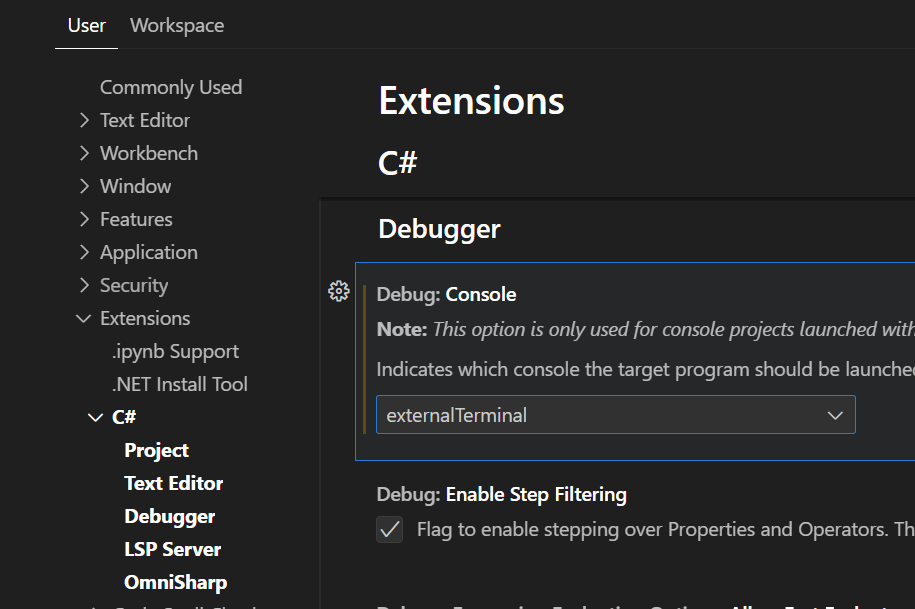




 als je geen explorer balk ziet):
als je geen explorer balk ziet):

 }
}